🎓 Eğitimler 🗃️ Blog 📜 Komut Listesi 🎯 Test 🏷️ Etiketler 💖 Faydalı Kaynaklar 🐧 Hakkında 📮 Geri Bildirim
Mobil Uygulamalar


Linux Dersleri |
GNU/Linux için Türkçe içerik sağlamak üzere kurulmuş bir platformdur.
GNU/Linux için Türkçe içerik sağlamak üzere kurulmuş bir platformdur.
Şimdiye kadar sistem üzerindeki yapıların dosya olarak ele alındığından ve dolayısıyla dosya içeriklerini yani baytları istediğimiz gibi manipüle edilip yönlendirebilmenin neden çok önemli olduğundan pek çok kez söz ettik. Her şeyin aslında bir bayt akışı olduğunu vurguladık hep. Vurgulamaya da devam edeceğiz. Özetle sistemi komut satırı üzerinden yöneten kişi olarak bizim işimiz gücümüz hep bayt akışlarını kontrol etmek.
Şimdiye kadarki anlatımlarımızda dosya içeriklerinde birtakım değişiklikler yapabileceğimiz bazı araçları tanıdık. Başka araçlardan da bahsedeceğiz ancak devam etmeden önce birden fazla aracı birbirine bağlayarak çalıştırmamıza yardımcı olan “pipe” yani “boru” mekanizmasından bahsetmem gerekiyor.
Yönlendirme işlemleri sırasında girdileri ve çıktıları istediğimiz şekilde nasıl aktarabileceğimizi öğrendik. Sizlerin de bildiği üzere yönlendirme sırasında bir aracın çıktıları bir dosyaya veya bir dosyadaki verileri de bir araca girdi olarak aktarabiliyoruz.
Pipe yapısına ihtiyaç duymamızdaki en temel iki sebep; hızlı çalışması ve aynı anda paralel şekilde işlemler arasında aktarım yapılabilmesi.
Burada bahsi geçen pipe mekanizmasını dik çizgi | operatörü sayesinde kullanabiliyoruz. Pipe mekanizmasında, bu dik çizgi işaretinden önceki komutun çıktıları üretildikleri sıralamaya uygun şekilde bu çizgiden sonraki komuta girdi olarak aktarılıyor.
Yani veriler, ilk işlemin ürettiği sıraya uygun şekilde tek yönlü olarak bir sonraki işleme aktarılıyor. Daha iyi anlamak adına çalışma yapısına daha yakından bakalım.
Basit bir örnek üzerinden gidecek olursak; Diyelim ki ben find komutu ile /etc dizini altında sonu “.sh” uzantısıyla biten dosyaları araştırmak, bulunan dosyaları isimlerine göre alfanümerik olarak sıralamak ve daha sonra numaralandırmak istiyorum. Bu işi yapacak tek bir araç var mı varsa da hangi seçenekleri kullanmalıyım tam olarak bilmiyorum. Ancak her birini yapan ayrı ayrı üç araç biliyorum. find sort ve nl araçları ilk aklıma gelenler. Sizin şu anda find aracını bilmediğinizin farkındayım, ancak merak etmeyin ileride bu aracımızı da ayrıca ele alacağız. Şimdi pipe yapısının çalışma mekanizmasını ele alabilmek için vereceğim örneğe odaklanmanız yeterli. Neticede ihtiyacım olan sonuca ulaşabilmek için bu üç aracı bir arada kullanabilirim.
Öncelikle sonu “.sh” uzantısı ile biten dosyaların bulunabilmesi için find /etc -name *.sh -type f komutunu giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ find /etc/ -name "*.sh" -type f
/etc/init.d/keyboard-setup.sh
/etc/init.d/hwclock.sh
/etc/init.d/console-setup.sh
find: ‘/etc/ipsec.d/private’: Permission denied
find: ‘/etc/vpnc’: Permission denied
/etc/wpa_supplicant/functions.sh
/etc/wpa_supplicant/action_wpa.sh
/etc/wpa_supplicant/ifupdown.sh
/etc/macchanger/ifupdown.sh
/etc/xdg/plasma-workspace/env/taylan-themes.sh
find: ‘/etc/ssl/private’: Permission denied
/etc/profile.d/gawk.sh
/etc/profile.d/taylan.sh
/etc/profile.d/dotnet-cli-tools-bin-path.sh
/etc/profile.d/vte-2.91.sh
/etc/profile.d/bash_completion.sh
/etc/console-setup/cached_setup_terminal.sh
/etc/console-setup/cached_setup_keyboard.sh
/etc/console-setup/cached_setup_font.sh
find: ‘/etc/polkit-1/localauthority’: Permission denied
Bakın “/etc” dizini altında dosya ismi “.sh” ile biten tüm dosyalar listelenmiş oldu. Hatta daha temiz bir çıktı almak istersek, yetki hatalarını “/dev/null” dosyası aracılığı ile yok edebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ find /etc/ -name "*.sh" -type f 2>/dev/null
/etc/init.d/keyboard-setup.sh
/etc/init.d/hwclock.sh
/etc/init.d/console-setup.sh
/etc/wpa_supplicant/functions.sh
/etc/wpa_supplicant/action_wpa.sh
/etc/wpa_supplicant/ifupdown.sh
/etc/macchanger/ifupdown.sh
/etc/xdg/plasma-workspace/env/taylan-themes.sh
/etc/profile.d/gawk.sh
/etc/profile.d/taylan.sh
/etc/profile.d/dotnet-cli-tools-bin-path.sh
/etc/profile.d/vte-2.91.sh
/etc/profile.d/bash_completion.sh
/etc/console-setup/cached_setup_terminal.sh
/etc/console-setup/cached_setup_keyboard.sh
/etc/console-setup/cached_setup_font.sh
Şimdi bu çıktıları alfabetik olarak sıralamak istediğim için sort aracına aktarmam gerekiyor. Aktarmak için pipe kullanabilirim. Pipe çubuk | simgesi ile kullanılıyor.
┌──(taylan@linuxdersleri)-[~]
└─$ find /etc/ -name "*.sh" -type f 2>/dev/null | sort
/etc/console-setup/cached_setup_font.sh
/etc/console-setup/cached_setup_keyboard.sh
/etc/console-setup/cached_setup_terminal.sh
/etc/init.d/console-setup.sh
/etc/init.d/hwclock.sh
/etc/init.d/keyboard-setup.sh
/etc/macchanger/ifupdown.sh
/etc/profile.d/bash_completion.sh
/etc/profile.d/dotnet-cli-tools-bin-path.sh
/etc/profile.d/gawk.sh
/etc/profile.d/taylan.sh
/etc/profile.d/vte-2.91.sh
/etc/wpa_supplicant/action_wpa.sh
/etc/wpa_supplicant/functions.sh
/etc/wpa_supplicant/ifupdown.sh
/etc/xdg/plasma-workspace/env/taylan-themes.sh
Bakın find aracının üretmiş olduğu çıktılar sort aracına aktarılıp sort aracının sıralama yapıp sonuçlarını konsola yönlendirmesi ile sonuçlanmış oldu. Sıralama işleminden sonra da, sıralanmış çıktıları numaralandırmak için de sort aracının çıktılarını nl aracına aktarabilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ find /etc/ -name "*.sh" -type f 2>/dev/null | sort | nl
1 /etc/console-setup/cached_setup_font.sh
2 /etc/console-setup/cached_setup_keyboard.sh
3 /etc/console-setup/cached_setup_terminal.sh
4 /etc/init.d/console-setup.sh
5 /etc/init.d/hwclock.sh
6 /etc/init.d/keyboard-setup.sh
7 /etc/macchanger/ifupdown.sh
8 /etc/profile.d/bash_completion.sh
9 /etc/profile.d/dotnet-cli-tools-bin-path.sh
10 /etc/profile.d/gawk.sh
11 /etc/profile.d/taylan.sh
12 /etc/profile.d/vte-2.91.sh
13 /etc/wpa_supplicant/action_wpa.sh
14 /etc/wpa_supplicant/functions.sh
15 /etc/wpa_supplicant/ifupdown.sh
16 /etc/xdg/plasma-workspace/env/taylan-themes.sh
Neticede gördüğünüz gibi tam olarak istediğim işlevi yerine getirmek için birden fazla aracı pipe ile birbirine bağlamış oldum.
Peki bu çıktıyı tam olarak nasıl elde ettik yani pipe tam olarak nasıl çalışıyor ?
Bizim girdiğimiz komutta bulunan üç farklı araç aynı anda üç ayrı işlem olarak başlatıldı. İlk aracın standart çıktısı ikinci aracın standart girdisine bağlandı. İkinci aracın standart çıktısı da üçüncü aracın standart girdisine bağlandı. Üçüncüsü de özellikle başka bir yere yönlendirilmediği için çıktılarını konsola(/dev/tty olarak temsil edildi) bastırmış oldu.
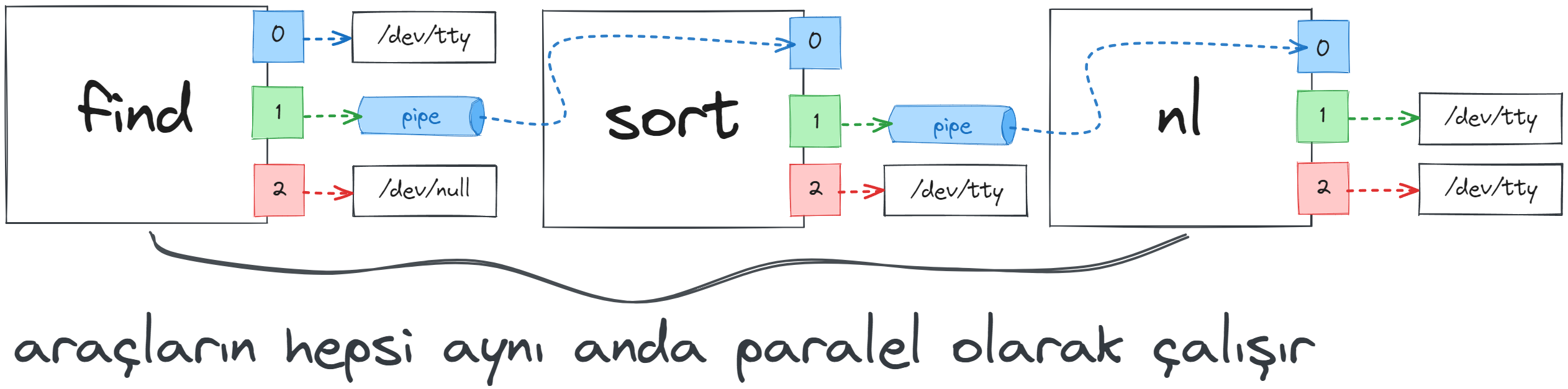
Elbette bu işlemi her bir komutun çıktılarını bir dosyaya aktarıp ilgili dosyadan diğer araçların verileri okumasını sağlayarak da yapabilirdik fakat bu komutu yazmak hem daha uğraştırıcı olacaktı hem de araçlarımız pipe kullanımına oranla daha verimsiz çalışacaktı. Hemen bu durumu gözlemleyelim.
Aynı işlemi bu kez dosyalara yönlendirme ile deneyelim. Öncelikle komutu yazalım, daha sonra açıklayacağım.
┌──(taylan@linuxdersleri)-[~]
└─$ find /etc/ -name "*.sh" -type f 2> /dev/null > bul ; sort < bul > sırala ; nl < sırala
1 /etc/console-setup/cached_setup_font.sh
2 /etc/console-setup/cached_setup_keyboard.sh
3 /etc/console-setup/cached_setup_terminal.sh
4 /etc/init.d/console-setup.sh
5 /etc/init.d/hwclock.sh
6 /etc/init.d/keyboard-setup.sh
7 /etc/macchanger/ifupdown.sh
8 /etc/profile.d/bash_completion.sh
9 /etc/profile.d/dotnet-cli-tools-bin-path.sh
10 /etc/profile.d/gawk.sh
11 /etc/profile.d/taylan.sh
12 /etc/profile.d/vte-2.91.sh
13 /etc/wpa_supplicant/action_wpa.sh
14 /etc/wpa_supplicant/functions.sh
15 /etc/wpa_supplicant/ifupdown.sh
16 /etc/xdg/plasma-workspace/env/taylan-themes.sh
Bu girdiğimiz komutta önce find komutu çalıştırılacak ve işini tamamladığında, çıktılarını “bul” isimli dosyaya aktaracak. Daha sonra sort komutu, “bul” isimli dosyayı okuyacak ve içeriğindeki verileri sıraladıktan sonra “sırala” isimli dosyaya aktaracak. En son nl komutu “sırala” isimli dosyadaki içeriği okuyup numaralandıracak ve çıktısını konsolumuza basacak. İşte girdiğimiz komutun çalışma yapısı tam olarak bu. Komutların arasında girmiş olduğumuz noktalı virgül karakterleri tek satırda belirtmiş olduğumuz bu komutların sırasıyla çalıştırılmasını sağlıyor. İleride bu konudan da ayrıca bahsedeceğiz.
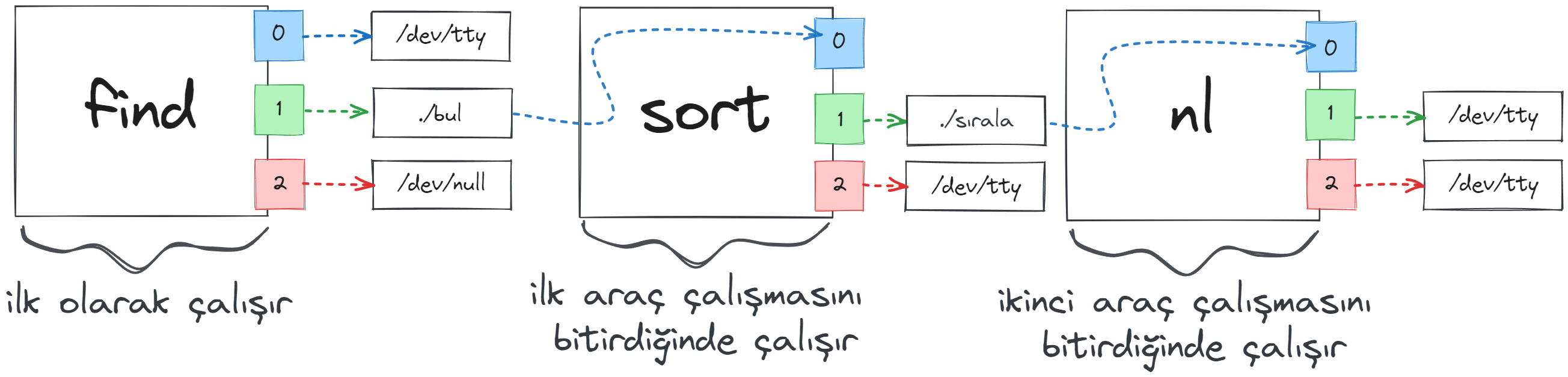
Bakın pipe yerine kullandığımız bu yönlendirme alternatifini yazması ve açıklaması dahi uzun sürdü.
Çalışma hızı ise pipe’a oranla daha yavaş olacak çünkü bu kullanımda komutlar sırasıyla tek tek ve disk üzerindeki dosyalara veri yazıp okuyarak çalıştırılıyor. Dolayısıyla soldan sağa doğru bir komut çalışmasını tamamlamadan, bir sonraki komut çalıştırılmıyor. Ve disk üzerinde okuma yazma yapıldığı için disk hızına bağlı bir çalışma hızı söz konusu.
Pipe kullanımında ise tüm komutlar ayrı işlem olarak aynı anda paralel şekilde çalıştırılıyor. Her bir aracın ürettiği çıktı da üretilir üretilmez boru hattındaki diğer işlemlere disk üzerine veri yazılıp okunmasına gerek kalmadan sanal dosya sistemi(bellek üzerinden) aktarıldığı için veriler çok daha hızlı işlenmiş oluyor. Bir komut çıktı üretir üretmez, çıktının üretilme sıralaması korunarak bir sonraki işlem aktarıyor, bu sayede tüm veriler sırasıyla işlenmiş oluyor. Tabii ki bizim örneğimizde ilk aracın ürettiği çıktıların hepsinin alındıktan sonra sıralaması gerektiği için sort aracı find aracının çıktılarını bitirmesini bekledi aslında. Yani araçlar paralel çalışıyor olsalar da çıktıların gönderilme ve okunma durumlarına bağlı olarak birbirlerini de bekleyebiliyorlar. Yine de pipe mekanizması disk üzerindeki dosyalara okuma yazma yapmadığı ve araçları paralel olarak aynı anda çalıştırabildiği için çok daha verimli bir yaklaşım. Üstelik basit örnek üzerinden de görebildiğiniz gibi birden fazla aracı birbirine bağlayarak çalıştırmak istediğimizde pipe ile komut girmek çok da daha kolay ve kısa.
Ayrıca örnek üzerinde peşi sıra pipe kullandığımız bu komutun bütününe de “pipeline” yani “boru hattı” deniyor. Neticede birden fazla pipe yani boru kullanarak ikiden fazla aracı birbirine bağladığımız için boru hattı oluşturmuş oluyoruz.
Tıpkı buradaki örneğimizde olduğu gibi ihtiyacımıza yönelik spesifik çözüm için bildiğimiz birden fazla aracın basit özelliklerini pipe yardımıyla bir arada kullanabiliyoruz. Bu yaklaşım sayesinde pek çok işlevi olan tek bir karmaşık araç yerine, basit işlevleri olan pek çok aracı farklı kombinasyonlar ile birlikte kullanıp sınırsız çeşitlilikte çözüm üretebiliyoruz. Zaten zaman içinde pipe yapısını ister istemez ne kadar sık kullandığınıza bizzat şahit olacaksınız.
xargs KomutuPipe yapısından bahsederken, pipe’ın önceki işlemden gelen standart çıktıları sonraki işleme standart girdi olarak aktardığını söylemiştim. Eğer pipe ile veri yönlendirmek istediğiniz araç yalnızca argüman alarak çalışıyorsa yani standart girdiden veri kabul etmiyorsa tabii ki ilgili veriler araç tarafından alınıp işlenmiyor. Dolayısıyla pipeline olarak ifade ettiğimiz boru hattı tıkanmış oluyor.
İşte bu duruma çözüm olarak da xargs isimli aracı kullanabiliyoruz.
xargs aracı, standart girdiden okuduğu verileri kendisinden sonraki komutun argümanı olarak iletebiliyor. Bu sayede standart girdiden veri kabul etmeyen araçları, tıpkı biz elle o araca argümanlar girmişiz gibi çalıştırabiliyoruz. xargs aracının isminin açılımı da zaten “eXtended ARGumentS” yani “genişletilmiş argümanlar” ifadesinden geliyor.
Bu aracın çok fazla seçeneği var ama şimdilik temel kullanımı hakkında bilgi sahibi olmamız yeterli.
Ben çok basit bir örnek vermek istiyorum. Bunun için öncelikle içerisinde veri bulunan dosyamı oluşturmak üzere echo “dosya1 dosya2 dosya3” > oku-beni şeklinde komutumu giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "dosya1 dosya2 dosys3" > oku-beni
┌──(taylan@linuxdersleri)-[~]
└─$ cat oku-beni
dosya1 dosya2 dosys3
Bakın buraya yazmış olduğum ifadeler dosyama kaydolmuş. Şimdi ben bu dosyada geçen ifadelerin kullanılarak yeni dosyalar oluşturulması için touch aracına bu dosyadan veri yönlendirmek istiyorum.
Bunun için cat oku-beni komutuyla dosyanın okunup pipe ile bu çıktıların touch aracına yönlendirilmesini sağlayabiliriz.
└─$ cat oku-beni | touch
touch: missing file operand
Try 'touch --help' for more information.
Gördüğünüz gibi touch komutu oluşturulacak dosya isimleri argüman olarak iletilmediği için hata verdi. Bu hatanın argüman eksikliğinden kaynaklandığını teyit etmek istersek tekrar yalnızca touch komutunu girebiliriz.
└─$ touch
touch: missing file operand
Try 'touch --help' for more information.
Bakın yine aynı hatayı aldık çünkü touch aracına herhangi bir dosya ismini argüman olarak iletmedik.
touch aracı yalnızca kendisine argüman olarak iletilen verileri işleyip standart girdiden veri okumadığı için pipe ile ilettiğimiz “oku-beni” dosyasının içeriği touch aracı tarafından işlenmedi. Bu durumda bu çıktıları önce xargs aracına yönlendirip oradan da touch aracına argüman olarak iletilmelerini sağlayabiliriz. Ben bunun için komutumu bu kez cat oku-beni | xargs touch şeklinde yazıyorum.
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ cat oku-beni | xargs touch
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ ls
dosya1 dosya2 dosys3 oku-beni
Bakın tam olarak dosyada bulunan veriler ile aynı isimde yeni dosyalar oluşturulmuş. Yani xargs aracının standart girdiden okuduğu verileri hemen yanındaki komutun argümanı olarak çalıştırdığını bizzat teyit etmiş olduk.
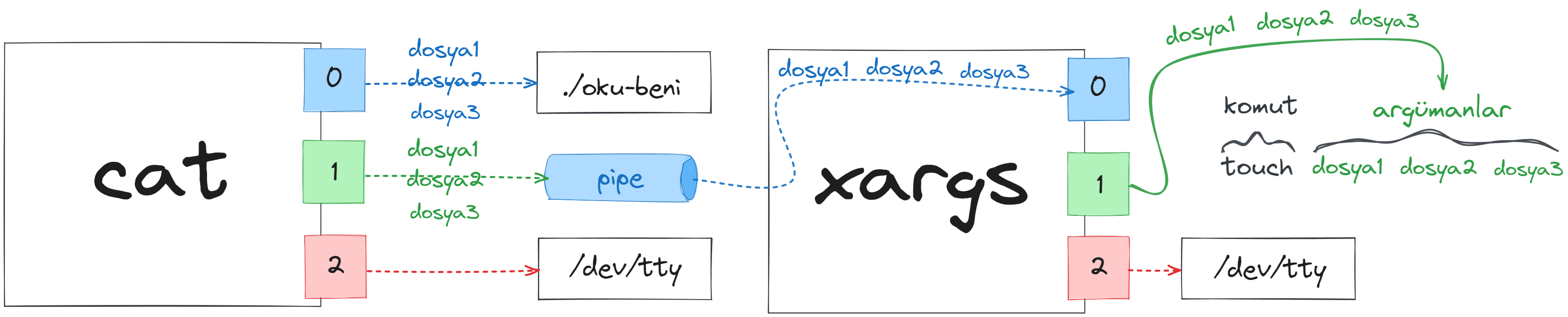
xargs aracı kendisine girdi olarak verilerin tüm verileri standart şekilde boşluklarından parçalara ayırıp bunların her birini hemen yanındaki komuta ayrı ayrı argüman olarak iletiyor. Zaten bu sebeple benim bu dosyada aralarında boşluk bırakarak yazdığım tüm verilerim argüman olarak touch aracına iletildi.
İşte bu yaklaşım sayesinde standart girdiden veri kabul etmeyen yani yalnızca argüman olarak çalışan araçlara kolaylıkla veri yönlendirmesi yapabiliyoruz. Neticede xargs aracının en temel kullanımı bu şekilde. Artık en temel kullanım amacını bildiğiniz için geri kalan tüm detaylar için yardım sayfalarına göz atmanız yeterli.
tee KomutuBiz pipe yapısını kullandığımızda verilerimiz yalnızca tek yönlü şekilde aktarılıyor. Eğer biz hem bir sonraki işleme hem de bir dosyaya aynı verilerin yazılmasını istiyorsak, bu işlem için tee aracını kullanmamız gerekiyor. Çünkü pipe mekanizması tek başına bunu desteklemiyor. Pipe mekanizmasını düz boru | olarak düşünecek olursak buradaki tee aracı da bildiğiniz T boru görevi görüyor. İlk işlemden aldığı çıktıyı okuyor, istenilen dosyaya ve aynı zamanda bir sonraki işlemin standart girdisine yönlendiriyor.
Basit bir örnek üzerinden ele alabiliriz. Örneğin ls / komutu ile “/” yani ana dizin altındaki dosyaları listeleyecek olursak uzun bir liste alırız.
┌──(taylan@linuxdersleri)-[~]
└─$ ls /
bin home lib32 media root sys vmlinuz
boot initrd.img lib64 mnt run tmp vmlinuz.old
dev initrd.img.old libx32 opt sbin usr
etc lib lost+found proc srv var
Ben uzun bir liste istemiyorum. Eğer yalnızca ilk 10 satırı listelemek istersem pipe ile verileri head komutuna aktarabilirim. Buradaki head aracı, aldığı verilerin yalnızca ilk 10 satını çıktı olarak iletildiği için kullandık. İleride bu araçtan ayrıca bahsediyor olacağız. Şimdi komutumuzu girip deneyelim.
┌──(taylan@linuxdersleri)-[~]
└─$ ls / | head
bin
boot
dev
etc
home
initrd.img
initrd.img.old
lib
lib32
lib64
Bakın yalnızca ilk 10 içerik listelenmiş oldu. Ben ls komutunun tüm çıktılarının bir dosyaya kaydedilmesini hem de head komutu ile yalnızca ilk 10 satırını okumak istiyor da olabilirim. Bunun için tee komutunu kullanabilirim. Yani komutumuzu ls / | tee liste.txt | head şeklinde yazabiliriz. Bu komut sayesinde ilk olarak ls aracı “/” dizini altındaki tüm içeriği listeleyip pipe ile tee aracına aktaracak. tee aracı da aldığı çıktıyı “liste.txt” isimlide dosyaya kaydedecek ve ayrıca aynı verileri head aracına pipe ile yönlendirecek. head aracı da aldığı verilerden yalnızca ilk 10 satırı konsola çıktı olarak bastıracak.
┌──(taylan@linuxdersleri)-[~]
└─$ ls / | tee liste.txt | head
bin
boot
dev
etc
home
initrd.img
initrd.img.old
lib
lib32
lib64
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın ilk 10 satır konsola basılmış oldu. Şimdi “liste.txt” dosyasının içeriğine bakalım.
┌──(taylan@linuxdersleri)-[~]
└─$ cat liste.txt
bin
boot
dev
etc
home
initrd.img
initrd.img.old
lib
lib32
lib64
libx32
lost+found
media
mnt
opt
proc
root
run
sbin
srv
sys
tmp
usr
var
vmlinuz
vmlinuz.old
Gördüğünüz gibi ls komutunun tüm çıktıları da bu listeye kaydedilmiş. Yani tee komutu ls komutunun çıktılarını hem dosyaya hem de bir sonraki işlem olan head işlemine iletmiş oldu. Burada fark ettiyseniz tee aracı kendisine verilen tüm verileri hem dosyaya hem de bir sonraki araca eksiksiz şekilde iletiyor. İşte tee komutu pipeline üzerinde bu amaçla sıklıkla kullanılıyor.
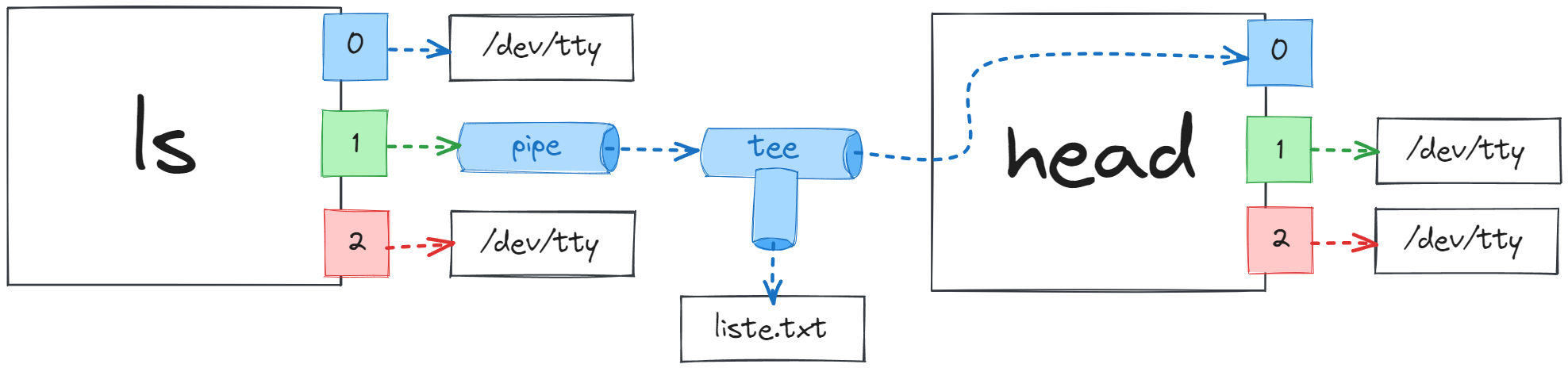
Mesela ls / | head | tee liste.txt şeklinde komut girecek olursak size nasıl bir çıktı alırız ? Hemen girip deneyelim.
┌──(taylan@linuxdersleri)-[~]
└─$ ls / | head | tee liste.txt
bin
boot
dev
etc
home
initrd.img
initrd.img.old
lib
lib32
lib64
┌──(taylan@linuxdersleri)-[~]
└─$ cat liste.txt
bin
boot
dev
etc
home
initrd.img
initrd.img.old
lib
lib32
lib64
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın ls / komutunun çıktıları pipe ile head aracına iletildi. head aracı da ilk 10 satırı alıp tee aracına iletti. tee aracı da kendisine iletilen bu 10 satırı hem “liste.txt” dosyasına hem de konsola yönlendirdi. Bu sebeple hem konsol çıktısında hem de “liste.txt” dosyasında ilk 10 satırı almış olduk.
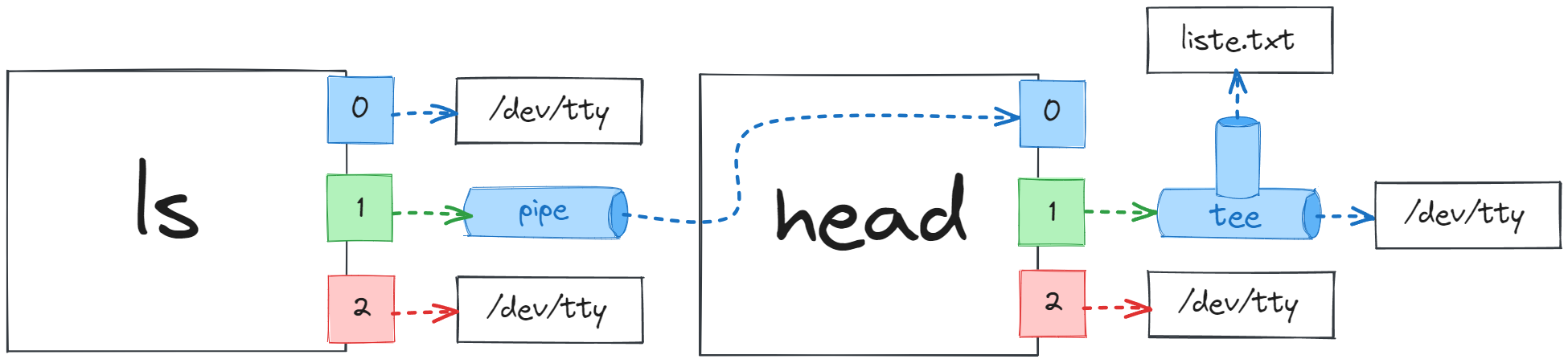
Bence buradaki iki örnek tee aracının nasıl çalıştığını gayet iyi biçimde özetliyor.
Bu temel yaklaşım dışında, birden fazla dosyaya aynı veriyi kaydetmek isterseniz, dosyaların isimlerini argüman olarak vermeniz yeterli. Ben denemek için aynı komutu çağırıp, bir dosya ismi daha belirtiyorum ve komutumu bu şekilde onaylıyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ ls / | head | tee liste.txt liste2.txt
bin
boot
dev
etc
home
initrd.img
initrd.img.old
lib
lib32
lib64
Şimdi paste komutu ile her iki dosyayı da yan yana bastırabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ paste liste.txt liste2.txt
bin bin
boot boot
dev dev
etc etc
home home
initrd.img initrd.img
initrd.img.old initrd.img.old
lib lib
lib32 lib32
lib64 lib64
Gördüğünüz gibi aynı verileri birden fazla dosyaya da yönlendirebiliyoruz.
tee yaklaşımı sayesinde dilersek standart(< > &> vs..) yönlendirmelerin alternatifi olarak, yönlendirmelerin hem konsola hem de dosyalara kaydolmasını da sağlayabiliriz. Normalde sizin de bildiğiniz gibi eğer bir komutun çıktısını bir dosyaya yönlendirirsek konsola bir çıktı basılmaz. Hemen teyit etmek için ls > liste şeklinde komutumuzu girelim.
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ ls > liste
┌──(taylan@linuxdersleri)-[~/klasor]
└─$
Bakın ls komutunun çıktısı konsola basılmadı çünkü ls komutunun çıktıları belirttiğim dosyaya yönlendirildi. cat komutu ile de bu durumu teyit edebiliriz.
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ cat liste
dosya1
dosya2
dosys3
liste
oku-beni
Şimdi aynı örneği tee komutunu ile tekrarlayalım. ls | tee liste2 şeklinde komutumu giriyorum.
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ ls | tee liste2
dosya1
dosya2
dosys3
liste
liste2
oku-beni
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ cat liste2
dosya1
dosya2
dosys3
liste
liste2
oku-beni
Bakın tee aracı sayesinde ls komutunun çıktıları konsola bastırılmakla birlikte dosyaya da kaydedilmiş. Eğer ben tee aracından sonra bir pipe daha kullanıp bir araç ismi yazsaydım tee aracının elindeki veriler bu araca yönlendirilecekti. Fakat tee aracından sonra bir araç ismi girmediğim için tee aracı elindeki verileri dosyaya yazmasının yanı sıra standart çıktı adresi olan konsola da bastırmış oldu.
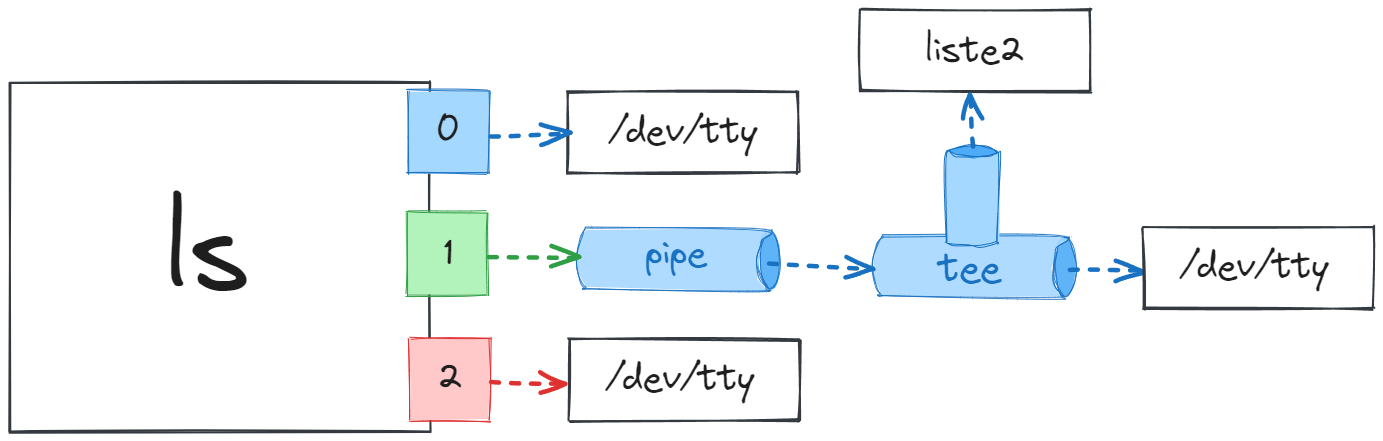
tee aracının kullanımı gördüğünüz gibi son derece kolay olduğu için daha fazla örneğe gerek yok. Yine de son olarak birkaç kullanım detayını daha bilmenizde fayda var.
Normalde tee komutu aynı isimde bir dosya varsa onun üzerine yazar. Yani o dosyanın içeriğini yok edip, elindeki verileri o dosyaya yazar. Eğer aynı isimli dosya varsa dosya içeriğinin sonuna yeni verilerin eklenmesini istersek “append” yani “ekleme” ifadesinin kısaltması olan a seçeneğini kullanabiliriz.
Ben denemek için echo "deneme" | tee deneme.txt komutunu giriyorum.
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ echo "deneme" | tee deneme.txt
deneme
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ cat deneme.txt
deneme
Bakın veri kaydolmuş. Şimdi aynı dosyaya bu kez farklı veri göndermek için echo “test” | tee deneme.txt şeklinde aynı dosyanın ismini de yazıp komutumuzu girelim.
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ echo "test" | tee deneme.txt
test
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ cat deneme.txt
test
Bakın dosyanın eski içeriği silinip tee aracının en son yönlendirdiği veri eklenmiş. Bizzat gördüğümüz gibi tee aracına özellikle belirtmediğimiz sürece tıpkı tek yönlendirme > operatörü kullandığımızdaki gibi hedefteki dosya içeriğinin üzerine yazılıyor.
Ben verileri dosyanın sonuna eklemek istediğim için “append” yani “ekleme” ifadesinin kısaltmasından gelen a seçeneği ile komutumu tekrar girmek istiyorum.
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ echo "test2" | tee -a deneme.txt
test2
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ cat deneme.txt
test
test2
Bakın tee aracın echo aracından “test2” ifadesini aldığı için bunu konsola bastırdı. Ayrıca tee aracına a seçeneğini de eklediğimiz için bu veriyi “deneme.txt” dosyasının sonuna ekliyor. Kısacası tıpkı yönlendirme operatörlerinde bir dosyanın sonuna yeni veri eklemek için çift operatör >> kullandığımız gibi tee komutu için de a seçeneğini kullanmamız gerekiyor. Aksi halde tee aracı aynı isimli dosyanın üzerine yeni verileri yazıp eskilerini yok ediyor.
Son olarak hazır tee komutundan bahsetmişken pratik bir kullanımından da bahsetmek istiyorum. Diyelim ki yetkimiz olmayan bir dosyaya örneğin /etc/apt/sources.list dosyasına ekleme yapmak istiyoruz.
Normalde yetki gerektiren bir görevi yerine getirmek için komutumuzun en başına sudo ifadesini yazıp eğer yetkimiz uygunsa çalıştırabiliyoruz. Normalde /etc/apt/sources.list dosyasını düzenlemek için yetkimiz yok fakat en yetkili kullanıcı gibi davranmak için komutumuzun başına sudo yazı işlemi yerine getirmeyi deneyebiliriz.
Yani örneğin sudo echo "eklenecek veri" >> /etc/apt/sources.list şeklinde komutumuzu girebiliriz.
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ sudo echo "eklenecek veri" >> /etc/apt/sources.list
bash: /etc/apt/sources.list: Permission denied
Ancak gördüğünüz gibi yetki hatası aldık. Halbuki ileri de ayrıca ele alacağımız sudo komutu bizim yetkili şekilde bu dosyaya veri ekleyebilmemizi sağlamalıydı.
Burada sudo komutu işe yaramadı çünkü yönlendirmeler üzerinde sudo komutunun etkisi bulunmuyor. Yani yönlendirmeyi yine mevcut yetkisiz kullanıcımız yapmış oluyor. Dolayısıyla sudo komutunu kullansak dahi yönlendirme operatörü ile, ilgili dosyaya veri yazma yetkisi kazanamayız. Fakat bunun yerine tee komutunu sudo ile yetkili şekilde çalıştırabiliriz. Hadi hemen deneyelim. Ben echo "####" | sudo tee -a /etc/apt/sources.list şeklinde komutumu yazıyorum. Buradaki a seçeneğini unutmayın aksi halde bu çok önemli dosyasının tüm içeriğinin silinmesine neden olabilirsiniz.
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ echo "####" | sudo tee -a /etc/apt/sources.list
[sudo] password for taylan:
yeni satır
Ve gördüğünüz gibi parolamızı girip komutu onayladığımızda herhangi bir yetki hatası almıyoruz. cat komutuyla dosya içeriğine de bakalım.
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ cat /etc/apt/sources.list
# See https://www.taylan.org/docs/general-use/taylan-linux-sources-list-repositories/
deb http://http.taylan.org/taylan taylan-rolling main contrib non-free
# Additional line for source packages
# deb-src http://http.taylan.org/taylan taylan-rolling main contrib non-free
yeni satır
Bakın dosyanın en sonuna “####” ifadesi eklenmiş.
❗Dikkat: Düzenleme yaptığımız dosya önemli bir konfigürasyon dosyası olduğu için dosya yapısını bozmamak adına yalnızca “####” ifadesini ekledim. Eğer siz farkı bir veri eklerseniz sistemi güncelleme ve paket yükleme noktasında sorunlar yaşayabilirsiniz. Bu sebeple “#” hariç bir karakter eklemeyin veya eklediyseniz de sudo nano /etc/apt/sources.list komutu ile dosyayı açıp ilgili satırı silin ve Ctrl + x ile dosyayı kaydedip kapatın.
Böylelikle yönlendirme operatörlerinin sudo ile yetki kazanamadığından ve alternatif olarak tee komutu sayesinde yetkili şekilde dosya içeriğine veri yönlendirebileceğimizden de haberdar olduk. Ele aldığımız örnekleri de dikkate aldığımızda tee aracını tıpkı T boru gibi düşünmek bence oldukça mantıklı. Konsol üzerinde hem standart çıktıya hem de bir dosyaya yönlendirme yapmak istediğinizde veya bir yönlendirme işlemini yetkili şekilde yapmak istediğinizde tee aracını kullanabiliyoruz. Mesela ben en son girmiş olduğum komutta konsola çıktı bastırılmadan yalnızca dosyaya veri yönlendirmek isteseydim standart çıktıları /dev/null dizinine de yönlendirebilirdim. Ben denemek için en son komutumu çağırıp bu kez sonuna > /dev/null şeklinde yazıyorum ve komutumu bu şekilde onaylıyorum.
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ echo "####" | sudo tee -a /etc/apt/sources.list > /dev/null
┌──(taylan@linuxdersleri)-[~/klasor]
└─$ cat /etc/apt/sources.list
# See https://www.taylan.org/docs/general-use/taylan-linux-sources-list-repositories/
deb http://http.taylan.org/taylan taylan-rolling main contrib non-free
# Additional line for source packages
# deb-src http://http.taylan.org/taylan taylan-rolling main contrib non-free
####
####
Bakın konsola herhangi bir çıktı bastırılmadı çünkü standart çıktıyı /dev/null dosyasına yönlendirerek yok etmiş oldum. Siz de bu şekilde pipe üzerinden gelen verileri bir dosyaya yazmak istediğinizde bu yaklaşımı kullanabilirsiniz.
❗Dikkat: Örneklerimiz sırasında kullandığımız bu /etc/apt/sources.list dosyası, sistemin paket yönetimi için önemli bir dosya. O sebeple sudo nano /etc/apt/sources.list ile bu dosyayı tekrar açıp, eklediğiniz gereksiz verileri silmenizi öneriyorum. Aksi halde paket yönetimi konusunda sorun yaşayabilirsiniz.
grep Komutugrep aracının ismi “global regular expression print” ifadesinin kısaltmasından geliyor. Ve tam olarak isminde de olduğu şekilde “regex” sayesinde verileri filtreleme konusunda çok yetenekli bir araç.
grep aracı standart girdiden veya kendisine argüman olarak verilmiş olan dosyadan veri okuyup filtreleyebiliyor. Hemen bizzat görmek için en temel kullanımıyla başlayabiliriz.
Ben denemek için /etc/passwd dosyasında kaç kez “false” ifadesinin geçtiğini öğrenmek üzere grep komutundan sonra araştırmak istediğim kelimeyi ve daha sonra da hangi dosyada araştırılacağını grep "false" /etc/passwd şeklinde giriyorum.

Bakın içerisinde “false” ifadesi bulunan tüm satırlar listelendi. Benzer şekilde aslında standart girdiden alınan veriler de grep tarafından işlendiği için komutumuzu cat /etc/passwd | grep false şeklinde de girebilirdik.

Bakın yine aynı sonucu elde ettik çünkü cat aracı /etc/passwd dosyasının içeriğini pipe ile grep aracına aktardı, grep de benim istediğim doğrultusunda içinde “false” ifadesi geçen satıları filtreleyip standart çıktıya yani konsola yönlendirdi. İşte grep aracının en temel kullanımı bu şekilde. İster dosyadan isterseniz de standart girdiden grep aracına veri yönlendirip verilerin okunmasını sağlayabilirsiniz.
Şimdi ben grep aracının birkaç farklı kullanım özelliğinden daha bahsetmek istiyorum.
Aradığımız kelime ile eşleşen verileri nasıl filtreleyebileceğimizi ele aldık. Eğer tersi şekilde aradığımız ifadenin geçmediği bölümleri istersek bulun için grep aracının hariç tutma özelliğini kullanabiliriz. Hariç tutma özelliğini kullanmak için de kısaca v seçeneğini kullanabiliyoruz.
Yani örneğin ben /etc/passwd dosyasının içinde “false” ifadesinin geçmediği satırları listelemek istersem grep -v "false" /etc/passwd şeklinde komutumu girebilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ grep -v "false" /etc/passwd
root:x:0:0:root:/root:/usr/bin/zsh
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
uucp:x:10:10:uucp:/var/spool/uucp:/usr/sbin/nologin
proxy:x:13:13:proxy:/bin:/usr/sbin/nologin
www-data:x:33:33:www-data:/var/www:/usr/sbin/nologin
backup:x:34:34:backup:/var/backups:/usr/sbin/nologin
list:x:38:38:Mailing List Manager:/var/list:/usr/sbin/nologin
irc:x:39:39:ircd:/run/ircd:/usr/sbin/nologin
gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats:/usr/sbin/nologin
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
systemd-network:x:100:102:systemd Network Management,,,:/run/systemd:/usr/sbin/nologin
systemd-resolve:x:101:103:systemd Resolver,,,:/run/systemd:/usr/sbin/nologin
_apt:x:102:65534::/nonexistent:/usr/sbin/nologin
strongswan:x:105:65534::/var/lib/strongswan:/usr/sbin/nologin
systemd-timesync:x:106:112:systemd Time Synchronization,,,:/run/systemd:/usr/sbin/nologin
redsocks:x:107:113::/var/run/redsocks:/usr/sbin/nologin
rwhod:x:108:65534::/var/spool/rwho:/usr/sbin/nologin
iodine:x:109:65534::/run/iodine:/usr/sbin/nologin
messagebus:x:110:114::/nonexistent:/usr/sbin/nologin
miredo:x:111:65534::/var/run/miredo:/usr/sbin/nologin
_rpc:x:112:65534::/run/rpcbind:/usr/sbin/nologin
usbmux:x:113:46:usbmux daemon,,,:/var/lib/usbmux:/usr/sbin/nologin
tcpdump:x:114:120::/nonexistent:/usr/sbin/nologin
rtkit:x:115:121:RealtimeKit,,,:/proc:/usr/sbin/nologin
sshd:x:116:65534::/run/sshd:/usr/sbin/nologin
dnsmasq:x:117:65534:dnsmasq,,,:/var/lib/misc:/usr/sbin/nologin
statd:x:118:65534::/var/lib/nfs:/usr/sbin/nologin
avahi:x:119:125:Avahi mDNS daemon,,,:/run/avahi-daemon:/usr/sbin/nologin
nm-openvpn:x:120:126:NetworkManager OpenVPN,,,:/var/lib/openvpn/chroot:/usr/sbin/nologin
stunnel4:x:121:127::/var/run/stunnel4:/usr/sbin/nologin
nm-openconnect:x:122:128:NetworkManager OpenConnect plugin,,,:/var/lib/NetworkManager:/usr/sbin/nologin
sslh:x:125:130::/nonexistent:/usr/sbin/nologin
postgres:x:126:131:PostgreSQL administrator,,,:/var/lib/postgresql:/bin/bash
pulse:x:127:132:PulseAudio daemon,,,:/run/pulse:/usr/sbin/nologin
saned:x:128:135::/var/lib/saned:/usr/sbin/nologin
inetsim:x:129:137::/var/lib/inetsim:/usr/sbin/nologin
colord:x:131:139:colord colour management daemon,,,:/var/lib/colord:/usr/sbin/nologin
geoclue:x:132:140::/var/lib/geoclue:/usr/sbin/nologin
king-phisher:x:133:141::/var/lib/king-phisher:/usr/sbin/nologin
taylan:x:1000:1000:taylan,,,:/home/taylan:/usr/bin/bash
Bakın “false” ifadesinin geçtiği satırlar hariç tüm içerikler konsola bastırıldı.
Ben yalnızca tek bir dosya üzerinde filtreleme yaptım ancak istersek birden fazla dosyanın tüm içeriğinde de filtreleme yapabiliriz. Ben denemek için /etc/passwd ve /etc/group dosya içeriklerinde “root” ifadesinin aranmasını istiyorum. Bunun için grep “root” /etc/passwd /etc/group şeklinde komutumu giriyorum.
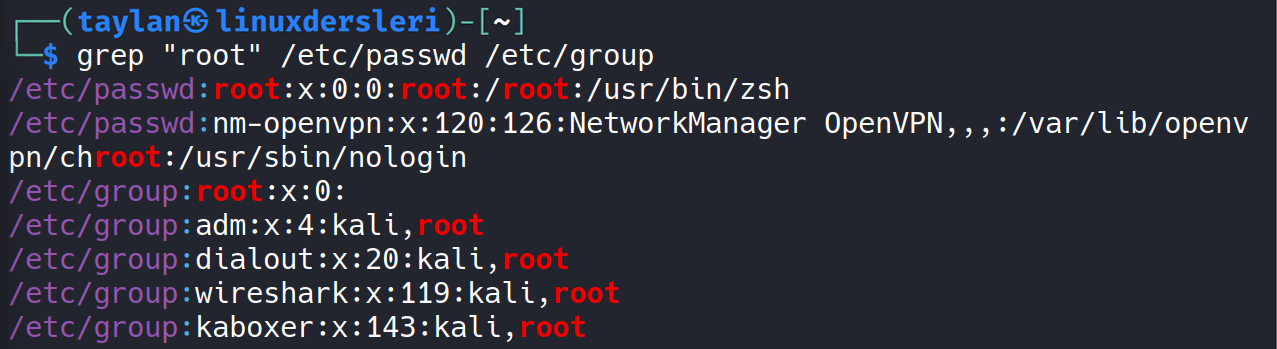
Bakın eşleşmiş olan satırlar hangi dosyada bulundukları da belirtilerek filtrelenmiş oldu. Yani gördüğünüz gibi istersek aynı anda çoklu şekilde dosyalar üzerinde de çalışabiliyoruz. Çoklu dosyalarla çalışmanın yanında dilersek alt dizinlerdekiler de dahil bir dizin içindeki tüm içeriklerin grep aracı tarafından filtrelenmesini sağlayabiliriz. Bunun için özyineleme yani “recursive” seçeneğinin kısalması olan r seçeneğini kullanabiliyoruz.
Örnek olarak “/etc/” dizini içinde, içinde “bashrc” ifadesi geçen tüm dosyaları filtrelemeyi deneyebiliriz. Bunun için grep -r “bashrc” /etc/ 2> /dev/null şeklinde komutumu giriyorum. Buradaki -r seçeneği benim hedef gösterdiğim bu dizinden başlayıp tüm alt dizinler de dahil olmak üzere tüm dosyalarda “test” ifadesinin geçtiği yerleri filtreleyip bana sunacak. Ayrıca yetki gibi nedenlerle oluşacak olan hatalı çıktıları yok etmek için 2> /dev/null komutunu da ekledim.
┌──(taylan@linuxdersleri)-[~]
└─$ grep -r "bashrc" /etc/ 2> /dev/null
/etc/skel/.bashrc.original:# ~/.bashrc: executed by bash(1) for non-login shells.
/etc/skel/.bashrc.original:# this, if it's already enabled in /etc/bash.bashrc and /etc/profile
/etc/skel/.bashrc.original:# sources /etc/bash.bashrc).
/etc/skel/.profile: # include .bashrc if it exists
/etc/skel/.profile: if [ -f "$HOME/.bashrc" ]; then
/etc/skel/.profile: . "$HOME/.bashrc"
/etc/skel/.bashrc:# ~/.bashrc: executed by bash(1) for non-login shells.
/etc/skel/.bashrc:# this, if it's already enabled in /etc/bash.bashrc and /etc/profile
/etc/skel/.bashrc:# sources /etc/bash.bashrc).
/etc/apparmor.d/abstractions/bash: @{HOME}/.bashrc r,
/etc/apparmor.d/abstractions/bash: /etc/bashrc r,
/etc/apparmor.d/abstractions/bash: /etc/bash.bashrc r,
/etc/apparmor.d/abstractions/bash: /etc/bash.bashrc.local r,
/etc/apparmor.d/abstractions/bash: # run out of /etc/bash.bashrc
/etc/bash.bashrc:# System-wide .bashrc file for interactive bash(1) shells.
/etc/bash.bashrc.save.1:# System-wide .bashrc file for interactive bash(1) shells.
/etc/bash.bashrc.save:# System-wide .bashrc file for interactive bash(1) shells.
/etc/profile: # The file bash.bashrc already sets the default PS1.
/etc/profile: if [ -f /etc/bash.bashrc ]; then
/etc/profile: . /etc/bash.bashrc
Bakın sırasıyla tüm dizinlerde gezildi ve “bashrc” ifadesi eşleşen satırlar ilgili dosyanın ismi de başta olacak şekilde bize sunuldu. Bu sayede kapsamlı şekilde istediğimiz spesifik kelime ile eşleşen dosyaları bulmamız mümkün oluyor. Buradaki r seçeneğinin fonksiyonunu teyit etmek isterseniz r seçeneği olmadan komutu tekrar girmeyi deneyebilirsiniz.
┌──(taylan@linuxdersleri)-[~]
└─$ grep "bashrc" /etc/
grep: /etc/: Is a directory
Bakın /etc/ adresinin bir dizin olduğu, yani dosya olmadığı için “bashrc” ifadesi geçen bir eşleşme bulunamayacağı konusunda uyarıldık. Bu sebeple alt dizinler de dahil, dizin içeriklerinde araştırma yapılabilmesi için “özyinelemeli” araştırma yapmak üzere r seçeneğini kullanmamız gerek.
Eğer aradığımız ifadeyle eşleşen verilerin tam olarak hangi satırda olduğunu görmek yerine yalnızca dosya isimlerinin bastırılmasını istersek l seçeneğini de kullanabiliriz. Ben denemek için girmiş olduğum komuta l seçeneğini ekleyeceğim.
┌──(taylan@linuxdersleri)-[~]
└─$ grep -rl "bashrc" /etc/ 2> /dev/null
/etc/skel/.bashrc.original
/etc/skel/.profile
/etc/skel/.bashrc
/etc/apparmor.d/abstractions/bash
/etc/bash.bashrc
/etc/bash.bashrc.save.1
/etc/bash.bashrc.save
/etc/profile
Bakın bu kez yalnızca içerisinde benim aradığım ifadeyi bulunduran dosyaların isimleri bastırılmış oldu. Çok daha derli toplu bir çıktı elde etmiş olduk.
Şimdi ben grep aracının diğer özelliklerinden bahsetmek için uzun bir isim listesi kullanmak istiyorum. Dilerseniz siz de buradan dosyayı indirip, anlatımları bu dosya üzerinden test edebilirsiniz.
Mesela ben isimler.txt dosyasında tam olarak “ahmet can” ifadesinin geçtiği satırları aramak istiyorum. Bunun için konsola grep ahmet can isimler.txt şeklinde komut girmeyi deneyebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ grep ahmet can isimler.txt
grep: can: No such file or directory
isimler.txt:ahmet
isimler.txt:ahmet kürşad
isimler.txt:ahmet ali
isimler.txt:kenan ahmet
isimler.txt:ahmet
isimler.txt:ahmet can durmus
isimler.txt:can ahmet furkan
Bakın yalnızca başında “ahmet” olan satırlar getirildi ve “can” isimli dosya veya dizin bulunamadı şeklinde hata verildi. Çünkü grep aracı, araştırmak istediğimiz ifadeyi parantez içinde girmediğimiz zaman ilk argümanın aranacak ifade olduğunu, diğer argümanların ise araştırmanın yapılacağı dosya veya dizinler olduğunu düşünüyor. Komutumuzu bu kez tırnak içinde tekrar girelim.
┌──(taylan@linuxdersleri)-[~]
└─$ grep "ahmet can" isimler.txt
ahmet can durmus
Bakın bu kez tam olarak tırnak içinde yazmış olduğum ifadeyi içeren satır getirilmiş oldu. Bizzat bu basit örneğimiz üzerinden teyit ettiğimiz gibi tırnak kullanımı önemli. Zaten hatırlıyorsanız daha önce kabuk genişletmelerinden bahsederken, grep ile regex kullanmak için de tırnak içinde yazmıştık. Tırnaklar sayesinde kesin olarak isteklerimizi iletmemiz mümkün oluyor.
Fark ettiyseniz bir önceki örneğimizde aldığımız çıktıların hepsi küçük büyük harf duyarlılığı dahilinde tam olarak yazdığımız ifade ile eşleşenlerdi. Eğer filtreleme yapılırken küçük büyük harf duyarlılığının görmezden gelinmesini istersek i seçeneğini kullanabiliyoruz. Buradaki i seçeneği “insensitive” yani “duyarsız” ifadesinin kısaltmasından geliyor. Pek çok araç da aynı şekilde küçük büyük harfin görmezden gelinmesi için i seçeneğini kullanmamızı istiyor.
Şimdi ben test etmek için en son girmiş olduğum komutu tekrar çağırıp, buraya i seçeneğini de ekliyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ grep -i "ahmet can" isimler.txt
Ahmet can
Ahmet Can Yazar
ahmet can durmus
Bakın bu kez küçük büyük harf demeden “ahmet can” ifadesi ile eşleşen tüm satırlar getirilmiş oldu. Neticede hepsi “ahmet can” ifadesiyle eşleşiyor ama küçük büyük harf farkları var. Siz de i seçeneği sayesinde bu şekilde filtreleme yapılırken küçük büyük harflerin görmezden gelinmesini sağlayabilirsiniz.
Tam olarak aradığımız kelime ile eşleşenleri filtrelemek için “word” ifadesinin kısaltmasından gelen w seçeneğini kullanabiliyoruz.
Kullanımını daha net gözlemleyebilmek için öncelikle grep “ali” isimler.txt komutunu girelim.
┌──(taylan@linuxdersleri)-[~]
└─$ grep "ali" isimler.txt
halil cansun
ali
Halil cansun
Mustafa alican
halime
Mehmet ali
ahmet ali
ali said
ali
Bakın çıktılarda yalnızca “ali” ifadesi değil, satırın herhangi bir noktasında “ali” ifadesi geçenler de bastırılmış oldu. Eğer ben bu şekilde herhangi bir noktada değil de tek başına “ali” ifadesini arıyorsam aynı komutumu bu kez w seçeneğiyle birlikte kullanabilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ grep -w "ali" isimler.txt
ali
Mehmet ali
ahmet ali
ali said
ali
Bakın bu kez yalnızca tam olarak “ali” kelimesinin tek başına bulunduğu satırlar filtrelenmiş oldu.
Aldığımız çıktıları daha okunaklı hale getirebiliriz. Mesela eğer n seçeneğini eklersek, satır numaralarını da görmemiz mümkün.
┌──(taylan@linuxdersleri)-[~]
└─$ grep -wn "ali" isimler.txt
43:ali
454:Mehmet ali
536:ahmet ali
554:ali said
598:ali
Bakın bu kez bu ifadelerin tam olarak hangi satırda geçtiği satırın en başında yazıyor.
Ayrıca satır numarası yerine istersek toplamda kaç eşleşme olduğunu öğrenmek için “count” ifadesinin kısaltmasından gelen c seçeneğini de kullanabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ grep -wc "ali" isimler.txt
5
Bakın toplam kaç eşleşme olduğu burada yazıyor. Benim dosyamda tam olarak 5 kere tamamı küçük harfli “ali” kelimesi geçiyormuş.
Dilersek verileri aşamalı olarak filtreleyip istediğimiz nihai verilere ulaşabiliriz.
Örneğin ben /var/log/user.log dosyasında “kali” ve “error” ifadelerinin geçtiği satırları filtrelemek istiyorum. Eğer komutumu cat /var/log/user.log | grep “kali” şeklinde girecek olursam yalnızca “kali” ifadesinin geçtiği satırlar getirilecek.
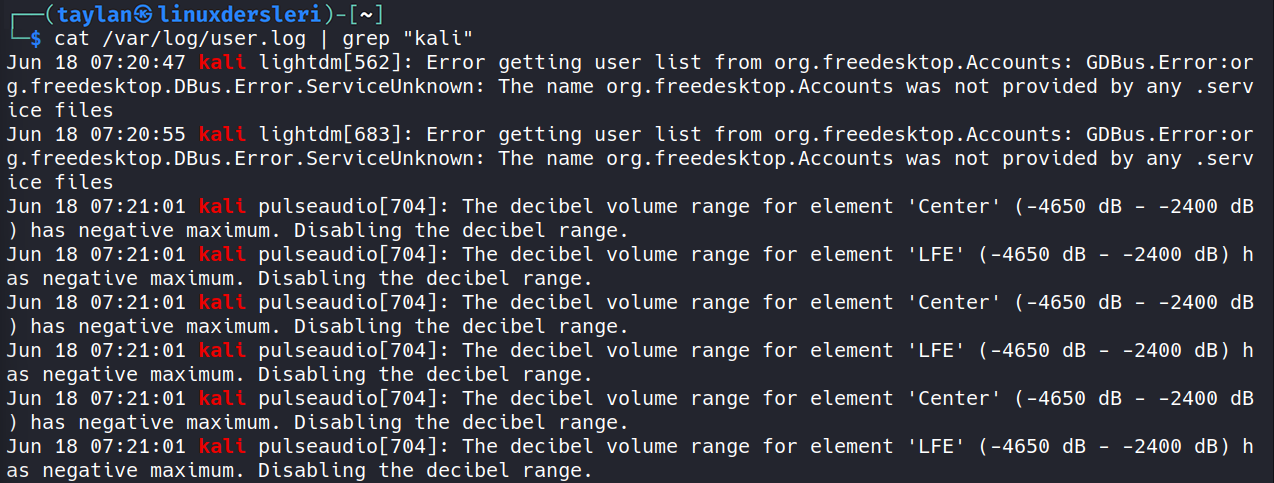
Ama ben hem “kali” hem de küçük büyük harf fark etmeksizin “error” ifadesinin geçtiği satırları filtrelemek istiyorum. Bunun için bir önceki komutumuza bir grep filtresi daha ekleyebiliriz.
Pipe yardımıyla ilk grep aracının filtrelediği sonuçları alıp, ikinci grep aracına filtrelemesi için iletelim.
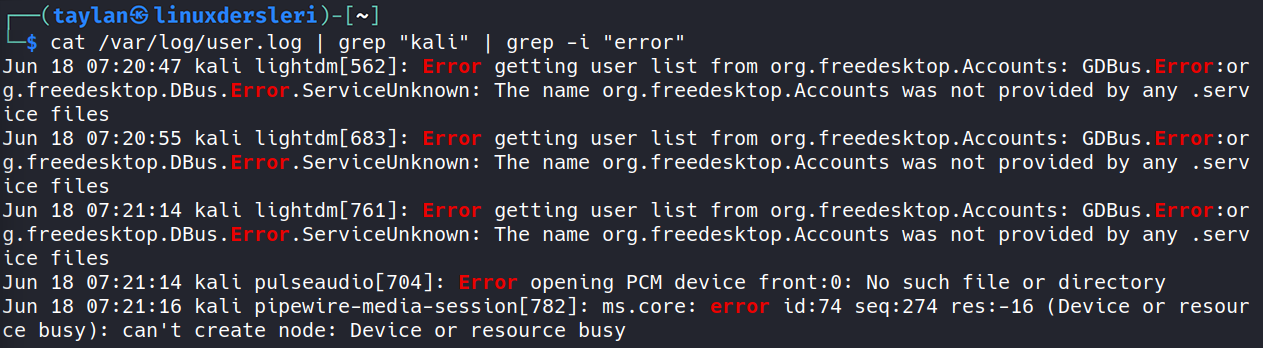
Bakın bu kez “kali” ve “error” ifadelerinin bulunduğu satırları filtrelemiş olduk. Yani bu basit örneğimiz üzerinden pipe mekanizması sayesinde aslında ne kadar esnekliğe sahip olduğumuzu bir kez daha bizzat teyit etmiş olduk. Siz de benzer çözümler için dilediğiniz kadar aracı uygun şekilde birbirine bağlayıp çalıştırabilirsiniz.
Tamamdır bence temel grep kullanımı için bu kadar bilgi yeterli.
Ben son olarak grep ile temel düzeyde regex kullanımından da bahsedip anlatımı noktalamak istiyorum.
grep Üzerinde Regex Kullanımıgrep aracı; “basit”, “genişletilmiş” ve “perl uyumlu” olmak üzere üç tür genişletme özelliğini destekliyor olmasına karşın varsayılan olarak “basit” genişletmeyi kullanıyor.
Biz öncelikle basit Regex’in temel karakterlerini tanıyarak başlayalım.
. - Herhangi bir tek karakteri temsil eder (satır sonu karakteri hariç).
* - Bir önceki karakterin sıfır veya daha fazla tekrarını temsil eder.
+ - Bir önceki karakterin bir veya daha fazla tekrarını temsil eder.
? - Bir önceki karakterin sıfır veya bir kez tekrarını temsil eder.
^ - Dizinin başlangıcını temsil eder.
$ - Dizinin sonunu temsil eder.
[] - Bir karakter kümesini belirtir. Bu kümedeki herhangi bir karakterle eşleşir.
[a-z] - Küçük harflerin olduğu bir karakter aralığını belirtir.
[A-Z] - Büyük harflerin olduğu bir karakter aralığını belirtir.
[0-9] - Rakamların olduğu bir karakter aralığını belirtir.
\ - Özel karakterlerin (örneğin . ) özel anlamlarını iptal eder.
| - Alternatifler arasında bir seçenek yani “ya da” koşulu belirtir.
Ben örnek olması Regex kullanımını grep üzerinden çok kısaca ele alıyor olacağım ancak Linux üzerinde Regex’i destekleyen diğer araçlar üzerinde de aynı şekilde Regex kullanabilirsiniz. Bu konu hakkında daha fazla detay almak için “Linux Üzerinde Regex Kullanımı ” blog yazısını okuyabilirsiniz.
^Spesifik olarak belirli bir ifadeyle başlayan satırları filtrelemek istersek şapka ya da düzeltme işareti olarak da bilinen bu ^ işareti kullanabiliyoruz.
Örneğin ben “ay” ifadesiyle başlayan satırları filtrelemek istersem grep “^ay” isimler.txt şeklinde komutumu yazabilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ grep "^ay" isimler.txt
aydin
ayşe fulya
ayşe gizem
aykut
aydin
ayşe
ayşegül
Bakın yalnızca başlangıcı “ay” olanlar bastırılmış oldu.
$Tersi şekilde eğer satır sonlarındaki karakterlere göre filtreleme yapmak istersek de dolar $ işaretini kullanabiliyoruz. Ben sonu “ay” ifadesiyle bitenleri filtrelemek için grep “ay$” isimler.txt şeklinde giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ grep "ay$" isimler.txt
Koray
Mehmet koray
Feray
Tümay
eray
Nuray
Ilkay
gökay
Bakın yalnızca satır sonunda “ay” ifadesi olanlar bastırıldı. Bu tanımı yazarken dolar işaretini sona eklemiz gerektiğine dikkat edin lütfen. Eğer dolar işaretini bu şekilde sonda değil de başta yazacak olursanız ilgili eşleşme sağlanamaz.
.Nokta işareti sayesinde tek bir karakter ile eşleşecek şekilde tanımlama yapmamız mümkün.
Denemek için grep “ay.” isimler.txt şeklinde komutumuzu girelim.
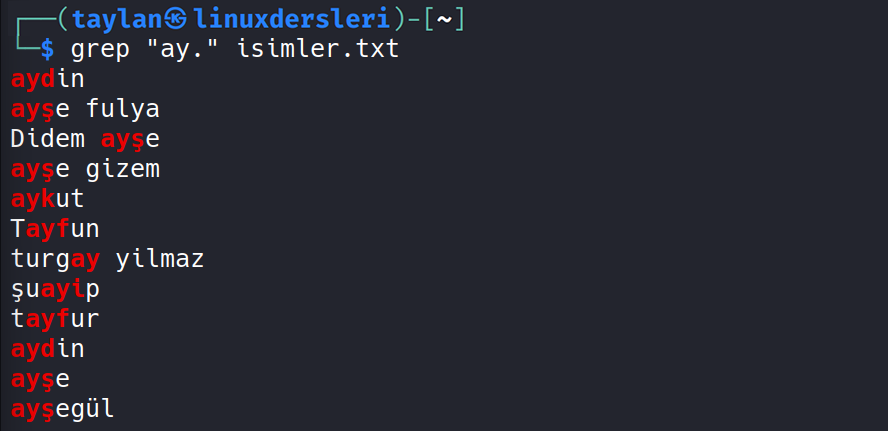
Bakın “ay” ifadesi ve devamında küçük büyük olması fark etmeksizin herhangi bir karakteri barındıran tüm veriler filtrelenmiş oldu. Örneğin bir nokta daha eklersek, herhangi bir karakter daha ekleneceği için “ay” ile başlayıp devamında herhangi iki karakteri barındıranlar filtrelenecek.
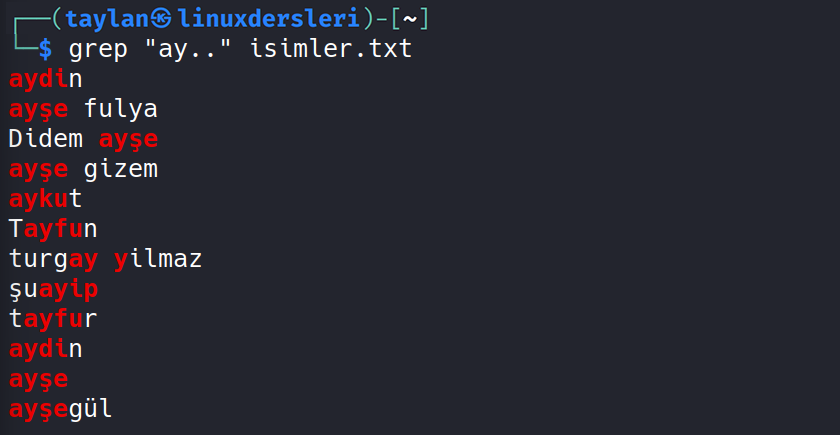
Bakın tam olarak beklediğimiz gibi “ay” ile başlayan ve devamında herhangi iki karakteri barındıran tüm satırılar filtrelendi.
[]Eğer rastgele karakterler yerine spesifik olarak bizim istediğimiz bazı karakterlerin bulunduğu verileri filtrelemek istersek köşeli parantez kullanabiliriz. Köşeli parantez içinde karakter kümelerini liste şeklinde verebiliyoruz.
Örneğin ben “a” karakterinden sonra yalnızca “k” “l” ve “r” karakterlerinden birini barındıran verileri filtrelemek istediğim için grep “a[klr]” isimler.txt şeklinde komutumu giriyorum.
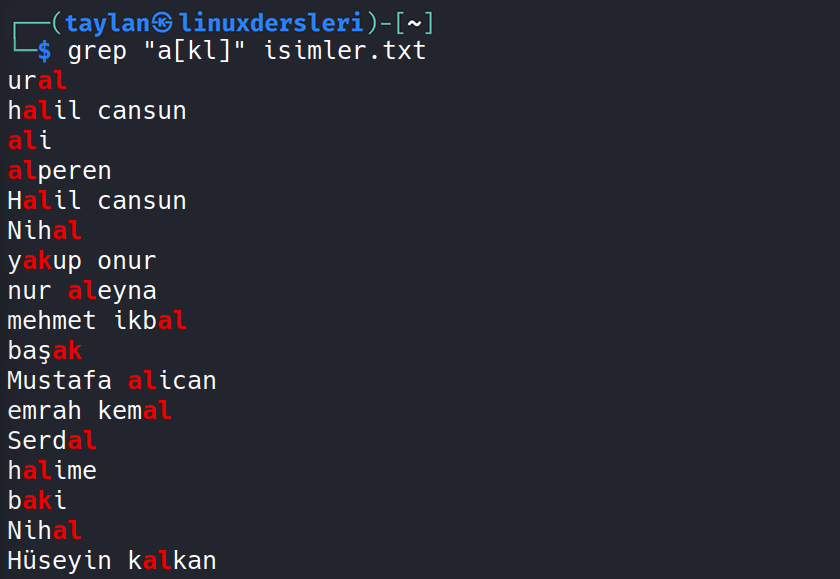
Bakın tam olarak “a” karakterinden sonra köşeli parantez içinde belirttiğimiz karakterlerden birini barındıran tüm veriler filtrelendi. Tersi şekilde eğer köşeli parantez içindeki karakteri hariç tutup bunlar dışındaki herhangi karakterleri kapsamak istersek de köşeli parantezin en başında şapka ^ işaretini kullanabiliyoruz.
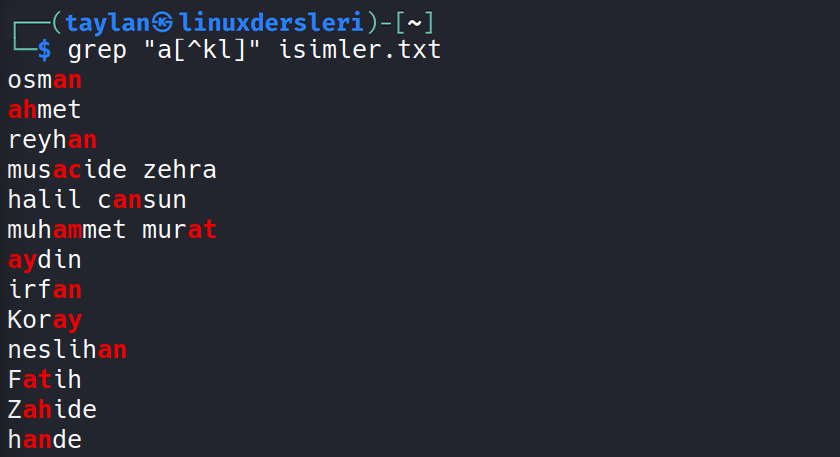
Yani gördüğünüz gibi şapka işareti sayesinde buradaki karakterleri hariç tutarak filtreleme yapabiliyoruz.
Burada dikkat ettiyseniz bizim köşeli parantez içinde yazdığımız karakterler yalnızca tek bir karakter ile eşleşme sağlıyor. Örneğin ben “a” karakterinden sonra “k” “l” “r” karakterlerini bulundurmayan ama “a” “b” ve “c” karakterinden birini bulunduran veriyi filtrelemek istersem komutumu grep a[^klr][abc] isimler.txt şeklinde girebilirim.
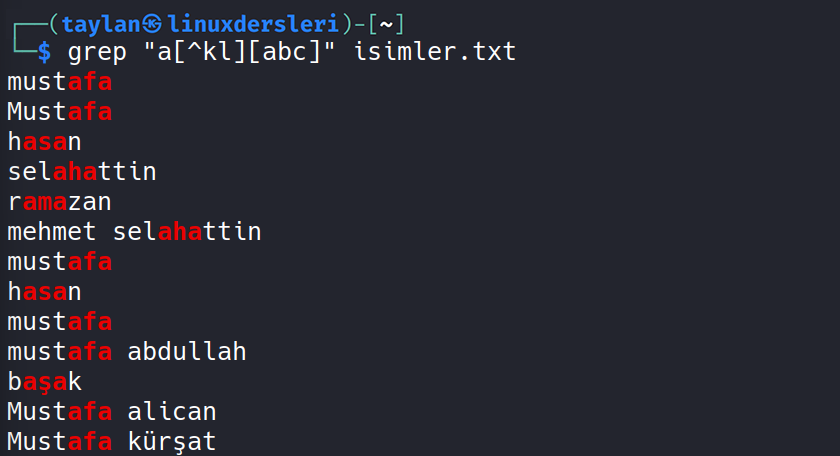
Bakın tam olarak “a” karakterinde sonra “k” “l” “r” karakterini barındırmayan ama üçüncü karakterinde “a” “b” ve “c” karakterlerinden herhangi birini barındıran tüm veriler filtrelenerek renklendirilmiş oldu.
Yani gördüğünüz gibi köşeli parantez sayesinde spesifik olarak tek bir karakterin nasıl olması veya olmaması gerektiğini belirtebiliyoruz. Ve tabii ki peş peşe burada olduğu gibi köşeli parantez kullanarak da hangi karakterin ne şekilde olabileceğini de spesifik olarak sınırlayabiliyoruz.
İşte basit regex genişletmeleri bu şekilde. Ben hepsine tek tek değinmek istemiyorum. Daha fazla bilgi almak için mutlaka buradaki blog yazısını baştan sonra okuyup öyle devam edin. Bu sayede Linux üzerinde Regex’i çok daha etkili şekilde kullanabiliyor olacaksınız.
grep Üzerinde Genişletilmiş Regex KullanımıAyrıca basit regex dışında, genişletilmiş regex kalıplarını kullanmamız da mümkün. Fakat ben bu eğitimde bunların detaylarına girmek istemiyorum. Daha fazla bilgi almak için blog yazısını okuyabilirsiniz.
Ben yalnızca örnek olması için genişletilmiş regex kullanımına bir tane örnek vermek istiyorum.
Örneğin regex için “ya da” anlamına gelen dik çizgi | işaretini kullanarak filtreleme yapmayı deneyebiliriz.
Ben “ahmet” “can” “ayse” isimlerinden birini barındıran satırları filtrelemek istersem grep “ahmet|can|ayse” isimler.txt şeklinde komutumu girebilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ grep "ahmet|can|ayse" isimler.txt
Bakın bu şekilde girince bir çıktı almadık çünkü buradaki kullandığımız dikey çizgi | karakteri regex’in “ya da” anlamında kullandığı karakter olarak temsil edilmedi. Bunun yerine komutumuza E seçeneğini eklersek bu karakter beklendiği şekilde çalışacak. Hemen denemek için komutumuzu çağırıp büyük E seçeneğini ekleyelim.
┌──(taylan@linuxdersleri)-[~]
└─$ grep -E "ahmet|can|ayse" isimler.txt
ahmet
halil cansun
yiğit can
Halil cansun
Mustafa alican
ahmet kürşad
cansu
ahmet ali
kenan ahmet
Ahmet can
ahmet
can yıldırım
ahmet can durmus
can ahmet furkan
Bakın bu kez “ahmet” “can” veya “ayse” ifadelerini barındıran satırların filtrelenmesini sağlamış olduk. Buradaki büyük E seçeneği “Extended” yani “genişletilmiş” ifadesinin kısaltmasından gelen seçeneğimiz. Bu seçenek sayesinde tıpkı buradaki dikey çizgi | gibi, doğrudan genişletilmiş regex karakteri olarak algılanmayan regex karakterlerinin kullanılabilmesi de mümkün oluyor.
Linux üzerinde ? + {} ve | metakarakterleri genişletilmiş regex dahilinde ele alındığı için bunları kullanırken ilgili araca bu durumu grep aracının -E seçeneğinde olduğu gibi açıkça ifade etmemiz gerek. Ayrıca bu karakterleri genişletilmiş regex yerine basit regex kurallarıyla birlikte kullanırken bu karakterlerden önce ters slash \ koyarak bu karakterlerin özel anlamları ile ele alınmasını da sağlayabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ grep "ahmet\|can\|ayse" isimler.txt
ahmet
halil cansun
yiğit can
Halil cansun
Mustafa alican
ahmet kürşad
cansu
ahmet ali
kenan ahmet
Ahmet can
ahmet
can yıldırım
ahmet can durmus
can ahmet furkan
Bakın basit regex üzerinden genişletilmiş regex metakarakterlerini kullanmak için bu karakterlerden önce ters slash kullanabileceğimizi bizzat görmüş olduk. Birden fazla kez tekrarladığım gibi Linux üzerinde Regex kullanımını daha net anlamak için mutlaka buradaki blog içeriğine göz atın. Ben bu blog yazısını okuduğunuzu yani regex kullanımını bildiğinizi varsayarak eğitime devam ediyor olacağım.
Benim şimdilik regex ve grep aracı hakkında bahsetmek istediklerim bu kadar. Zaten temelde bilmemiz gerekenlerden bahsettik. Daha fazlası için hem grep aracının yardım sayfasına hem de regex için harici kaynaklara bakmanız yeterli.
find Komutufind aracı, açıkça isminden de anlaşılabileceği gibi sistem üzerindeki dosya ve klasörleri arayıp, konumlarını bulmamıza yardımcı olan bir araç. En yalın kullanımı find komutundan sonra hangi dizinde araştırıma yapılacağını belirtip daha sonra -name seçeneğinin ardından araştırılacak olan dosya ya da klasör isminin girilmesi şeklinde.
Ben aranacak dosya ve klasörleri kendim oluşturmak için touch ~/Documents/bulbeni ve mkdir ~/Pictures/bulbeni komutlarını giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ touch ~/Documents/bulbeni
┌──(taylan@linuxdersleri)-[~]
└─$ mkdir ~/Pictures/bulbeni
Böylelikle aynı isimli dosya ve klasörümüzü farklı dizinlerde oluşturmuş olduk.
Şimdi find komutumuzu bu dosya ve klasörleri bulmak için kullanabiliriz. Ben şu an ev dizinimdeyim, bulunduğum dizinden itibaren tüm alt dizinlere bakılıp aradığım kelime ile eşleşen dosya ya da klasör ismi var mı diye bakmak için find . yazıyorum buradaki nokta . bulunduğum dizini temsil ediyor. Aslında nokta yazmasam bile find komutu ekstra bir hedef belirtmediğimiz sürece mevcut dizinimizde araştırma yapıyor ama biz daha anlaşılır olması için mevcut dizinimizi nokta ile hedef gösterebiliriz. Yazacağım kelimeyle eşleşen dosya ve klasörleri bulmak için de -name seçeneğinin ardından aradığım kelimeyi giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ find . -name "bulbeni"
./Documents/bulbeni
./Pictures/bulbeni
Bakın isimle eşleşen hem klasör hem de dosya, tam konumlarıyla birlikte listelenmiş oldu.
find komutunun en yalın kullanımı bu şekilde. Tabii ki tüm kullanım imkanı bundan ibaret değil. Araştırma yapılırken filtreleme yapılabilmesi için aranacak dosya veya klasörün özelliklerine göre kullanabileceğimiz birden fazla seçenekler bulunuyor. Hemen kısaca bunlardan söz edelim.
Eğer yalnızca dosyaları filtrelemek istiyorsak type seçeneğinin ardından “file” yani “dosya” ifadesinin kısaltmasından gelen f parametresini yazmamız gerekiyor. Eğer klasörleri filtrelemek istersek de “directory” yani “klasör” ifadesinin kısaltmasından gelen d ifadesini kullanabiliyoruz. Hemen örneğimiz üzerinden deneyelim.
Ben öncelikle “bulbeni” isimli dosyayı araştırmak istediğim için find . -name “bulbeni” -type f şeklinde yazıyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ find . -name "bulbeni" -type f
./Documents/bulbeni
Bakın burada aldığımız çıktı yalnızca dosyanın konumunu veriyor.
Benzer şekilde yalnızca klasörü bulmak için d parametresi ile araştırma yapabiliriz.
find . -name “bulbeni” -type d şeklinde araştıralım.
┌──(taylan@linuxdersleri)-[~]
└─$ find . -name "bulbeni" -type d
./Pictures/bulbeni
Bakın bu çıktı da klasörün konumuna işaret ediyor.
Yani bakın bizzat teyit ettiğimiz gibi find ile araştırma yapılırken bu şekilde dosya ve klasör olma durumuna göre yani tipine göre filtreleme yapabiliyoruz.
Mesela ben yalnızca mevcut bulunduğum dizinde araştırma yaptım ama aslında istediğim bir dizin altında araştırma yapılmasını sağlayabilirim. Denemek için bu kez “/etc/” dizini atlında sonu “.conf” ile biten tüm içerikleri bastırmak istiyorum. Bunun için find /etc/ -name “*.conf” komutunu girebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ find /etc/ -name "*.conf"
/etc/inetsim/inetsim.conf
/etc/initramfs-tools/initramfs.conf
/etc/initramfs-tools/update-initramfs.conf
/etc/pulse/daemon.conf
/etc/pulse/client.conf.d/01-enable-autospawn.conf
/etc/pulse/client.conf
/etc/apparmor/parser.conf
...
..
.
ℹ️ Not: Çıktı çok uzun olduğu için kısaltarak ekledim.
Bakın “/etc/” dizini atlında isminin sonu “.conf” ile biten tüm dosya ve dizinler filtrelenmiş oldu. Eğer yalnızca “/etc/” dizini altında değil de tüm sistem genelinde araştırma yapmak istersek araştırılacak dizin olarak yalnızca slash / karakterini yazmamız da yeterli.
┌──(taylan@linuxdersleri)-[~]
└─$ find / -name "*.conf"
/home/taylan/.config/qt5ct/qt5ct.conf
find: ‘/root’: Permission denied
/usr/lib32/gconv/gconv-modules.d/gconv-modules-extra.conf
/usr/lib/kernel/install.conf
/usr/lib/python3/dist-packages/cme/data/cme.conf
/usr/lib/python3/dist-packages/binwalk/config/extract.conf
/usr/lib/NetworkManager/conf.d/no-mac-addr-change.conf
/usr/lib/sysctl.d/50-bubblewrap.conf
/usr/lib/sysctl.d/50-pid-max.conf
/usr/lib/sysctl.d/99-protect-links.conf
/usr/lib/sysusers.d/systemd-journal.conf
/usr/lib/sysusers.d/systemd-resolve.conf
/usr/lib/sysusers.d/dbus.conf
...
..
.
Tabii ki bu işlem tüm sistem hiyerarşisinin kontrol edilmesini gerektirdiği için biraz vakit alabilir. Ancak neticede gördüğünüz gibi istediğimiz bir dizin altında aradığımız isimle eşleşen dosya ve dizinleri belirtebiliyoruz.
Boyuta göre filtreleme yapmak için size seçeneğini kullanmamız gerekiyor. Örneğin bulunduğumuz dizin altındaki 1 megabayttan büyük olan tüm dosyaları getirmek için find . -type f -size +1M şeklinde komutumuzu kullanabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ find . -type f -size +1M
./.mozilla/firefox/d5n1etpa.default-esr/storage/permanent/chrome/idb/3870112724rsegmnoittet-es.sqlite
./.mozilla/firefox/d5n1etpa.default-esr/places.sqlite
./.mozilla/firefox/d5n1etpa.default-esr/security_state/data.safe.bin
./.mozilla/firefox/d5n1etpa.default-esr/favicons.sqlite
...
..
.
Bakın buradaki tüm dosyalar 1 megabayttan büyük olan dosyalar. Eğer küçük olanları istersek artı yerine eksi - işaretini girebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ find . -type f -size -1M
./dosya1
./dosya2
./klasor/dosya1
./klasor/dosya2
./klasor/dosys3
./.mozilla/firefox/d5n1etpa.default-esr/.parentlock
./.cache/go-build/e3/e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855-d
./.cache/mozilla/firefox/d5n1etpa.default-esr/cache2/ce_T151c2VyQ29udGV4dElkPTUsYSw=
./.cache/mozilla/firefox/d5n1etpa.default-esr/cache2/ce_T151c2VyQ29udGV4dElkPTUs
./.ICEauthority
./Documents/bulbeni
./.config/xfce4/desktop/icons.screen0-1263x957.rc
./.config/xfce4/desktop/icons.screen0-2544x966.rc
./Desktop/test.txt
./dosys3
./calısma/y5t.webp
Bakın bu aldığımız çıktılar da 1 megabayttan küçük olanlar.
Boyutu farklı girmek isterseniz;
bayt için b,
kilobayt için k
megabayt için büyük M
gigabayt için büyük G kullanabilirsiniz.
Örneğin ben kök dizin altında 1 gigabayttan büyük olan dosyaları bulmak istiyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ find / -type f -size +1G 2>/dev/null
/proc/kcore
ℹ️ Not: Kök dizin altında yetki hatası aldığımız için hatalı çıktıları 2> /dev/null komutu ile yok ettim.
Gördüğünüz gibi 1 gigabayttan büyük olan dosyam bulunmuş oldu. Siz de istediğiniz büyüklük birimine göre filtreleme yapabilirsiniz.
Ayrıca erişim, değişim ve düzenleme tarihlerine göre de filtrelemeniz de mümkün. Zaten bu tarihlerin neyi ifade ettiğini daha önce açıklamıştık.
Örneğin düzenlenme(modify) tarihi için mtime kullanılıyorken, değişim(change) tarihi için ctime, erişim(access) tarihi için de atime parametrelerini kullanabiliyoruz.
Daha azı için eksi -
Daha fazlası için artı +
Tam tarih için doğrudan günü belirtebiliyoruz.
Eğer ben mevcut bulunduğum dizinde tam olarak 10 gün önce düzenlenmiş içerikleri görmek istersem find -mtime 10 şeklinde komutumu girebilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ find -mtime 10
./Documents/belgeler
./.config/xfce4/desktop/icons.screen0-1263x957.rc
./.config/xfce4/desktop/icons.screen0-2544x966.rc
Bakın buradaki içerikler tam olarak 10 gün önce düzenlenmiş dosya ve klasörler.
Eğer 2 günden daha kısa bir süre önce düzenlenmişleri öğrenmek istersek -2 ile iki günden öncesini belirtebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ find -mtime -2
.
./.wget-hsts
./.vboxclient-draganddrop.pid
./dosya1
./dosya2
./liste.txt
./klasor
./klasor/oku-beni
./klasor/dosya1
./klasor/dosya2
./klasor/liste2
./klasor/deneme.txt
./klasor/liste
./klasor/dosys3
./isimler.txt
./.vboxclient-clipboard.pid
./.bash_history
./.xsession-errors
./.Xauthority
./liste
./Documents
./Documents/bulbeni
./sırala
./.vboxclient-display-svga-x11.pid
./dosys3
./Downloads
./.vboxclient-seamless.pid
./Pictures
./Pictures/bulbeni
./bul
./liste2.txt
Bakın bunlar bu gün veya dün düzenlenmiş olan içerikler.
Eğer düzenleme süresi 5 günden daha önceki tarihler olan içerikleri görmek istersek de find -mtime +5 şeklinde düzenlenme tarihinden 5 günden daha fazla zaman geçmiş olacağını belirtebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ find -mtime +5
./.bashrc.original
./dosya.txt
./.gnupg
./.gnupg/private-keys-v1.d
./.java
./.java/.userPrefs
./.java/.userPrefs/burp
./.java/.userPrefs/burp/prefs.xml
...
..
.
Bakın buradaki dosyalarım tamamı, en yakın 6 gün önce düzenlemiş olanlar. Kimisi 100 gün önce de düzenlemiş olabilir. Neticede düzenleme tarihi son 5 günden öncesi olanları filtrelemek için +5 parametresini kullandık.
Örneğin son 24 saatte düzenlenmiş olanları filtrelemek için find -mtime -1 şeklinde girebiliriz. Buradaki -1 bir günden daha kısa bir süre öncesinin zaman aralığını belirttiği için son 24 saatten şu ana kadar düzenlenmiş içerikler filtreleniyor.
┌──(taylan@linuxdersleri)-[~]
└─$ find -mtime -1
.
./.wget-hsts
./.vboxclient-draganddrop.pid
./dosya1
./dosya2
./liste.txt
./klasor
./klasor/oku-beni
./klasor/dosya1
./klasor/dosya2
./klasor/liste2
./klasor/deneme.txt
./klasor/liste
./klasor/dosys3
./isimler.txt
./.vboxclient-clipboard.pid
./.bash_history
./.xsession-errors
./.Xauthority
./liste
./Documents
./Documents/bulbeni
./sırala
./.vboxclient-display-svga-x11.pid
./dosys3
./Downloads
./.vboxclient-seamless.pid
./Pictures
./Pictures/bulbeni
./bul
./liste2.txt
Ben örnekler sırasında düzenlenme tarihleri için mtime seçeneğini kullandım ama siz değişim tarihleri için ctime, erişim tarihleri için de aynı şekilde atime seçeneklerini kullanarak arama sonuçlarını filtreleyebilirsiniz.
Ayrıca ben hep günler üzerinden ele aldım ancak aslında min parametresi sayesinde dakika üzerinden de bu filtrelemeyi yapmamız mümkün. Örneğin son 50 dakika içinde düzenlenmiş(modify) olanları filtrelemek için find -mmin -50 şeklinde komutumu girebilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ find -mmin -50
.
./.bash_history
./Documents
./Documents/bulbeni
./.config/xfce4/panel
./.config/xfce4/panel/genmon-15.rc
./.config/qterminal.org
./.config/qterminal.org/qterminal.ini
./Pictures
./Pictures/bulbeni
Bakın bunlar son 50 dakika içerisine düzenlenmiş olanlar. Günleri belirtirken time şeklinde yazıyorken, dakikaları belirtmek için “minutes” ifadesinin kısaltmasından gelen “min” seçeneğini kullanıyoruz. Yani düzenlenme(modify) dakikası için mmin, değişim(change) dakikası için cmin, erişim(access) dakikası için de amin, seçeneklerinin ardından dakikayı belirtebiliyoruz. Ben burada -50 şeklinde yazdığım için son 50 dakika içerisindekileri kapsadım. Örneğin +50 yazacak olursam, düzenlenme tarihi son 50 dakikayı geçmiş olan tüm içerikleri kastetmiş oluyorum.
Örneğin ben son 1 saat içerisinde hiç açmadığım yani erişmediğim içerikleri listelemek istersem, find -amin +60 şeklinde komutumu girebilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ find -amin +60
./yepyenidosya
./.bashrc.original
./dosya.txt
./sonuc
./.gnupg
./.java
./.java/.userPrefs
./.java/.userPrefs/burp
./.java/.userPrefs/burp/prefs.xml
Bakın burada listelenmiş olan içeriklerin hiç birisine son 1 saat içerisinde erişim sağlamamışım. Tersi şekilde son bir saat içerisinde erişim sağladıklarımı görmek için de -60 parametresini girebilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ find -amin -60
.
./.gnupg/private-keys-v1.d
./.local/state/pipewire/media-session.d
./.bash_history
./.cache/gstreamer-1.0
./Documents
./Documents/bulbeni
./.config/xfce4/panel
./.config/xfce4/panel/genmon-15.rc
./.config/gtk-3.0
./.config/qterminal.org
./.config/qterminal.org/qterminal.ini
./Pictures
./Pictures/bulbeni
Bakın bunlar da son bir saat içerisinde erişim sağlanmış olanlar. Bence kullanımı son derece kolay. Biraz pratik yaparsanız tam olarak kullanımına alışırsınız zaten.
Ayrıca tüm bu bahsettiklerimiz dışında eğer man find şeklinde yazarsanız, aslında ne kadar çok filtreleme seçeneği olduğunu kendiniz de görebilirsiniz. Ancak ben hepsine değinmeyeceğim. İhtiyacınız olduğunda manuel sayfasından açıp bakabilirsiniz.
Henüz daha öğrenmediğimiz için yetkilere ve sahipliğe göre filtrelemeden bahsetmek istemiyorum. Ama zaten aynı şekilde find aracının yardım bilgilerinde belirtilen tüm seçenekleri ihtiyacınıza göre kullanabilirsiniz. Örneğin içerikleri yetkilerine göre filtrelemek için perm seçeneğini kullanıyorken, sahipliğine göre filtrelemek için de user seçeneğini kullanabiliyoruz. Ve bunlar gibi yardım sayfasında görebileceğiniz çeşitli filtreleme seçenekleri mevcut. İhtiyaç duyduğunuzda açıp yardım bilgisinden hangi seçeneği kullanmanız gerektiğini öğrenebilirsiniz.
Ben dediğim gibi yetki ve sahip kavramlarından henüz bahsetmediğimiz için kafanızın karşımasını istemiyorum, zaten aynı şekilde tek yaptığımız bu özelliklere göre filtreleme yapmak. Bu konuları öğrendiğinizde dönüp find ile bu kriterlere göre filtreleme yapmakta özgürsünüz.
-notİlgili seçenekten önce -not seçeneğini kullanarak, ilgili filtrelemenin tam tersini elde edebiliriz.
Örneğin ben find -name “*.webp” komutuyla mevcut dizinim altındaki sonu “.webp” ile biten tüm içerikleri filtrelersem, gördüğünüz gibi tam istediğim gibi bu adresleri öğrenebiliyoruz.
┌──(taylan@linuxdersleri)-[~]
└─$ find -name "*.webp"
./.cache/thumbnails/large/3ab698ceca6c7925eb3d1b884a26e75d.webp
./.cache/thumbnails/large/c338c09e4cee3d0a205c77d2888f0fc0.webp
./.cache/thumbnails/large/52e5c5b7a8eaeca56e0bf2634080a8f3.webp
./.cache/thumbnails/large/b3fe8ef292b398b5ff2b48953a2dcaa3.webp
./.cache/thumbnails/large/601fa98430e31526893c2cd4c497fb77.webp
./.cache/thumbnails/large/e0142d1bb7807691d1f3c6fbef0db9d6.webp
./.cache/thumbnails/large/4d47671573280bf1e30ef346ecd154ed.webp
./.cache/thumbnails/normal/4ef1aeb4f74b05b642089a3fa725f6ff.webp
./.cache/thumbnails/normal/fd024d11882b348b20550093e6339f54.webp
./.cache/thumbnails/normal/ce9a4aafaf687c2389abce167751da5e.webp
./.cache/thumbnails/normal/b229cfc54c3672c84da5bfb87f3c7ec9.webp
./.cache/mozilla/firefox/d5n1etpa.default-esr/thumbnails/b8d33cbd34677070b8b70079044c40aa.webp
./.cache/sessions/thumbs-taylan:0/Default.webp
./Pictures/Screenshot_2023-05-30_10_28_23.webp
./Pictures/Screenshot_2023-05-24_11_11_16.webp
./Pictures/Screenshot_2022-07-03_06_45_05.webp
./Pictures/Screenshot_2023-05-30_13_21_21.webp
./Pictures/Screenshot_2022-07-03_06_45_04.webp
./Pictures/Screenshot_2022-07-03_06_45_03.webp
./Pictures/Screenshot_2022-06-30_03_23_40.webp
./Pictures/Screenshot_2023-05-30_10_28_26.webp
./Pictures/Screenshot_2023-05-30_10_28_19.webp
./Pictures/Screenshot_2022-06-17_13_15_28.webp
./Pictures/Screenshot_2022-07-03_06_45_02.webp
./Pictures/Screenshot_2022-06-17_13_15_26.webp
./Pictures/Screenshot_2023-05-28_10_42_36.webp
./Pictures/Screenshot_2022-07-03_06_45_24.webp
Eğer ben bu komutumu tekrar çağırıp, tersini kullanmak istediğim seçenekten hemen önce -not seçeneğini ekleyecek olursam yani find -not -name “*.webp” şeklinde komut girersem bu kez sonunda “.webp” ismi olanlar hariç tüm içerikler bulunup konsola bastırılacak.
┌──(taylan@linuxdersleri)-[~]
└─$ find -not -name "*.webp"
.
./yepyenidosya
./.bashrc.original
./dosya.txt
./sonuc
./.gnupg
./.gnupg/private-keys-v1.d
./.java
./.java/.userPrefs
./.java/.userPrefs/burp
./.java/.userPrefs/burp/prefs.xml
...
..
.
İşte burada benim yalnızca isim seçeneği üzerinden gösterdiğim bu -not seçeneği sayesinde tüm filtrelerin tersi şekilde çalışmasını sağlayabilirsiniz. Örneğin ben tam olarak 10 gün önce düzenlenmiş içerikleri filtrelemek için find -mtime 10 şeklinde komut girersem, tam olarak 10 gün önce düzenlenmiş içerikler listeleniyor.
┌──(taylan@linuxdersleri)-[~]
└─$ find -mtime 10
./Documents/belgeler
./.config/xfce4/desktop/icons.screen0-1263x957.rc
./.config/xfce4/desktop/icons.screen0-2544x966.rc
Eğer buradaki mtime seçeneğinden önce -not seçeneğini ekleyecek olursak, bu kez tam tersi şekilde yani 10 gün önce oluşturulmamış olan tüm içerikler bastırılacaktır.
┌──(taylan@linuxdersleri)-[~]
└─$ find -not -mtime 10
.
./yepyenidosya
./.bashrc.original
./dosya.txt
./sonuc
./.gnupg
./.gnupg/private-keys-v1.d
./.java
./.java/.userPrefs
./.java/.userPrefs/burp
./.java/.userPrefs/burp/prefs.xml
Bu şekilde tüm filtreleme seçeneklerinden önce -not kullanarak ilgili filtrelemeyi tersine çevirmeniz mümkün.
-and -orFiltrelemeyi tek bir kritere göre değil de birden fazla kritere göre yapmak istersek koşul belirten “-and” “-or” gibi seçenekleri kullanabiliyoruz. Örneğin ben sonu “.txt” ile veya “.webp” ile bitenleri filtrelemek istersem find -name “*.txt” -or -name “*.webp” komutunu girebilirim.
Bakın burada isim filtrelemesi için iki özel isim belirtip, bu isimlerin arasına da -or seçeneği ile “veya” koşulu eklemiş olduk. Bu sayede sonu “.txt” ile veya “.webp” biten tüm içerikler filtrelenecek.
┌──(taylan@linuxdersleri)-[~]
└─$ find -name "*.txt" -or -name "*.webp"
./dosya.txt
./hatasız.txt
./metin1.txt
./harf.txt
./.local/lib/python3.9/site-packages/uro-1.0.0.dist-info/entry_points.txt
./.local/lib/python3.9/site-packages/uro-1.0.0.dist-info/top_level.txt
./.local/share/powershell/PSReadLine/ConsoleHost_history.txt
./.local/share/sqlmap/output/en.trendyol.com/target.txt
./.local/share/sqlmap/output/tech.trello.com/target.txt
./.local/share/sqlmap/output/blog.trello.com/target.txt
./.local/share/sqlmap/output/link2.trendyol.com/target.txt
./.local/share/sqlmap/output/api.trello.com/target.txt
./.local/share/sqlmap/output/api-gateway.trello.com/target.txt
./.local/share/sqlmap/output/help.trello.com/target.txt
./.local/share/sqlmap/output/br.blog.trello.com/target.txt
./.local/share/sqlmap/output/c.trello.com/target.txt
./.local/share/sqlmap/output/info.trello.com/target.txt
./.local/share/sqlmap/output/akademi.trendyol.com/target.txt
./.local/share/sqlmap/output/m.trendyol.com/target.txt
./liste.txt
./klasor/deneme.txt
./Public/metin1.txt
./Public/sonuc.txt
./Public/metin2.txt
./isimler.txt
./hatalı.txt
./.mozilla/firefox/d5n1etpa.default-esr/AlternateServices.txt
./.mozilla/firefox/d5n1etpa.default-esr/SiteSecurityServiceState.txt
./.mozilla/firefox/d5n1etpa.default-esr/pkcs11.txt
./hatasız2.txt
./.cache/thumbnails/large/3ab698ceca6c7925eb3d1b884a26e75d.webp
./.cache/thumbnails/large/c338c09e4cee3d0a205c77d2888f0fc0.webp
./.cache/thumbnails/large/52e5c5b7a8eaeca56e0bf2634080a8f3.webp
./.cache/thumbnails/large/b3fe8ef292b398b5ff2b48953a2dcaa3.webp
./.cache/thumbnails/large/601fa98430e31526893c2cd4c497fb77.webp
./.cache/thumbnails/large/e0142d1bb7807691d1f3c6fbef0db9d6.webp
./.cache/thumbnails/large/4d47671573280bf1e30ef346ecd154ed.webp
./.cache/thumbnails/normal/4ef1aeb4f74b05b642089a3fa725f6ff.webp
./.cache/thumbnails/normal/fd024d11882b348b20550093e6339f54.webp
./.cache/thumbnails/normal/ce9a4aafaf687c2389abce167751da5e.webp
./.cache/thumbnails/normal/b229cfc54c3672c84da5bfb87f3c7ec9.webp
./.cache/mozilla/firefox/d5n1etpa.default-esr/thumbnails/b8d33cbd34677070b8b70079044c40aa.webp
./.cache/sessions/thumbs-taylan:0/Default.webp
./Documents/metin.txt
./sayi.txt
./metin2.txt
./hello.txt
./Desktop/test.txt
./Pictures/Screenshot_2023-05-30_10_28_23.webp
./Pictures/Screenshot_2023-05-24_11_11_16.webp
./Pictures/Screenshot_2022-07-03_06_45_05.webp
./Pictures/Screenshot_2023-05-30_13_21_21.webp
./Pictures/Screenshot_2022-07-03_06_45_04.webp
./Pictures/Screenshot_2022-07-03_06_45_03.webp
./Pictures/Screenshot_2022-06-30_03_23_40.webp
./Pictures/Screenshot_2023-05-30_10_28_26.webp
./Pictures/Screenshot_2023-05-30_10_28_19.webp
./Pictures/Screenshot_2022-06-17_13_15_28.webp
./Pictures/Screenshot_2022-07-03_06_45_02.webp
./Pictures/Screenshot_2022-06-17_13_15_26.webp
./Pictures/Screenshot_2023-05-28_10_42_36.webp
./Pictures/Screenshot_2022-07-03_06_45_24.webp
./karisik.txt
./liste2.txt
Bakın tam da beklediğimiz gibi koşul çalıştı ve “.txt” ile veya “.webp” biten dosyaları aldık.
-and koşuluna bir örnek vermemiz gerekirse örneğin sonu “.webp” ile biten ve 100 kilobayttan büyük olanları filtrelemeyi deneyebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ find -name "*.webp" -and -size +100k
./Pictures/Screenshot_2023-05-30_10_28_23.webp
./Pictures/Screenshot_2023-05-24_11_11_16.webp
./Pictures/Screenshot_2022-07-03_06_45_05.webp
./Pictures/Screenshot_2023-05-30_13_21_21.webp
./Pictures/Screenshot_2022-07-03_06_45_04.webp
./Pictures/Screenshot_2022-07-03_06_45_03.webp
./Pictures/Screenshot_2022-06-30_03_23_40.webp
./Pictures/Screenshot_2023-05-30_10_28_26.webp
./Pictures/Screenshot_2023-05-30_10_28_19.webp
./Pictures/Screenshot_2022-06-17_13_15_28.webp
./Pictures/Screenshot_2022-07-03_06_45_02.webp
./Pictures/Screenshot_2022-06-17_13_15_26.webp
./Pictures/Screenshot_2022-07-03_06_45_24.webp
Bakın isim ve boyut filtreleri arasında kullanmış olduğumuz -and seçeneği sayesinde bu iki filtreyi birbirine bağlayıp hem “.webp” ile biten hem de boyutu 100 kilobayttan büyük olanları filtrelemiş olduk.
İşte siz de bu şekilde spesifik olarak aradığınız özelliklere uyan filtremeler yapmak için bu koşul seçeneklerini kullanabilirsiniz.
find Üzerinde Regex KullanımıNormalde find komutu biz aksini -regex seçeneği ile belirtmediğimiz sürece daha önce kabuk genişletmeleri bölümünde ele aldığımız “wildcards” yaklaşımını kullanıyor. Yani biz -name seçeneğini kullandığımızda isimler aslında “wildcards” kuralları dahilinde değerlendiriliyor.
Örneğin find -name "*.webp" komutunu kullandığımda, mevcut bulunduğum dizin altında başında herhangi bir karakter olan devamındaki “.webp” ifadesi yer alan tüm dosya ve klasörler getiriliyor. Dosya ismi genişletmesinden bahsederken benzer örnekler yapmıştık hatırlarsanız.
┌──(taylan@linuxdersleri)-[~]
└─$ find -name "*.webp"
./.cache/thumbnails/large/3ab698ceca6c7925eb3d1b884a26e75d.webp
./.cache/thumbnails/large/c338c09e4cee3d0a205c77d2888f0fc0.webp
./.cache/thumbnails/large/52e5c5b7a8eaeca56e0bf2634080a8f3.webp
./.cache/thumbnails/large/b3fe8ef292b398b5ff2b48953a2dcaa3.webp
./.cache/thumbnails/large/601fa98430e31526893c2cd4c497fb77.webp
./.cache/thumbnails/large/e0142d1bb7807691d1f3c6fbef0db9d6.webp
./.cache/thumbnails/large/4d47671573280bf1e30ef346ecd154ed.webp
./.cache/thumbnails/normal/4ef1aeb4f74b05b642089a3fa725f6ff.webp
./.cache/thumbnails/normal/fd024d11882b348b20550093e6339f54.webp
./.cache/thumbnails/normal/ce9a4aafaf687c2389abce167751da5e.webp
./.cache/thumbnails/normal/b229cfc54c3672c84da5bfb87f3c7ec9.webp
./.cache/mozilla/firefox/d5n1etpa.default-esr/thumbnails/b8d33cbd34677070b8b70079044c40aa.webp
./.cache/sessions/thumbs-taylan:0/Default.webp
./Pictures/Screenshot_2023-05-30_10_28_23.webp
./Pictures/Screenshot_2023-05-24_11_11_16.webp
./Pictures/Screenshot_2022-07-03_06_45_05.webp
./Pictures/Screenshot_2023-05-30_13_21_21.webp
./Pictures/Screenshot_2022-07-03_06_45_04.webp
./Pictures/Screenshot_2022-07-03_06_45_03.webp
./Pictures/Screenshot_2022-06-30_03_23_40.webp
./Pictures/Screenshot_2023-06-17_06_27_08.webp
./Pictures/Screenshot_2023-05-30_10_28_26.webp
./Pictures/Screenshot_2023-05-30_10_28_19.webp
./Pictures/Screenshot_2022-06-17_13_15_28.webp
./Pictures/Screenshot_2022-07-03_06_45_02.webp
./Pictures/Screenshot_2022-06-17_13_15_26.webp
./Pictures/Screenshot_2023-05-28_10_42_36.webp
./Pictures/Screenshot_2022-07-03_06_45_24.webp
Eğer buradaki “*.webp” ifadesi wildcards olarak ele alınmıyor olsaydı bu çıktıyı alamayacaktık. Denemek için aynı ifadeyi bu kez -regex seçeneği ile deneyelim.
┌──(taylan@linuxdersleri)-[~]
└─$ find -name "*.webp"
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın herhangi bir çıktı alamadık çünkü regex kuralları gereği yıldız işareti kendisinden önceki karakteri sıfır veya daha fazla kez tekrar ediyor. Fakat burada yıldız karakterinden önce bir karakter bulunmadığı için regex kurallarına göre tekrar eden bir örüntü tanımlaması da yapılmamış oluyor. Regex ile bu filtrelemeyi yapmak için “.*.webp” ifadesini kullanabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ find -regex ".*.webp"
./.cache/thumbnails/large/3ab698ceca6c7925eb3d1b884a26e75d.webp
./.cache/thumbnails/large/c338c09e4cee3d0a205c77d2888f0fc0.webp
./.cache/thumbnails/large/52e5c5b7a8eaeca56e0bf2634080a8f3.webp
./.cache/thumbnails/large/b3fe8ef292b398b5ff2b48953a2dcaa3.webp
./.cache/thumbnails/large/601fa98430e31526893c2cd4c497fb77.webp
./.cache/thumbnails/large/e0142d1bb7807691d1f3c6fbef0db9d6.webp
./.cache/thumbnails/large/4d47671573280bf1e30ef346ecd154ed.webp
./.cache/thumbnails/normal/4ef1aeb4f74b05b642089a3fa725f6ff.webp
./.cache/thumbnails/normal/fd024d11882b348b20550093e6339f54.webp
./.cache/thumbnails/normal/ce9a4aafaf687c2389abce167751da5e.webp
./.cache/thumbnails/normal/b229cfc54c3672c84da5bfb87f3c7ec9.webp
./.cache/mozilla/firefox/d5n1etpa.default-esr/thumbnails/b8d33cbd34677070b8b70079044c40aa.webp
./.cache/sessions/thumbs-taylan:0/Default.webp
./Pictures/Screenshot_2023-05-30_10_28_23.webp
./Pictures/Screenshot_2023-05-24_11_11_16.webp
./Pictures/Screenshot_2022-07-03_06_45_05.webp
./Pictures/Screenshot_2023-05-30_13_21_21.webp
./Pictures/Screenshot_2022-07-03_06_45_04.webp
./Pictures/Screenshot_2022-07-03_06_45_03.webp
./Pictures/Screenshot_2022-06-30_03_23_40.webp
./Pictures/Screenshot_2023-06-17_06_27_08.webp
./Pictures/Screenshot_2023-05-30_10_28_26.webp
./Pictures/Screenshot_2023-05-30_10_28_19.webp
./Pictures/Screenshot_2022-06-17_13_15_28.webp
./Pictures/Screenshot_2022-07-03_06_45_02.webp
./Pictures/Screenshot_2022-06-17_13_15_26.webp
./Pictures/Screenshot_2023-05-28_10_42_36.webp
./Pictures/Screenshot_2022-07-03_06_45_24.webp
Bakın bu kez “.webp” uzantılı dosyaları bulabildik. Çünkü yıldız işaretinden önce kullandığımız nokta işareti herhangi bir tek karakteri temsil ediyor, dolayısıyla yıldız işareti de sıfır veya daha fazla sayıda herhangi bir karakteri barındıran ifadeleri kapsamış oluyor.
Wildcards ve Regex farkını özetleyecek olursak;
Dosya ismi genişletmesi kuralına göre yıldız karakteri: sıfır veya sıfırdan daha fazla sayıda herhangi bir karakter ile eşleşebiliyor.
Regex kuralına göre yıldız karakteri: kendisinden önceki karakteri sıfır veya daha fazla sayıda tekrar eden örüntüler ile eşleşebiliyor.
Aldığımız çıktılardaki değişimler de tam olarak bu farklardan kaynaklanıyor.
Örnekler üzerinden bizzat teyit ettiğimiz gibi biz aksini -regex seçeneği ile belirtmediğimiz sürece -name seçeneği wildcards kuralları dahilinde filtreleme yapılmasını sağlıyor.
Tamamdır, benim find komutu hakkında bahsetmek istediğim tüm temel bilgiler bu şekilde. Tabii ki yardım sayfasından da görebileceğimiz gibi aslında find aracının çok daha fazla özelliği mevcut ancak temel seviye için ilk aşamada bunların hepsi fazla gelebilir. Ayrıca tüm seçeneklere sürekli ihtiyacınız da olmayacak. İhtiyaç duydukça yardım sayfalarını açıp bakmakta özgürsünüz.
Ben şimdi araştırma yapma konusunda bir diğer alternatifimiz olan locate aracından bahsederek devam etmek istiyorum.
locate Komutulocate komutu sayesinde sistemdeki dosya ve dizinleri isimleriyle araştırabiliyoruz.
locate komutu daha önce ele aldığımız find aracından farklı olarak araştırma işlemi sırasında tüm dosya sistemine değil daha önceden oluşturulmuş veri tabanını kullanıyor. Bu sayede veri tabanı üzerinden yaptığımız araştırmada, find aracından çok daha hızlı şekilde sonuç verebiliyor.
Aracımızın en temel kullanımı locate aranacak-isim şeklinde. Fakat dediğim gibi locate aracı kendisine ait olan veritabanı üzerinden araştırma yaptığı için araştırmalarımız sırasında daha sağlıklı çıktılar elde edebilmek adına bu veritabanını güncellememiz gerekiyor.
Ben hemen test etmek için bir önceki derste find aracıyla bulmak için oluşturduğum farklı konumlardaki “bulbeni” isimli dosya ve klasörleri locate bulbeni komutuyla sorgulamak istiyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ locate bulbeni
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın herhangi bir çıktı almadık. Biz bu dosya ve klasörü yeni oluşturduğumuz için locate aracının kullandığı veritabanına bu dosya ve klasörün dizin adresi eklenmedi. Dolayısıyla bu isimde bir eşleşme olmadı.
locate Veritabanını Güncellemek | updatedblocate veritabanını güncellemek için sudo updatedb şeklinde komutumuzu girebiliriz. İşlemi yetkili olarak gerçekleştirdiğimiz için parolamızı girip anlayamamız gerek. Ayrıca yeni dizinlerin eklenmesini de bir süre beklememiz gerek.
┌──(taylan@linuxdersleri)-[~]
└─$ sudo updatedb
[sudo] password for taylan:
┌──(taylan@linuxdersleri)-[~]
└─$
Şimdi dosya sistemindeki en son değişikliklerin veritabanına eklenmiş olması gerekiyor. Tekrar etmek için locate bulbeni şeklinde komutumuzu girebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ locate bulbeni
/home/taylan/Documents/bulbeni
/home/taylan/Pictures/bulbeni
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın bu kez anında aradığım kelimeyle eşleşen dosya ve dizinlerin adresi konsola bastırıldı. Bizzat sizin de deneyimleyebileceğiniz gibi locate aracı hızlı çalışıyor olmasına rağmen, veritabanı updatedb komutu ile güncellenmediyse sistemde mevcut olan yeni dosya ve dizinleri bulamıyor. Dolayısıyla locate aracını kullanmadan önce sağlıklı çıktılar almak istiyorsanız mutlaka updatedb komutuyla güncelleme yapın. Normalde her gün düzenli olarak bu veritabanı otomatik olarak güncelleniyor ancak dediğim gibi kullanmadan önce stabil çıktılar istiyorsanız updatedb komutunu çalıştırmanız şart.
Eğer aradığınız dosya isminde küçük büyük harf duyarlığının görmezden gelinmesini isterseniz komutunuza i seçeneğini de ekleyebilirsiniz.
Ben denemek için locate ABC şeklinde yazıp içerisinde tamamı büyük harflerden oluşan ABC karakterlerini barından dosya ve klasör isimlerini listelemek istiyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ locate ABC
/home/taylan/ABC
/home/taylan/.cache/mozilla/firefox/d5n1etpa.default-esr/cache2/entries/1F001ABC732598300E8297AC686A75B32E5186EB
Bakın buradaki çıktıların hepsinde yalnızca tamamı büyük olan ABC ifadesi geçiyor. Eğer küçük büyük harf duyarlılığını kaldırmak istersek komutumuzu tekrar çağırıp i seçeneğini ekleyebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ locate -i ABC
/home/taylan/ABC
/home/taylan/AbC
/home/taylan/aBc
/home/taylan/abc
/home/taylan/.cache/go-build/0d/0d0abc24b077b8fe4a2db64ca931edc2ed3107a8d4c35f0e230f762e70514359-a
ℹ️ Not: Çıktılar kısaltılarak verilmiştir.
Bakın bu kez küçük büyük harf fark etmeksizin tüm dosya ve klasörler listelenmiş oldu.
Kaç eşleşme olduğun saymak istersek “count” yani “saymak” ifadesinin kısaltmasından gelen c seçeneğini ekleyebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ locate -ic ABC
142
┌──(taylan@linuxdersleri)-[~]
└─$ locate -c ABC
17
Gördüğünüz gibi harf duyarlılığı olamadan arma yaptığımızda 142 eşleşme olurken, harf duyarlılığı varken yalnızca 17 eşleşme bulunmuş.
locate Üzerinde Regex Kullanımılocate aracında regex kullanmak istediğimizde bunu özellikle —regex seçeneğiyle belirtmemiz gerekiyor. Ben denemek için öncelikle locate "(\.rar|\.zip)” şeklinde regex tanımıyla eşleşme sağlamak üzere komutumu giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ locate "(\.rar|\.zip)"
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın herhangi bir çıktı almadık çünkü regex çalışmadı. Bu girmiş olduğumuz tanımın özellikle genişletilmiş regex kuralları dahilinde değerlendirilmesi için —regex seçeneğini eklememiz gerekiyor.
┌──(taylan@linuxdersleri)-[~]
└─$ locate --regex "(\.rar|\.zip)"
/home/taylan/Downloads/linux.zip
/usr/lib/jvm/java-11-openjdk-amd64/legal/jdk.zipfs
/usr/lib/jvm/java-11-openjdk-amd64/legal/jdk.zipfs/ASSEMBLY_EXCEPTION
/usr/share/exploitdb/exploits/windows/remote/17419.zip
/usr/share/icons/Flat-Remix-Blue-Dark/mimetypes/scalable/application-vnd.rar.svg
/usr/share/mime/application/vnd.rar.xml
/usr/share/powershell-empire/empire/server/csharp/Covenant/Data/EmbeddedResources/Lib.zip
/usr/share/powershell-empire/empire/server/data/misc/python_modules/keyboard.zip
/usr/share/powershell-empire/empire/server/data/misc/python_modules/mss.zip
/usr/share/set/src/teensy/x10/libraries.zip
Bakın bu kez tam olarak isminin herhangi bir noktasında “.rar” veya “.zip” geçen tüm içerikler bastırılmış oldu. Ayrıca mesela locate —help komutuyla bir bakacak olursak:
Bakın genişletilmiş regex kuralları için —regex kullanırken, basit regex kuralları için de -r veya —regexp seçeneğini kullanabileceğimiz belirtilmiş. Ben aynı örneği basit regex üzerinden denemek istiyorum
┌──(taylan@linuxdersleri)-[~]
└─$ locate -r "(\.rar\|\.zip)"
┌──(taylan@linuxdersleri)-[~]
└─$
Komutu doğru girmiş olmama karşın herhangi bir çıktı almadım. Bunun sebebi locate aracının yalnızca Posix regex kurallarını destekliyor olması. Posix basit regex tanımında | metakarakteri bulunmadığı için locate aracını bu karakteri tanımadı. Dolayısıyla bir eşleşme de sağlanamadı. İşte tıpkı bu örneğimizde gördüğümüz gibi araçların regex kurallarını tanıma ve işleme noktasında bu gibi farklara sahip olabileceğinin farkında olmanız gerekiyor.
Tamamdır en nihayetinde benim locate aracı hakkında bahsetmek istediklerim bunlar. Son olarak locate ile find arasındaki farkı vurgulamak istiyorum.
locate ve find Arasındaki Farkfind komutu ile dosyaları özniteliklerine göre filtreleyebildiğiniz için çok daha fazla seçeneğe sahibiz. Zaten find komutunu ele alırken dosyaların çeşitli özelliklerine göre nasıl filtreleme yapabileceğimizi ele aldık. locate komutu ise yalnızca kendi veritabanındaki dosya isimleri ile eşleşme var mı diye kontrol ettiği için, find komutu ile kullanabileceğiniz dosya özelliklerini filtreleme gibi işlevleri locate aracında kullanamazsınız.
Yalnızca dosya isimleri üzerinden hızlıca araştırma yapmak istiyorsanız locate aracını kullanabilirsiniz. Tabii ki araştırmadan önce updatedb komutuyla veritabanını güncellemeyi de unutmamız gerekiyor.
Eğer o anda sistemdeki spesifik bir dosya veya klasör hakkında araştırma yapmak istiyorsanız da find aracını kullanabilirsiniz. find aracı mevcut dosya sistemi üzerinde araştırma yaptığı için locate gibi bir statik veriler ile çalışmadan en güncel bilgileri filtreli şekilde sunabiliyor.
cut Komutucut komutu, satırların istenilen bölümlerinin kesilmesini sağlıyor. Zaten isminde geçen “cut” ifadesi Türkçe olarak “kesmek” anlamına geliyor. Ben örnekler sırasında basit bir metin dosyası üzerinde çalışıyor olacağım ancak siz okunabilir formatta olan tüm metinsel verilerinizi cut komutu ile kesip biçimlendirebilirsiniz.
Öncelikle dosya içeriğini cat komutu ile görüntüleyelim.
┌──(taylan@linuxdersleri)-[~]
└─$ cat metin
satir1sutun1 satir1sutun2 satir1sutun3 satir1sutun4 satir1sutun5
satir2sutun1 satir2sutun2 satir2sutun3 satir2sutun4 satir2sutun5
satir3sutun1 satir3sutun2 satir3sutun3 satir3sutun4 satir3sutun5
satir4sutun1 satir4sutun2 satir4sutun3 satir4sutun4 satir4sutun5
satir5sutun1 satir5sutun2 satir5sutun3 satir5sutun4 satir5sutun5
satir6sutun1 satir6sutun2 satir6sutun3 satir6sutun4 satir6sutun5
satir7sutun1 satir7sutun2 satir7sutun3 satir7sutun4 satir7sutun5
satir8sutun1 satir8sutun2 satir8sutun3 satir8sutun4 satir8sutun5
Şimdi cut aracının kullanımına geçecek olursak, örneğin ben bu dosyadaki tüm sütunları değil de yalnızca 1 ila 3. sütunları istiyorsam cut komutuna bu durumu izah edebilirim. Bu işlem için cut komutuna bu verileri neye bakarak ayıracağını bildirmemiz gerekiyor. Tıpkı kabuğun komutları yorumlaması gibi cut aracı da elindeki verilerin hangi parçalardan oluştuğunu anlamak için bir “delimiter” yani “sınırlayıcı” karakter belirtmemizi istiyor. Bunun için cut komutundan sonra -d seçeneğinin hemen ardından sınırlayıcı karakteri yazmamız gerek.
Örneğin benim dosyamda boşluk karakteri sütunları birbirinden ayırdığı için ben tırnak için “ “ boşluk karakterinin sınırlayıcı olduğunu belirteceğim. Şimdi son olarak hangi sütunların, yani aslında hangi bölümlerin kalmasını istiyorsak, bunu “fields” yani “alanlar-bölümler” seçeneğinin kısalması olan -f seçeneğinin hemen ardından belirtebiliyoruz. Ben 1 ila 3. bölümleri almak istediğim için 1-3 şeklinde yazıyorum ve işlenecek verilerin bulunduğu dosyanın ismini de ekleyip komutumu onaylıyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ cut -d " " -f 1-3 metin
satir1sutun1 satir1sutun2 satir1sutun3
satir2sutun1 satir2sutun2 satir2sutun3
satir3sutun1 satir3sutun2 satir3sutun3
satir4sutun1 satir4sutun2 satir4sutun3
satir5sutun1 satir5sutun2 satir5sutun3
satir6sutun1 satir6sutun2 satir6sutun3
satir7sutun1 satir7sutun2 satir7sutun3
satir8sutun1 satir8sutun2 satir8sutun3
Bakın yalnızca 1. den 3. bölüme kadar olan sütunlar bastırıldı. cut komutu ona söylediğimiz gibi dosya içeriğini okuyup dosyadaki boşluk karakterinin bulunduğu tüm bölümleri birbirinden ayırdı ve bizim belirttiğimiz bölümleri de filtreleyip bize sundu. Burada önemli olan, bölümleri birbirinden ayıran boşluk karakterinin cut komutuna bildirilmesi. Hatta bu durumda emin olmak için ben aynı içeriğin boşluk yerine virgüllerle ayrılmış sürümü üzerinden cut komutunu tekrar kullanmak istiyorum. Öncelikle dosya içeriğini kontrol etmek için cat komutu ile virgüllü dosyayı okuyalım.
┌──(taylan@linuxdersleri)-[~]
└─$ cat metin2
satir1sutun1;satir1sutun2;satir1sutun3;satir1sutun4;satir1sutun5
satir2sutun1;satir2sutun2;satir2sutun3;satir2sutun4;satir2sutun5
satir3sutun1;satir3sutun2;satir3sutun3;satir3sutun4;satir3sutun5
satir4sutun1;satir4sutun2;satir4sutun3;satir4sutun4;satir4sutun5
satir5sutun1;satir5sutun2;satir5sutun3;satir5sutun4;satir5sutun5
satir6sutun1;satir6sutun2;satir6sutun3;satir6sutun4;satir6sutun5
satir7sutun1;satir7sutun2;satir7sutun3;satir7sutun4;satir7sutun5
satir8sutun1;satir8sutun2;satir8sutun3;satir8sutun4;satir8sutun5
Bakın buradaki tüm bölümler virgülle birbirinden ayrılmış durumda. Şimdi biz bu verileri kesmek istersek virgüllerin sınırlayıcı değer olduğunu özellikle belirtmemiz gerekiyor. Bu durumu bizzat teyit etmek için virgülü belirtmeden önceki komutumuzu yani boşluk karakterini sınırlayıcı olarak belirttiğimiz komutumuzu bu dosya üzerinde de uygulamayı deneyebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ cut -d " " -f 1-3 metin2
satir1sutun1;satir1sutun2;satir1sutun3;satir1sutun4;satir1sutun5
satir2sutun1;satir2sutun2;satir2sutun3;satir2sutun4;satir2sutun5
satir3sutun1;satir3sutun2;satir3sutun3;satir3sutun4;satir3sutun5
satir4sutun1;satir4sutun2;satir4sutun3;satir4sutun4;satir4sutun5
satir5sutun1;satir5sutun2;satir5sutun3;satir5sutun4;satir5sutun5
satir6sutun1;satir6sutun2;satir6sutun3;satir6sutun4;satir6sutun5
satir7sutun1;satir7sutun2;satir7sutun3;satir7sutun4;satir7sutun5
satir8sutun1;satir8sutun2;satir8sutun3;satir8sutun4;satir8sutun5
Bakın herhangi bir kesme işlemi uygulanmadı. Şimdi buradaki “delimiter” yani “sınırlayıcı” karakteri olarak tırnak içine noktalı virgül karakterini ekleyip komutumuzu bu şekilde çalıştıralım.
┌──(taylan@linuxdersleri)-[~]
└─$ cut -d ";" -f 1-3 metin2
satir1sutun1;satir1sutun2;satir1sutun3
satir2sutun1;satir2sutun2;satir2sutun3
satir3sutun1;satir3sutun2;satir3sutun3
satir4sutun1;satir4sutun2;satir4sutun3
satir5sutun1;satir5sutun2;satir5sutun3
satir6sutun1;satir6sutun2;satir6sutun3
satir7sutun1;satir7sutun2;satir7sutun3
satir8sutun1;satir8sutun2;satir8sutun3
Bakın noktalı virgül karakteri sayesinde birbirinden ayrıştırılan bölümler cut komutu tarafından işlenip tam olarak istediğim bölüm aralığı sunuldu. Bu örnek üzerinden de görebildiğimiz gibi elimizdeki verinin türüne göre sınırlayıcı olan değeri doğru şekilde belirtmezsek, kesme işlemi de uygulanamıyor.
Eğer bir aralığı değil de spesifik olarak listelemek istediğiniz sütunlar varsa -f seçeneğinden sonra virgülle ayırarak belirtebilirsiniz.
┌──(taylan@linuxdersleri)-[~]
└─$ cut -d ";" -f 1,4 metin2
satir1sutun1;satir1sutun4
satir2sutun1;satir2sutun4
satir3sutun1;satir3sutun4
satir4sutun1;satir4sutun4
satir5sutun1;satir5sutun4
satir6sutun1;satir6sutun4
satir7sutun1;satir7sutun4
satir8sutun1;satir8sutun4
┌──(taylan@linuxdersleri)-[~]
└─$ cut -d ";" -f 4 metin2
satir1sutun4
satir2sutun4
satir3sutun4
satir4sutun4
satir5sutun4
satir6sutun4
satir7sutun4
satir8sutun4
Bakın tam olarak belirttiğim bölümler karşıma getirildi.
Aslında cut komutun başka seçenekleri de bulunuyor ancak diğer seçeneklerin detaylarına girmeyi düşünmüyorum. Zaten temel çalışma yapısını anladığınız için cut —help komutu ile elde edeceğiniz buradaki tüm açıklamaları rahatlıkla anlayıp uygulayarak test edebilirsiniz.
┌──(taylan@linuxdersleri)-[~]
└─$ cut --help
Usage: cut OPTION... [FILE]...
Print selected parts of lines from each FILE to standard output.
With no FILE, or when FILE is -, read standard input.
Mandatory arguments to long options are mandatory for short options too.
-b, --bytes=LIST select only these bytes
-c, --characters=LIST select only these characters
-d, --delimiter=DELIM use DELIM instead of TAB for field delimiter
-f, --fields=LIST select only these fields; also print any line
that contains no delimiter character, unless
the -s option is specified
-n (ignored)
--complement complement the set of selected bytes, characters
or fields
-s, --only-delimited do not print lines not containing delimiters
--output-delimiter=STRING use STRING as the output delimiter
the default is to use the input delimiter
-z, --zero-terminated line delimiter is NUL, not newline
--help display this help and exit
--version output version information and exit
Use one, and only one of -b, -c or -f. Each LIST is made up of one
range, or many ranges separated by commas. Selected input is written
in the same order that it is read, and is written exactly once.
Each range is one of:
N N'th byte, character or field, counted from 1
N- from N'th byte, character or field, to end of line
N-M from N'th to M'th (included) byte, character or field
-M from first to M'th (included) byte, character or field
GNU coreutils online help: <https://www.gnu.org/software/coreutils/>
Full documentation <https://www.gnu.org/software/coreutils/cut>
or available locally via: info '(coreutils) cut invocation'
Örneğin bakın “complement” seçeneği, bizim belirttiğimiz bölümlerin haricindeki bölümleri bastıran bir seçenekmiş. Bu durumu görmek için en son girdiğimiz komutu tekrar girelim.
┌──(taylan@linuxdersleri)-[~]
└─$ cut -d ";" -f 1,4 metin2
satir1sutun1;satir1sutun4
satir2sutun1;satir2sutun4
satir3sutun1;satir3sutun4
satir4sutun1;satir4sutun4
satir5sutun1;satir5sutun4
satir6sutun1;satir6sutun4
satir7sutun1;satir7sutun4
satir8sutun1;satir8sutun4
┌──(taylan@linuxdersleri)-[~]
└─$ cut -d ";" -f 1,4 metin2 --complement
satir1sutun2;satir1sutun3;satir1sutun5
satir2sutun2;satir2sutun3;satir2sutun5
satir3sutun2;satir3sutun3;satir3sutun5
satir4sutun2;satir4sutun3;satir4sutun5
satir5sutun2;satir5sutun3;satir5sutun5
satir6sutun2;satir6sutun3;satir6sutun5
satir7sutun2;satir7sutun3;satir7sutun5
satir8sutun2;satir8sutun3;satir8sutun5
Bakın ilk komutta tam olarak belirttiğimiz bölümler bastırılırken, “—complement” seçeneğini kullandığımızda belirttiğimiz bölümlerin haricindekiler bastırıldı.
İşte bu şekilde sütunları filtrelemek istediğimizde yani istediğimiz sütunları kesmek istediğimizde cut aracını kullanabiliyoruz. Diğer özellikleri için aynen burada olduğu gibi yardım sayfasına ya da internet üzerindeki harici kaynaklara bakabilirsiniz. Fakat temelde sütunları kesmek için bizim bahsetmiş olduklarımız yeterli.
tr Komututr komutunun ismi “translate” yani “çevirmek-dönüştürmek” ifadesinden geliyor. Temelde mevcut veriler içindeki karakterleri değiştirmek veya silmek için bu aracımızı kullanabiliyoruz. Küçük ve büyük harf değişimi, tekrar eden karakterlerin silinmesi, özel karakterlerin silinmesi ve bulup değiştirme gibi pek çok işlevi var. Biz temel birkaç işlevinden bahsediyor olacağız.
tr komutu standart girdiden veri okuduğu için pipe ile veri aktarmak en sık tercih edilen kullanım yöntemidir. Ben kolay bir örnek olması için küçük “i” ve küçük “e” karakterlerini büyükleri ile değiştirmek üzere echo "linux dersleri" | tr "ie" "IE" şeklinde komutumu giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "linux dersleri" | tr "ie" "IE"
lInux dErslErI
Burada girmiş olduğum argümanların sıralaması çok önemli. Çünkü tr komutu sıralamaya uyarak yani ilk argümanın ilk karakterini, ikinci argümanın ilk karakteri ile ve ilk argümanın ikinci karakterini de ikinci argümanın ikinci karakteri ile değişecek şekilde işlem yapıyor.
Zaten aldığımız çıktı da, belirtmiş olduğumuz sırlamaya uyuyor. Şimdi sıralamayı değiştirip deneyelim.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "linux dersleri" | tr "ie" "EI"
lEnux dIrslIrE
Bakın bu çıktı da komutta belirttiğim sırlama dahilinde yani küçük “i” için büyük “E” küçük “e” için de büyük “I” karakteri şeklinde oldu.
Örneğin tüm küçük harfleri büyük harflere dönüştürmek istersek aralık belirterek komut girebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "linux dersleri" | tr "a-z" "A-Z"
LINUX DERSLERI
Bakın tüm karakterler büyükleri ile otomatik olarak yer değiştirdi.
Ayrıca kullanabileceğimiz bazı özel kalıplar da bulunuyor. Bunları görmek için tr —help komutunu kullanabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ tr --help
Usage: tr [OPTION]... SET1 [SET2]
Translate, squeeze, and/or delete characters from standard input,
writing to standard output.
-c, -C, --complement use the complement of SET1
-d, --delete delete characters in SET1, do not translate
-s, --squeeze-repeats replace each sequence of a repeated character
that is listed in the last specified SET,
with a single occurrence of that character
-t, --truncate-set1 first truncate SET1 to length of SET2
--help display this help and exit
--version output version information and exit
SETs are specified as strings of characters. Most represent themselves.
Interpreted sequences are:
\NNN character with octal value NNN (1 to 3 octal digits)
\\ backslash
\a audible BEL
\b backspace
\f form feed
\n new line
\r return
\t horizontal tab
\v vertical tab
CHAR1-CHAR2 all characters from CHAR1 to CHAR2 in ascending order
[CHAR*] in SET2, copies of CHAR until length of SET1
[CHAR*REPEAT] REPEAT copies of CHAR, REPEAT octal if starting with 0
[:alnum:] all letters and digits
[:alpha:] all letters
[:blank:] all horizontal whitespace
[:cntrl:] all control characters
[:digit:] all digits
[:graph:] all printable characters, not including space
[:lower:] all lower case letters
[:print:] all printable characters, including space
[:punct:] all punctuation characters
[:space:] all horizontal or vertical whitespace
[:upper:] all upper case letters
[:xdigit:] all hexadecimal digits
[=CHAR=] all characters which are equivalent to CHAR
Gördüğünüz gibi Linux üzerinde regex kullanımından bahsederken ele aldığımız bazı sembolik ifadeler de dahil, kullanabileceğimiz çeşitli özel karakterler yardım bilgisinde belirtilmiş. Örneğin bakın buradaki [:lower:] kalıbı küçük harfli olan tüm karakterleri kapsıyor, benzer şekilde [:upper:] da tüm büyük harfleri kapsıyor. Denemek için gelin bu kalıpları kullanarak küçük harfleri tekrar büyüğe dönüştürelim.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "linux dersleri" | tr [:lower:] [:upper:]
LINUX DERSLERI
Gördüğünüz gibi tüm küçük harfli karakterler büyük harfler ile değiştirilmiş oldu. Tabii ki istersek tersi şekilde komut girerek, büyük harflerin küçük harfler ile değiştirilmesini de sağlayabiliriz. Sizler de bu listeye göz atıp, ihtiyacınız olan kalıpları kolayca kullanabilirsiniz.
Bir örnek daha yapalım ben PATH değişkenin çıktıların yer alan iki nokta karakterini yeni satır karakteri ile değiştirmek istiyorum. Öncelikle standart şekilde nasıl göründüğüne bakmak için echo $PATH komutu ile değişkeni konsola bastıralım.
taylan@virtualbox:~/arsiv$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
Bakın PATH yoluna ekli olan her bir dizin birbirinden iki nokta üst üste karakteri ayrılmış. Şimdi bu çıktı bana biraz karışık geldiği için her bir PATH dizinini yeni bir satırda görmek istiyorum. Bunu yapmak için iki nokta üst üste karakterini yeni satır karakteri ile yani yardım listesinde de görülen \n karakteri ile değiştirebiliriz. Hemen deneyelim. Ben komutumu echo $PATH | tr “:” “\n” şeklinde giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ echo $PATH | tr ":" "\n"
/usr/local/sbin
/usr/local/bin
/usr/sbin
/usr/bin
/sbin
/bin
/usr/local/games
/usr/games
/home/taylan/Desktop/yeni-dizin
Bakın, her bir PATH dizinini ayrı ayrı satırlarda bastırmayı başardık. Bu şekilde tam istediğim gibi daha okunaklı bir çıktı elde etmiş oldum. Bence bu yaptığımız örnek, tr aracının kullanımına ve ayrıca yeni satıra geçilmesini sağlayan \n gibi kalıplara da iyi bir örnek oldu.
Yardım çıktısında yer alan buradaki kalıplar üzerinde pratik yaptığınız zaman zaten kolay hatırlanır isimleri dolayısıyla kolayca anımsayıp bu kalıplardan faydalanabilirsiniz. Ayrıca hatırlamadığınız durumda tabii ki yardım sayfası üzerinden de tekrar öğrenebilirsiniz. Zaten pek çok araç zaten benzer standardı izlediği için zaman içinde bu tür kalıplar aklınızda yer edecektir.
Bu ifadeler dışında biraz da seçeneklerinden bahsedebiliriz.
Eğer peş peşe tekrar eden karakterlerden yalnızca bir tane kalmasını istersek, -s seçeneğini kullanabiliriz. Buradaki s seçeneği “squeeze” yani “sıkmak”, sıkıştırmaktan aklınıza gelebilir. Ben denemek için www.linuxdersleri.net adresindeki “www” karakterlerini teke indirmek istiyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "www.linuxdersleri.net" | tr -s "w"
w.linuxdersleri.net
Bakın “w” karakteri teke düşürüldü.
Hatta istersem bastırılabilir olan tüm tekrar eden karakterlerin otomatik olarak filtrelenmesi için bu tür karakterleri temsil eden [:graph:] seçeneğini kullanabilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "bbu biirrr deneeeme33344 yazısı123" | tr -s [:graph:]
bu bir deneme34 yazısı123
Gördüğünüz gibi [:graph:] seçeneği sayesinde bastırılabilir(boşluk hariç, rakam, harf, sembol gibi) karakterleri kapsayıp, bunlar içinde tekrar edenleri teke düşürmek için de -s seçeneğini kullanmış olduk.
Yani bu örnek üzerinden de gördüğümüz gibi aslında spesifik olarak belirtmemiz gereken karakterler yoksa, tr —help komutunun çıktısında yer alan ifadeler ve kalıplar zaten pek çok tanımı karşılıyor. Örneğin yalnızca tekrar eden sayıları mı düzenlemek istiyorsunuz, [:digit:] tanımı kullanılabilir.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "bbu biirrr deneeeme33344 yazısı123##" | tr -s [:digit:]
bbu biirrr deneeeme34 yazısı123##
Bakın [:digit:] kalıbı sayesinde yalnızca peş peşe tekrar eden sayılar teke indirilmiş oldu.
İşte sizler de gerektiğinde yardım sayfasından göz atıp, bu ifadeleri kolayca kullanabilirsiniz.
Her neyse, neticede s seçeneğinin art arda tekrar eden karakterleri teke düşürdüğünü teyit etmiş olduk. Tekrarların peşi sıra gerçekleştiğine dikkat edin.
Doğrudan karakteri bulup silmek için de tr aracını kullanmamız mümkün. Bunun için “delete” yani “silme” ifadesinin kısaltması olan d seçeneğini kullanabiliyoruz. Ben denemek için web adresindeki noktaları silmek istiyorum. Tek yapmam gereken tr aracının -d seçeneğini kullandıktan sonra silinmesini istediğim karakteri belirtmek.
┌──(taylan@linuxdersleri)-[~]
└─$ echo www.linuxdersleri.net | tr -d "."
wwwlinuxderslerinet
Bakın gördüğünüz gibi yalnızca belirttiğim şekilde nokta karakterleri silinmiş. Bu şekilde metin içinde silinmesini istediğiniz tüm karakterleri belirtebiliyoruz. Fakat burada yazdığını karakterlerin yalnızca tek bir karakteri işaret ettiğini unutmayın lütfen. Yani örneğin ben aynı komutta -d seçeneğinden sonra “de” yazarsam, “d” ve “e” karakterinin hepsi bulunup silinecek. Yalnızca bütünleşik olan “de” kalıbını silmeyecek yani. Komutumuzu onaylayalım.
┌──(taylan@linuxdersleri)-[~]
└─$ echo www.linuxdersleri.net | tr -d "de"
www.linuxrslri.nt
Bakın yazdığım tüm karakterler ayrı ayrı ele alındı ve eşleşen karakterler kaldırıldı. Yani doğrudan “de” ifadesini aranmadı, “d” ve “e” karakterleri ayrı ayrı aranıp bulunduğunda teker teker silindiler.
Eğer bitişik yapıdaki birden fazla karakteri kapsayacak değişiklikler istiyorsanız ileride ele alacağımız sed veya awk gibi araçlardan yararlanabilirsiniz. tr aracı yalnızca bir karakter ile başka bir tanesini değiştirme silme veya tekrar edenleri sadeleştirmek gibi işler için kullanılıyor.
Ayrıca son olarak, örneklerimiz sırasında verileri hep pipe üzerinden tr aracına yönlendirdik. İstersek yönlendirme operatörü ile de tr aracının standart girdisine veri aktarmamız da mümkün. Ben peş peşe tekrar eden karakterlerin tr komutu ile teke düşürülmesi için yönlendirme operatörü ile dosyayı tr komutuna aktaracağım.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "bbu biirrr deneeeme33344 yazısı123##" > test
┌──(taylan@linuxdersleri)-[~]
└─$ tr -s [:graph:] < test
bu bir deneme34 yazısı123#
Bakın gördüğünüz gibi yönlendirmiş olduğumuz dosyadaki veri tr komutu tarafından okunup, filtrelenmiş oldu. Yani bizzat teyit ettiğimiz gibi tr komutunu yalnızca pipe ile kullanmak zorunda değiliz. tr aracı verilerini standart girdiden okuyor. Dolayısıyla standart girdisine verileri yönlendirdiğimiz sürece tr aracı ilgili verileri işleyip çıktıları standart çıktıya yani biz aksini belirtmediğimiz sürece konsolumuza yönlendiriyor olacak.
Eğer bu çıktıları bir dosyaya kaydetmek istersek örneğin aynı komutun sonuna > kaydet şeklinde yazabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ tr -s [:graph:] < test > kaydet
┌──(taylan@linuxdersleri)-[~]
└─$ cat kaydet
bu bir deneme34 yazısı123#
Bakın çıktıların “kaydet” isimli dosyaya sorunsuzca yönlendirilmiş olduğunu cat komutu ile de teyit etmiş olduk.
Benim tr aracı hakkında bahsetmek istediklerim bu kadar.
sedsed komutu “stream editor” ifadesinin kısaltmasından gelen metin manipülasyon aracıdır. Daha önce, “her şey bir dosyadadır, her şey bir bayt akışıdır” demiştik. İşte “stream” yani “akış-aktarım” ifadesi de bu bayt akışının manipülasyonu dolayısıyla kullanılmış.
Basit ve genişletilmiş regex kurallarının da yardımıyla sed aracı sayesinde, bulma değiştirme, ekleme, ve silme gibi işlemleri yerine getirebiliyoruz.
Aradığımız ifade ile eşleşenlerin hepsinin değiştirilmesini istersek sed ‘s/bulunacak/degiştirilecek/g’ dosya_ismi şeklinde komutumuzu girmemiz gerek. Buradaki “g” seçeneği “global” yani tüm eşleşmeleri kapsıyor. Ben denemek için bir dosya oluşturup bu dosya üzerinden örnekler vereceğim.
┌──(taylan@linuxdersleri)-[~]
└─$ cat veri
bu ilk satır bu ikinci satır bu da son satır
satır iki ve satır sonu
yeni satır ve son satır
yeni veri ve son veri
Şimdi ben bu dosyada geçen “satır” ifadelerinin hepsini “bölüm” ifadesi ile değiştirmek istiyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ sed 's/satır/bölüm/g' veri
bu ilk bölüm bu ikinci bölüm bu da son bölüm
bölüm iki ve bölüm sonu
yeni bölüm ve son bölüm
yeni veri ve son veri
Gördüğünüz gibi “satır” ifadesini “bölüm” ile değiştirmiş oldum.
Eğer “g” parametresini kullanmazsak yalnızca ilk eşleşme değiştirilecekti.
┌──(taylan@linuxdersleri)-[~]
└─$ sed 's/satır/bölüm/' veri
bu ilk bölüm bu ikinci satır bu da son satır
bölüm iki ve satır sonu
yeni bölüm ve son satır
yeni veri ve son veri
Bakın her bir satırdaki yalnızca ilk eşleşmeler değiştirildi.
Özellikle hangi satırların dahil edileceğini s parametresinden önce belirtebiliriz.
Örneğin ben yalnızca 3. satırı kapsamak istersem 3s şeklinde belirtebilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ sed '3s/satır/bölüm/' veri
bu ilk satır bu ikinci satır bu da son satır
satır iki ve satır sonu
yeni bölüm ve son satır
yeni veri ve son veri
┌──(taylan@linuxdersleri)-[~]
└─$ sed '3s/satır/bölüm/g' veri
bu ilk satır bu ikinci satır bu da son satır
satır iki ve satır sonu
yeni bölüm ve son bölüm
yeni veri ve son veri
Ayrıca birden fazla belirtmemiz de mümkün. Ben 1’den 3. satıra kadar olanları dahil etmek için 1,3s şeklinde giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ sed '1,3s/satır/bölüm/' veri
bu ilk bölüm bu ikinci satır bu da son satır
bölüm iki ve satır sonu
yeni bölüm ve son satır
yeni veri ve son veri
┌──(taylan@linuxdersleri)-[~]
└─$ sed '1,3s/satır/bölüm/g' veri
bu ilk bölüm bu ikinci bölüm bu da son bölüm
bölüm iki ve bölüm sonu
yeni bölüm ve son bölüm
yeni veri ve son veri
Spesifik olarak silmek istediğimiz satırları d seçeneğinden önce belirtebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ cat veri
bu ilk satır bu ikinci satır bu da son satır
satır iki ve satır sonu
yeni satır ve son satır
yeni veri ve son veri
┌──(taylan@linuxdersleri)-[~]
└─$ sed '2d' veri
bu ilk satır bu ikinci satır bu da son satır
yeni satır ve son satır
yeni veri ve son veri
┌──(taylan@linuxdersleri)-[~]
└─$ sed '2,4d' veri
bu ilk satır bu ikinci satır bu da son satır
Eğer aradığımız ifade ile eşleşme sağlanan satırları silmek istersek sed ‘/aranan/d’ şeklinde komutumuzu girebiliriz. Ben denemek için “yeni” ifadesinin geçtiği tüm satırları silmek istiyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ cat veri
bu ilk satır bu ikinci satır bu da son satır
satır iki ve satır sonu
yeni satır ve son satır
yeni veri ve son veri
┌──(taylan@linuxdersleri)-[~]
└─$ sed '/yeni/d' veri
bu ilk satır bu ikinci satır bu da son satır
satır iki ve satır sonu
Bakın “yeni” ifadesi ile eşleşme sağlananlar silinmiş oldu.
Aradığımız ifade ile eşleşen satırlar hariç tüm satırları silmek istersek d parametresinden önce ! ünlem işaretini kullanabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ cat veri
bu ilk satır bu ikinci satır bu da son satır
satır iki ve satır sonu
yeni satır ve son satır
yeni veri ve son veri
┌──(taylan@linuxdersleri)-[~]
└─$ sed '/yeni/!d' veri
yeni satır ve son satır
yeni veri ve son veri
Gördüğünüz gibi “yeni” ifadesiyle eşleşenler hariç tüm satırlar silinmiş oldu.
Eşleşmeden önceki satıra eklemek için i parametresini kullanıyoruz.
┌──(taylan@linuxdersleri)-[~]
└─$ sed '/veri/i\oncesi' veri
bu ilk satır bu ikinci satır bu da son satır
satır iki ve satır sonu
yeni satır ve son satır
oncesi
yeni veri ve son veri
Eşleşmeden sonraki satıra eklemek için a parametresini kullanıyoruz.
┌──(taylan@linuxdersleri)-[~]
└─$ sed '/veri/a\sonrası' veri
bu ilk satır bu ikinci satır bu da son satır
satır iki ve satır sonu
yeni satır ve son satır
yeni veri ve son veri
sonrası
sed komutu kesinlikle burada bahsettiklerimle sınırlı değil fakat ilk aşama için temelde bilmemiz gerekenler bu kadar. Eğer biraz araştırma yapacak olursanız sed aracının aslında script olarak yazılıp metinsel verileri ihtiyaca göre manipüle edebileceğini de göreceksiniz. Fakat ben bu eğitimde daha fazla detaydan bahsetmeyi planlamıyorum. Günlük hayatta da daha fazlasına ihtiyacım olmuyor. Olsa bile internet üzerinden ek olarak ihtiyacıma yönelik araştırma yapıp çözümü uyguluyorum.
awk | gawkawk aracıyla metinsel veriler üzerinde çeşitli manipülasyonlar yapmamız mümkün.
awk aracının pek çok farklı sürümü bulunuyor. Biz GNU awk yani gawk aracını ele alacağız. Pek çok Linux dağıtımında gawk aracı awk komutuna sembolik olarak bağlı. Yani biz awk komutunu giriyoruz ama gawk aracını kullanıyoruz.
awk aracında veriler, kayıtlar(records) ve alanlar(fields) olmak üzere iki parçaya ayrılıyorlar.

awk, girişin sonuna ulaşılana kadar her seferinde bir kayıt üzerinde çalışır. Kayıtlar(records) da, kayıt ayırıcı(Record Separator) adı verilen özel bir karakter sayesinde birbirinden ayrılıyor. Kayıtları birbirinden ayırmak için kullanılan varsayılan karakter de yeni satıra geçiş karakteridir. Dolayısıyla aslında varsayılan olarak awk aracı her bir satırı bir kayıt olarak ele alıyor. Yani awk aracı her seferinde sırasıyla tek bir satır üzerinde çalışıyor. Ben kabaca awk aracının, verileri nasıl ele aldığını aşağıda temsil etmeye çalıştım.

Alanalar(fields) ise boşluk karakteri ile birbirinden ayrılıp, kayıtları(records) oluşturuyor. Her kayıttaki alanlara da dolar işareti ($) ve ardından 1 den başlayan sıralı alan numarası veriliyor. Yani ilk alan $1 ile, ikincisi $2 ile vb. temsil ediliyor. En sondaki alana ise doğrudan $NF özel değişkeni ile ulaşılabiliyor. Tüm alanlara yani aslında kaydın(ilgili satırın) tamamına da $0 değişkeni ile ulaşılabiliyor.
Bu detaylar awk kullanımı için bilmemiz gereken birkaç temel bilgi sadece. Birazdan uygulama yaptıkça buradaki açıklamalar sizin için çok daha anlamlı hale gelecek.
awk Programıawk aslında bir programlama dili gibi, işlenecek veriler için çeşitli programlar yazabilmemize olanak tanıyor. Fakat biz çok temel düzeyde birkaç işlevini ele alacağız. Nasıl programlanabileceğini öğrenmek için kısa bir ek araştırma yapmanız yeterli.
awk aracını kullanmak için gireceğimiz komutlar aşağıdaki gibi olacak.
desen {aksiyon}
Eğer “desen”, kayıt yani satırla eşleşme sağlarsa “aksiyon” olarak belirtilen görev yerine getirilecek. Aksiyonlar, kıvırcık parantez içinde “özel ifadeler” ile birlikte belirtiliyor. İfadeler sayesinde, aksiyonun ne olması gerektiğini belirtebiliyoruz. Awk üzerinde en yaygın kullanıma sahip olan ifade “print” ifadesidir.
print: Kayıtları, alanları, değişkenleri ve özel metni yazdırmamızı sağlar.
Ben örnekler için aşağıdaki veri.txt dosyası üzerinde çalışıyor olacağım.
┌──(taylan㉿linuxdersleri)-[~]
└─$ cat > veri.txt
Ahmet Yaz 33
hasan mert 19
aylin uzun 24
32 mehmet KARA
naz 29 sabah
Her bir satırın ilk bölümünü bastırmak istediğim için awk ‘{ print $1}’ veri.txt şeklinde komutumu giriyorum.
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk '{print $1}' veri.txt
Ahmet
hasan
aylin
32
naz
Bakın awk aracı her bir satırı ayrı ayrı ele aldığı ve $1 parametresi de ilk alanı temsil ettiği için ilk sütunlardaki tüm verileri print ile bastırmış olduk. Burada tek tırnak kullanmamız önemli, çünkü süslü parantezin kabuk tarafından yorumlanmasını istemiyoruz.
Örneğin ben son yani 3. sütundakileri filtrelemek istersem $3 yada sonda olduğu için $NF değişkenini kullanabilirim.
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk '{print $3}' veri.txt
33
19
24
KARA
sabah
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk '{print $NF}' veri.txt
33
19
24
KARA
sabah
Dilersek birden fazla sütun üzerinde de çalışabiliriz.
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk '{print $1 $3}' veri.txt
Ahmet33
hasan19
aylin24
32KARA
nazsabah
Fakat bu şekilde gördüğünüz gibi sütunlar arasında boşluk bulunmuyor. Eğer boşluk olmasını istiyorsak tırnak içinde bunu özellikle belirtebiliriz.
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk '{print $1 " " $3}' veri
Ahmet 33
hasan 19
aylin 24
32 KARA
naz sabah
Eğer spesifik bir satırda işlem yapılmasını istiyorsak bunu “NR”(number record) değişkeni ile özellikle belirtebiliyoruz.
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk 'NR==2 {print $1 " " $3}' veri.txt
hasan 19
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk 'NR==4 {print $1 " " $3}' veri.txt
32 KARA
Ayrıca substr tanımı ardından hangi karakterden sonrasının alınacağını belirtebiliriz.
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk '{print $1 }' veri.txt
Ahmet
hasan
aylin
32
naz
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk '{print substr($1,1) }' veri.txt
Ahmet
hasan
aylin
32
naz
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk '{print substr($1,2) }' veri.txt
hmet
asan
ylin
2
az
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk '{print substr($1,1,3) }' veri.txt
Ahm
has
ayl
32
naz
Ayrıca varsayılan ayırıcı karakteri olan boşluk yerine -F'ayıcı-karakter' tanımlaması sayesinde istediğimiz bir karakteri, ayırıcı olarak belirtebiliyoruz. Örneğin ben denemek için iki nokta üst üste karakterini ayırıcı olarak belirtmek üzere -F':' tanımlamasını kullanabilirim. Denemek için PATH değişkeninde tanımlı olan 1. ve ikinci dizinleri alt alta yazdırmak istiyorum.
┌──(taylan㉿linuxdersleri)-[~]
└─$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/local/games:/usr/games:/home/taylan/Desktop/yeni-dizin
┌──(taylan㉿linuxdersleri)-[~]
└─$ echo $PATH | awk -F':' '{print $1 "\n" $2}'
/usr/local/sbin
/usr/local/bin
awk aracının en temel kullanımı burada ele aldığımız şekilde. Ayrıca daha geniş eşleşmeler için Regex kullanabiliyoruz.
awk üzerinde regex kullanmak için regex tanımlarını slash karakterleri arasında /regex/ şeklinde yazmamız gerek.
Örneğin ben satır sonunda sayı bulunanları filtreleyip, bu son sütunları bastırmak istiyorum.
┌──(taylan㉿linuxdersleri)-[~]
└─$ cat veri.txt
Ahmet Yaz 33
hasan mert 19
aylin uzun 24
32 mehmet KARA
naz 29 sabah
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk '/[0-9]$/{print $NF}' veri.txt
33
19
24
Gördüğünüz gibi [0-9]$ regex tanımı sonunda sayısal veri bulunan satırlar ile eşleşme sağladı, {print $NF} ise bu satırların yalnızca son sütunlarının bastırılmasını sağladı. Benzer şekilde sonunda sayı bulunan satırların hepsini bastırmak için $NF yerine $0 değişkenini kullanabilirdik.
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk '/[0-9]$/{print $0}' veri.txt
Ahmet Yaz 33
hasan mert 19
aylin uzun 24
Eğer regex kalıbının tüm kayıt üzerinde değil de yalnızca belirli alanlar üzerinde aranmasını istersek dolar işareti ile aranmasını istediğimiz bölümü belirtip peşine tilde ~ işareti eklememiz yeterli.
Örneğin ben yalnızca 2. sütununda rakam bulunduran satırların 1. sütunlarını bastırmak istiyorum.
└─$ awk '$2 ~ /[0-9]/{print $1}' veri
naz
Buradaki $2 ~ tanımı [0-9] regex kalıbının yalnızca 2. alanda yani ikinci sütunda eşleşme aramasını sağladı. {print $1} ise sağlanmış olan bu eşleşmelerin 1. sütunlarını konsola bastırmış oldu. Yalnızca ilk sütunu değil de tüm kaydı bastırırsak, zaten bu satırın 2. sütununda rakam geçtiğini kendimiz de görebiliriz.
└─$ awk '$2 ~ /[0-9]/{print $0}' veri
naz 29 sabah
Eğer spesifik olarak dahil edilmesini istemediğimiz alan varsa bunu tilde işaretinden önce ünlem işareti ekleyerek !~ belirtebiliriz. Örneğin ben bir önceki örnekte olan 2. alandakilerin regex dahilinde aranmasını, 2. alandakilerin hariç tutularak aranması olarak değiştirmek istiyorum.
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk '$2 ~ /[0-9]$/{print $0}' veri.txt
naz 29 sabah
┌──(taylan㉿linuxdersleri)-[~]
└─$ awk '$2 !~ /[0-9]$/{print $0}' veri.txt
Ahmet Yaz 33
hasan mert 19
aylin uzun 24
32 mehmet KARA
Gördüğünüz gibi 2. sütununda sayısal veri bulunduran hariç tüm sütunlar regex genişletmesine dahil edilmiş oldu. Yani hariç tutmak istediğimiz alanları tilde işaretinden önce ünlem işareti !~ ile özellikle belirtebiliyoruz.
awk aracı inanılmaz derecede esnek özellikle sahip olan süper yetenekli bir araç. Fakat şahsen ben ihtiyacım olduğu kadarını hatırlayıp, gerektiğinde ek detaylar için interneti kullandığım için burada temel seviye için daha fazla özellikten bahsetmeyi makul bulmuyorum. Daha fazlası için kısa bir araştırma yapmanız yeterli.
Şimdiye kadar nasıl dosya oluşturabileceğimizi, dosyaları nasıl okuyup, içeriklerini istediğimiz gibi filtreleyip değiştirebileceğimizi öğrendik. Şimdi de konsol üzerinden verileri okumak istediğimizde bizlere kolay okuma imkanı sunan araçlardan bahsedelim istiyorum.
Komut satırı üzerinde çalışıyorken, araçların ürettiği çıktıları yine komut satırımız üzerinde yazılı şekilde takip ediyoruz. Fakat sizin de bildiğiniz gibi komut satırının da bir görüntüleme sınırı var. Eğer grafiksel arayüzdeki bir komut satırında çalışıyorsak, zaten terminal aracı çıktıların konsola sığmayan kadarını görebilmemizi sağlayan kaydırma çubuğu gibi özellikler sunuyor.
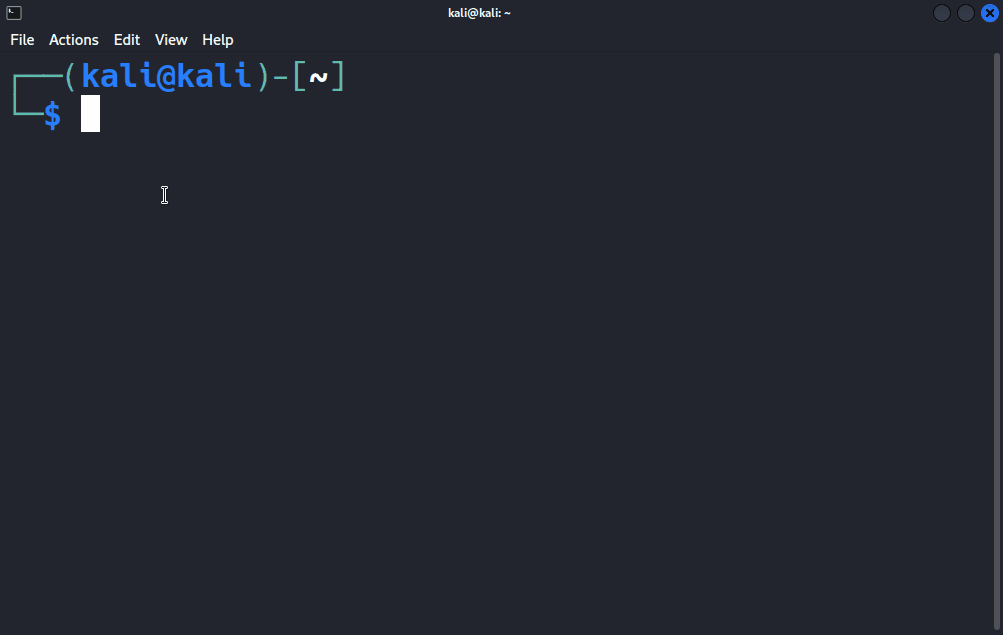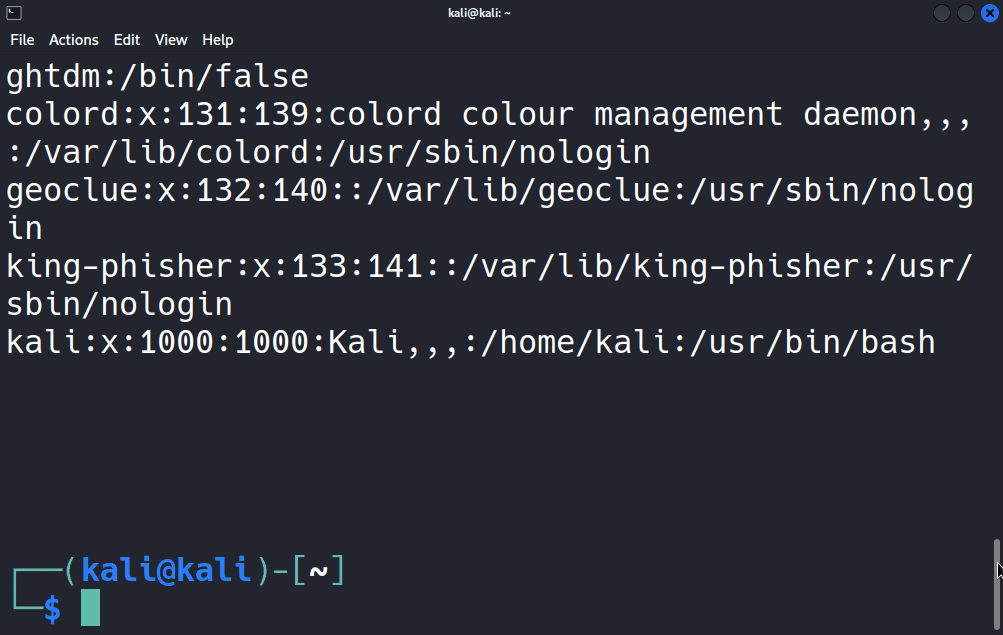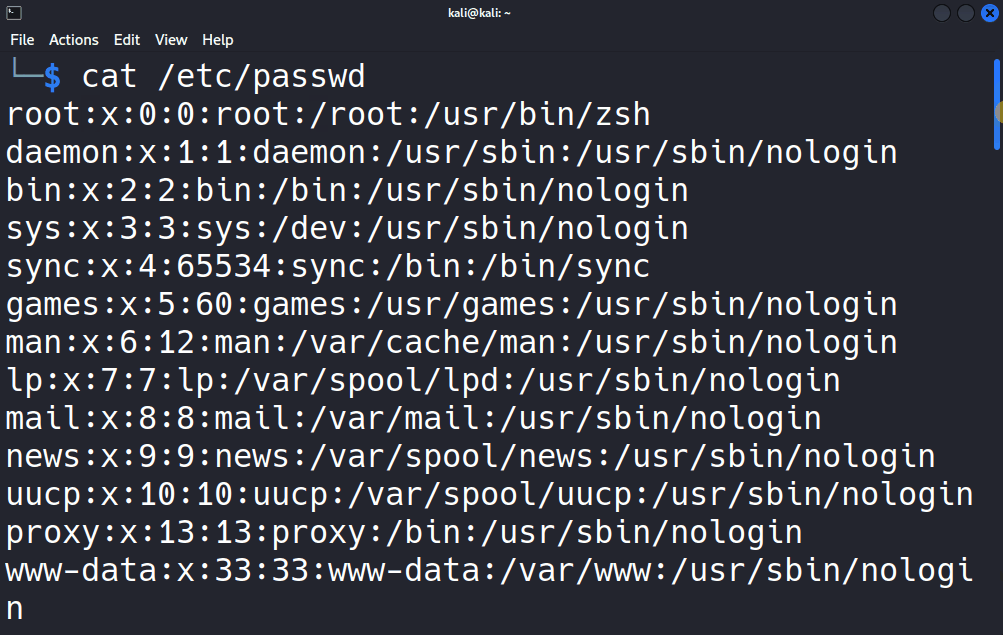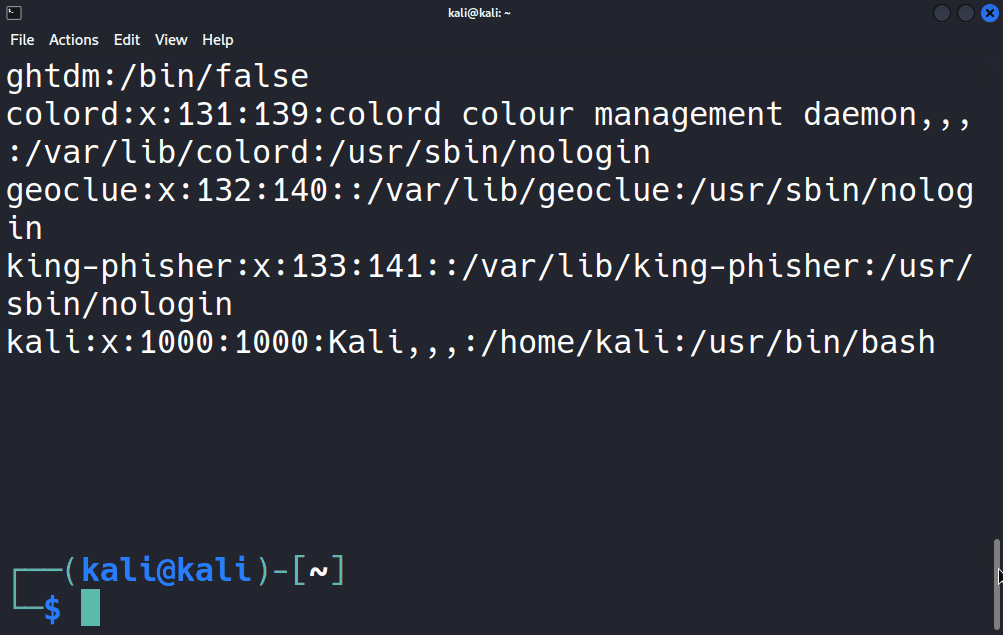
İşte bizzat test ettiğimiz gibi grafiksel arayüzdeki bu konsol aracımız, çıktıların tamamını bu pencere içerisinde tek seferde gösteremiyor olsa da, tamamını görebilmemiz için bize kolaylık sağlıyor. Fakat komut satırı arayüzündeki tty konsollarında çalışırken, önceki çıktılara dönme gibi bir imkanımız olmuyor. Dolayısıyla uzun çıktılar üreten araçların tüm çıktılarını yalnız komut satırı arayüzünün bulunduğu tty konsollarında tam şekilde görüntüleyemiyoruz.
Denemek isterseniz komut satırı arayüzüne geçip uzun bir dosya içeriğini cat komutu ile okuyabilirsiniz. Ben denemek için daha önce oluşturduğum “isimler.txt” dosyamı okumak için cat isimler.txt komutunu giriyorum.
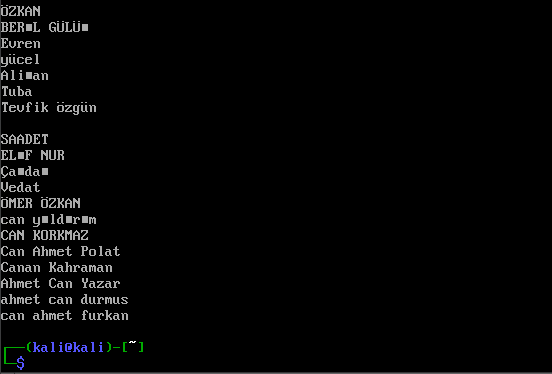
Bakın yalnızca dosyanın sonunu görebiliyoruz. Faremizin scroll tuşu ile daha önceki çıktıları görme imkanımız da yok.
İşte bu duruma çözüm olarak araçların çıktılarını bize parça parça sunabilecek ek araçlara ihtiyacımız var. Ben de anlatımın devamında bize bu imkanı tanıyan more less head ve tail araçlarından bahsedip, komut satırı arayüzündeki hakimiyetimizi arttırmak istiyorum.
more Komutumore aracı, kendisine yönlendirilmiş olan verilerin en başından itibaren ekrana sığan kadarlık kısmını sırasıyla parça parça bize sunuyor. Örneğin bir dosya içeriğinin ilk 10 satırı ekranımıza sığıyorsa, ilk olarak 10 satırı daha sonra bir sonraki 10 satırı ve bir sonraki 10 satırı gösterecek şekilde tüm içerik bitene kadar baştan sonra tüm verileri parça parça bize sunuyor.
Zaten more ismi de “daha” anlamına geliyor. Biz istedikçe verilerin geri kalanını yani daha fazlasını bize parça parça sunduğu için more ismi verilmiş.
Ben örnek olması için /etc dizinin içeriğini listeleyip, tüm listeye parça parça bakmak istiyorum. Örneğin ls -l /etc şeklinde komutumuzu girdiğimizde tek seferde tüm çıktıları göremeyiz.
Bu sorunu çözmek içim bu çıktıları pipe ile more aracına yönlendirip çıktılara parça parça bakabiliriz.
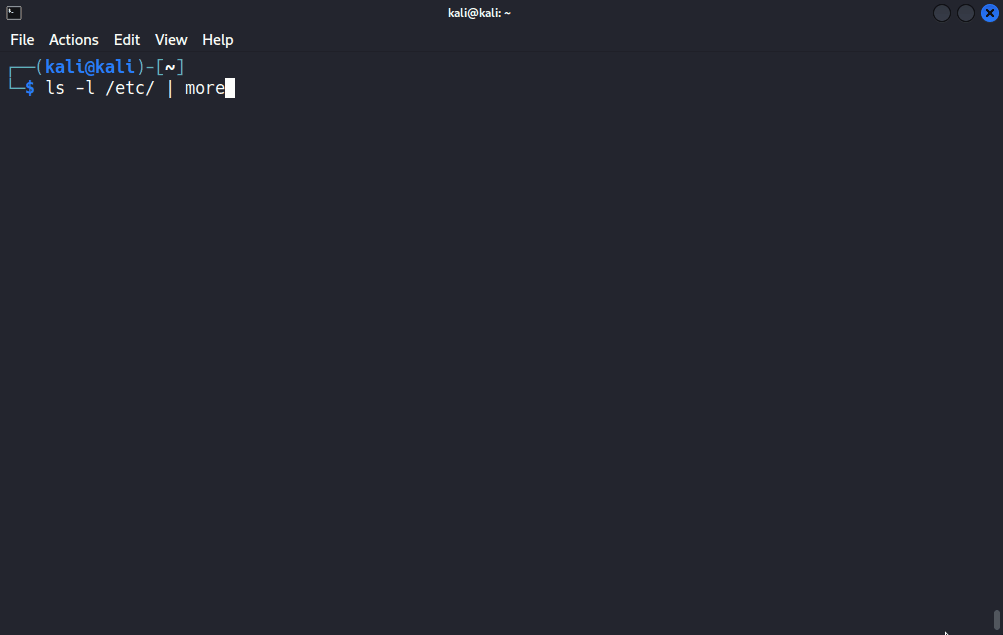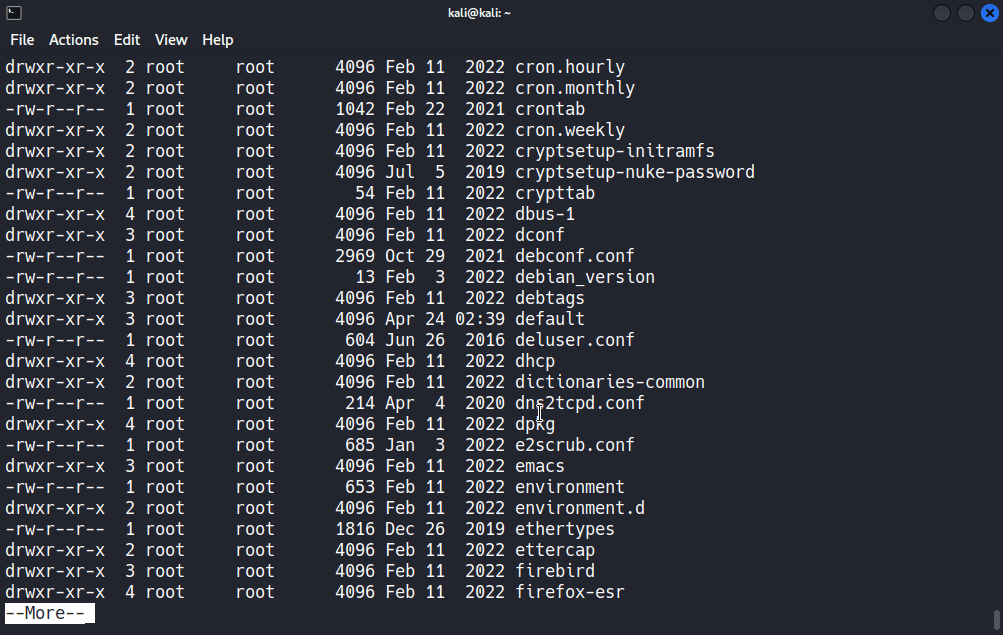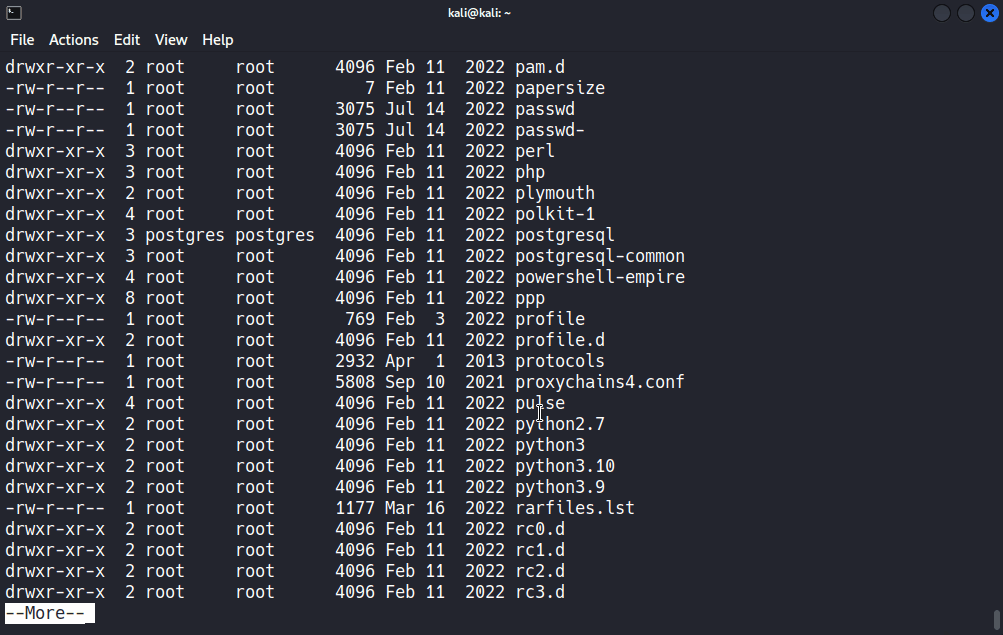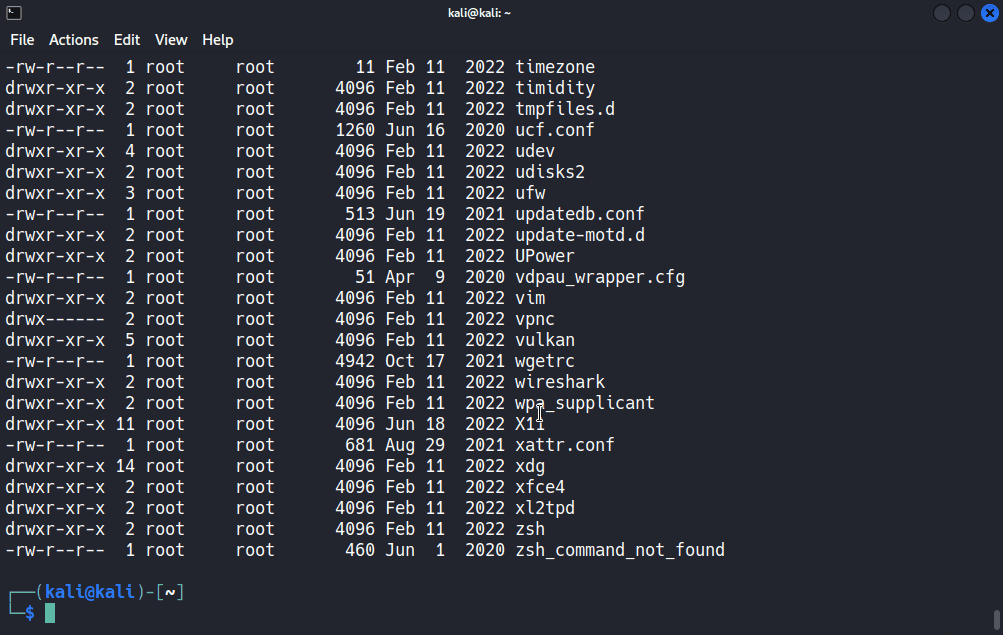
Gördüğünüz gibi bu kez, içerik listesinin en başından itibaren yalnızca ekranıma sığan kadarlık kısmını görüyoruz ve altta “more” ifadesi var. Bu ifade, ileride daha fazla verinin olduğuna işaret ediyor. Eğer bir satır sonrasını görmek istersek enter tuşunu, eğer ekranımıza sığan bir sonraki tüm bölümü görmek istersek de space tuşunu kullanabiliyoruz.
Gördüğünüz gibi tamamı konsol ekranımıza sığmayacak kadar olan tüm verileri, more aracına yönlendirip, bu araç vasıtasıyla ekranımıza sığan kadarlık kısmını parça parça veya satır satır ileriye doğru görüntüleyebiliyoruz. Fark ettiyseniz özellikle “ileriye doğru” dedim çünkü more aracı önceki çıktılara dönmemizi sağlamıyor. Tek yönlü şekilde yani hep daha fazlası için en baştan en sona doğru verileri görüntüleyebiliyoruz. Örneğin space ile geçtiğiniz önceki parçaya dönmek isterseniz bu more aracı ile mümkün değil. Bunun için birazdan bahsedeceğimiz less aracını kullanabiliriz.
Eğer yalnızca ileriye doğru okuma yapacaksanız dosyalar veya pipe üzerinden more aracına okunacak verileri verebilirsiniz. Biz özellikle ele almadık ama elbette more aracı ile doğrudan dosya içeriklerini de okuyabiliyoruz.
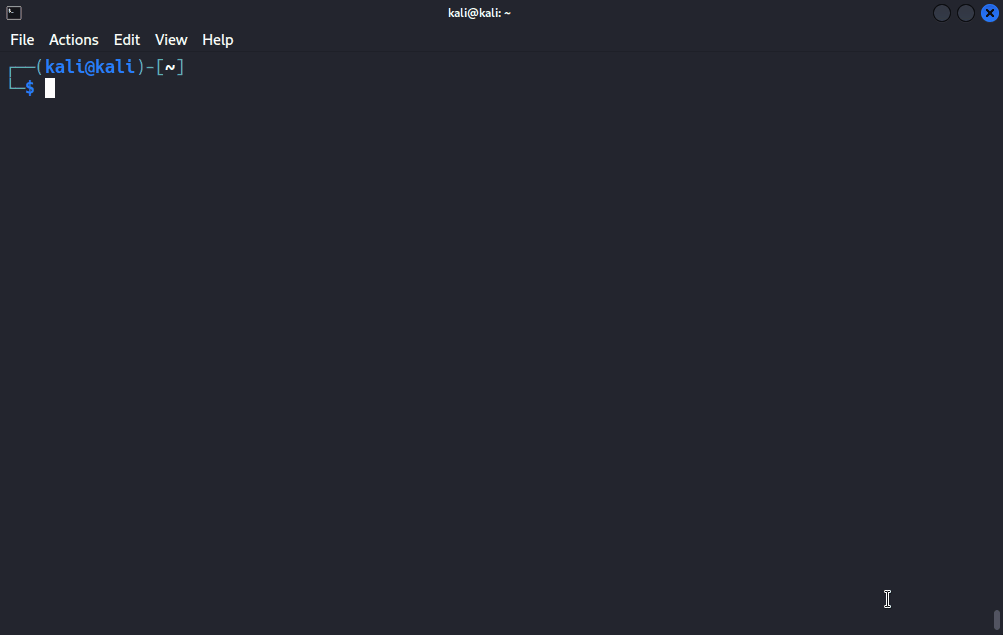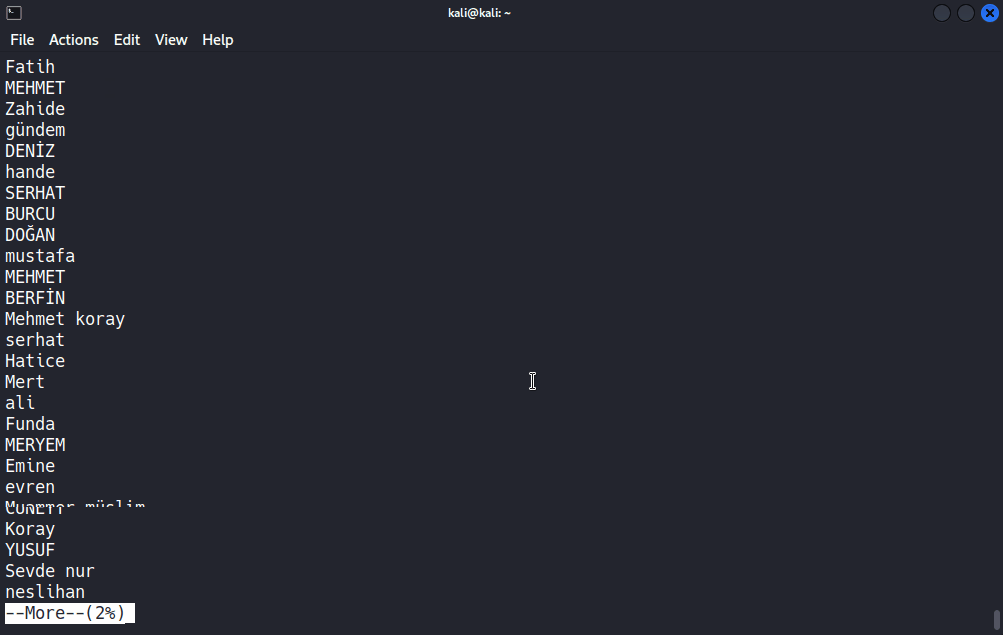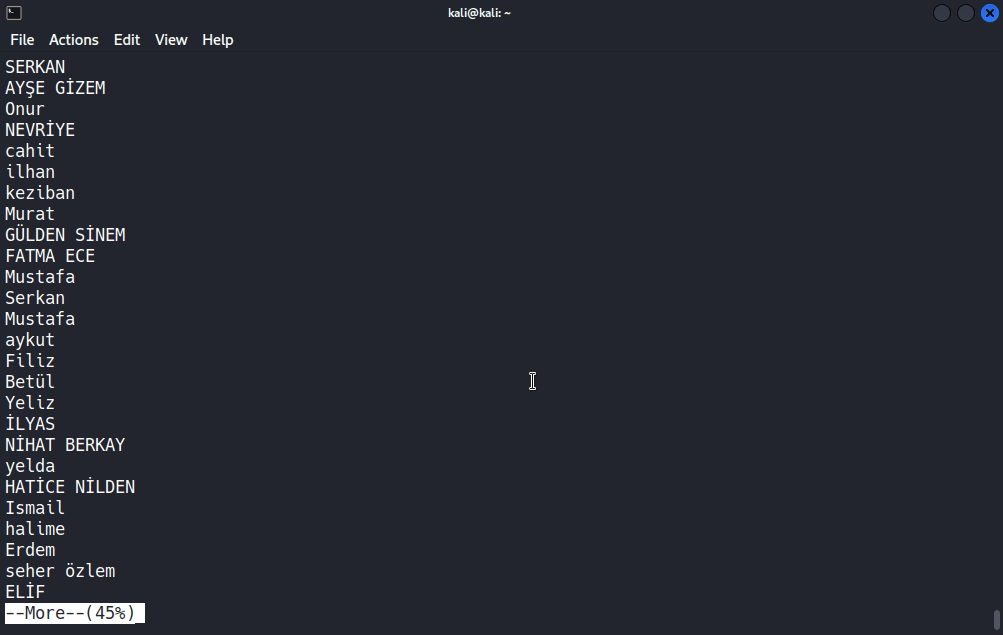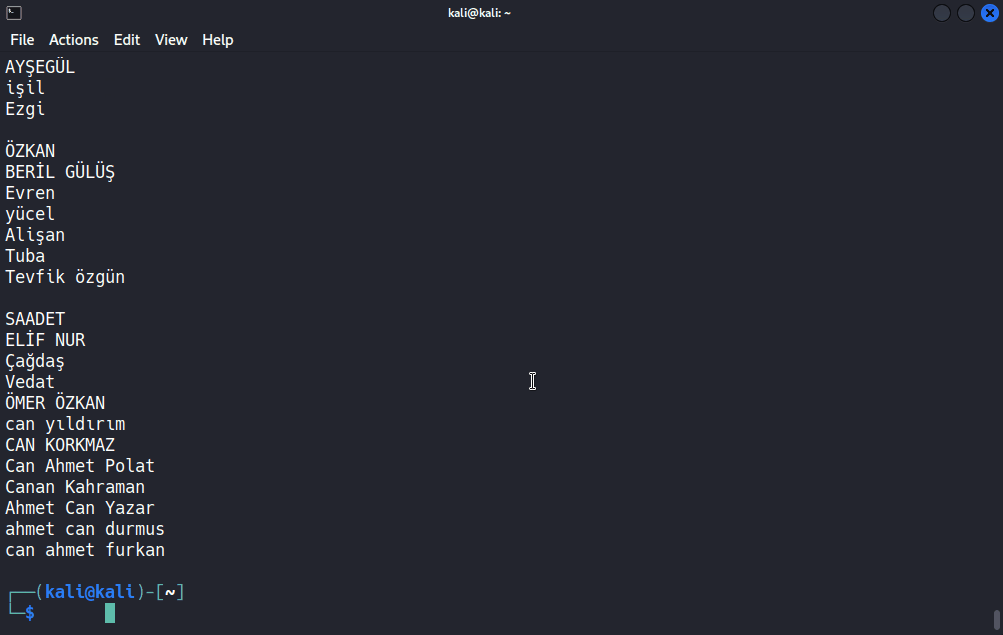
Yani bizzat test ettiğimiz gibi more aracı standart girdiden veri almasına ek olarak, kendisine argüman olarak verilmiş olan dosya içeriğini de parça parça konsol üzerinden görüntüleyebilmemize olanak tanıyor.
Hatta dilerseniz more aracına aynı anda birden fazla dosya ismini verip, birden fazla verinin de sırasıyla more aracı üzerinden okunmasını sağlayabilirsiniz.
Tüm bunlar dışında eğer more aracını kullanırken içeriğin sonuna gelmeyi beklemeden aracı sonlandırmak isterseniz q tuşuna basmanız yeterli. Ben denemek için birden fazla dosyayı more ile açıp, dosyaların sonuna gelmeden q tuşuna basıp more aracını kapatıyorum.
Bakın q tuşuna bastığım anda araç kapatıldı.
less Komutumore aracının çıktılarda geriye doğru kaydırma yapamamasından bıkan başka bir geliştirici “less is more” yani “az çoktan fazladır” cümlesine atıfta bulunarak less aracını geliştirmiştir.
less komutu more komutundan farklı olarak dosya içeriğinde aşağı yukarı, sağa ve sola doğru kaydırma hareketlerine imkan tanıyor.
Test etmek için /etc/passwd dosyasını okumayı deneyebiliriz.
Eğer bir satır aşağı inmek istersem klavyemdeki aşağı yön tuşunu kullanabilirim. Benzer şekilde bir üst satıra çıkmak için de klavyemdeki yukarı yön tuşunu kullanmam yeterli. Ayrıca more komutunda olduğu şekilde enter ile de bir satır aşağı inip, space ile birer sayfa ileriye atlayabiliyoruz. Space tuşu haricinde bir sayfa ileri gitmek için “forward” yani “ileri” ifadesinin kısaltması olan f tuşunu da kullanabiliyoruz. Bir sayfa geri gelmek için de “backward” yani “geriye” ifadesinin kısaltması olan b tuşunu kullanabiliyoruz. Okuma işimiz bittiğinde aracı kapatmak için q tuşuna basmamız yeterli.
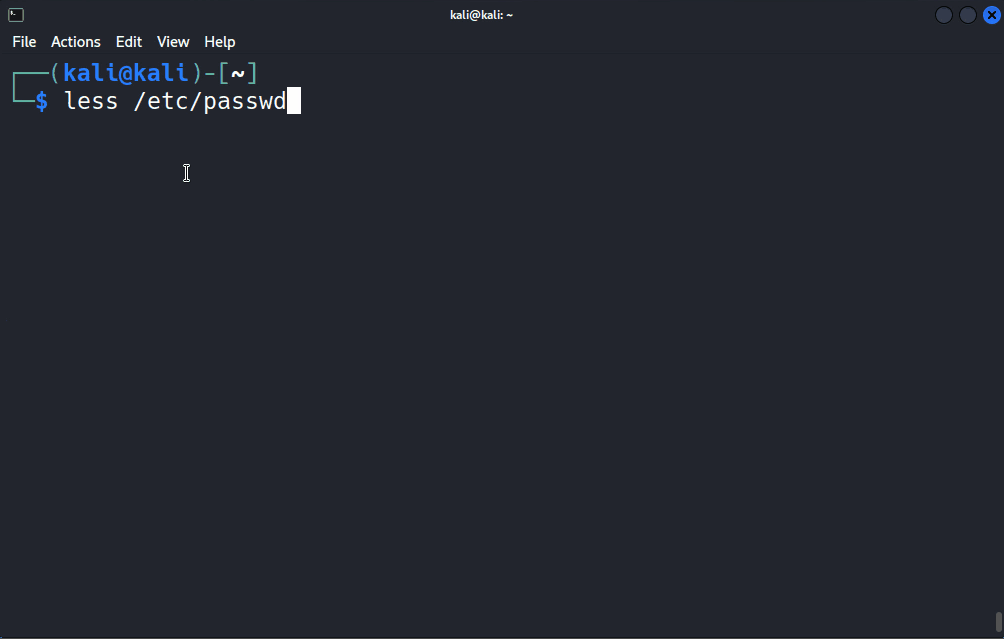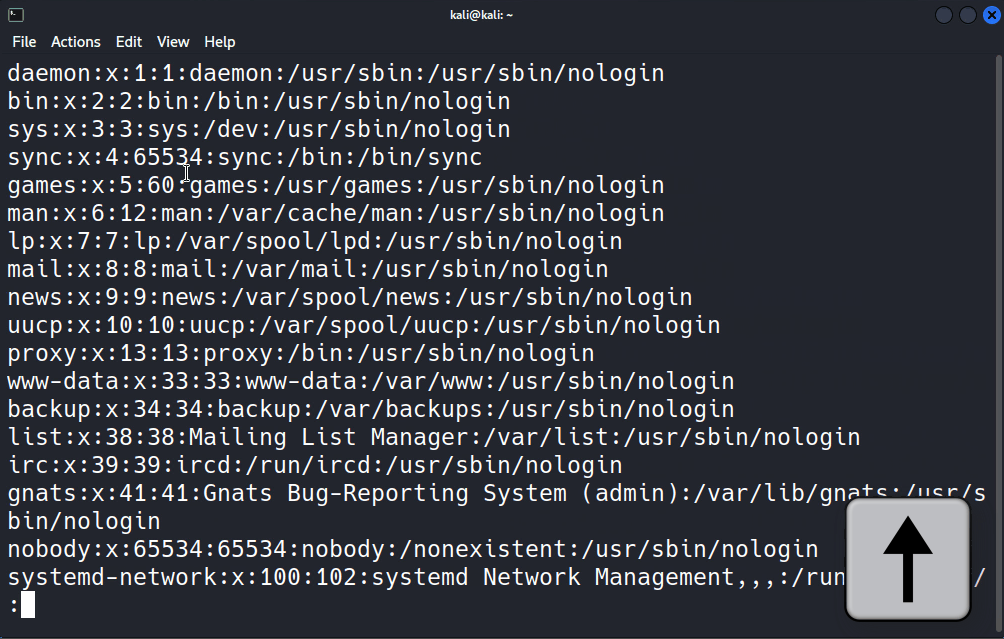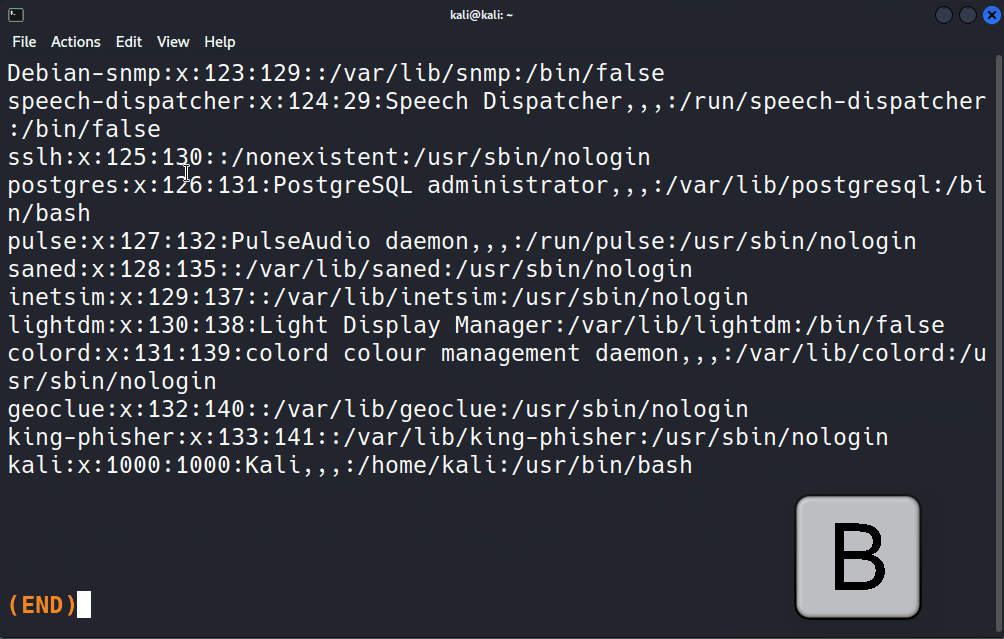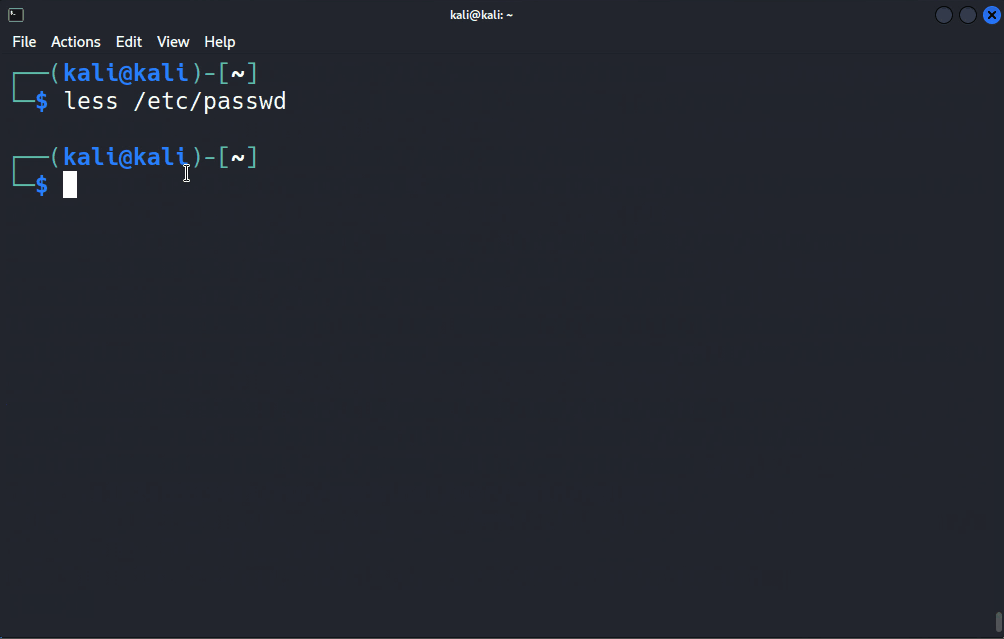
Ben doğrudan dosya ismini argüman olarak verdim ancak dilerseniz tabii ki standart girdiden de istediğiniz veriyi yönlendirebilirsiniz. Örneğim ls -l /etc | less komutu ile /etc dizininin ayrıntılı çıktılarını parça parça inceleyebilirsiniz.
Bence less aracı hakkında bu kadarlık bilgi yeterli. Daha fazlasını öğrenmek veya unuttuğunuzda hatırlamak için less —help komutunu kullanıp less aracının yardım sayfasından faydalanabilirsiniz.
head Komutuİsminin de çağrışım yaptığı gibi head komutu kendisine yönlendirilen içeriğin başından itibaren okunabilmesini sağlıyor. Herhangi bir seçenek belirtmediğimizde head aracı ilk 10 satırı konsola bastırıyor. Ben denemek için head /etc/passwd komutu ile dosyamı okumak istiyorum.
└─$ head /etc/passwd
root:x:0:0:root:/root:/usr/bin/zsh
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
Dosya içeriğinin yalnızca ilk 10 satırı bastırılmış oldu.
Birden fazla dosya okunmasını da sağlayabiliriz. Eğer aynı anda birden fazla dosya okunuyorsa her bir dosyanın ilk 10 satırını bastırıyor. Hemen deneyelim.
└─$ head /etc/passwd /etc/group
==> /etc/passwd <==
root:x:0:0:root:/root:/usr/bin/zsh
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
==> /etc/group <==
root:x:0:
daemon:x:1:
bin:x:2:
sys:x:3:
adm:x:4:taylan,root
tty:x:5:
disk:x:6:
lp:x:7:
mail:x:8:
news:x:9:
Bakın en başta hangi dosya olduğunu da açıkça belirtilerek her iki dosyanın da ilk 10’ar satırı bastırılmış.
Bu temel kullanım dışında eğer kaç satır bastırılmasını gerektiğini belirtmek istiyorsak, -n seçeneğinin ardından kaç satır basılacağını da yazabiliyor. Ben denemek için dosyanın ilk 5 satırını bastırmak üzere head -n 5 dosya_adı şeklinde komutumu giriyorum.
└─$ head -n 5 /etc/passwd /etc/group
==> /etc/passwd <==
root:x:0:0:root:/root:/usr/bin/zsh
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
==> /etc/group <==
root:x:0:
daemon:x:1:
bin:x:2:
sys:x:3:
adm:x:4:taylan,root
┌──(taylan@linuxdersleri)-[~]
└─$ head -n 5 /etc/passwd
root:x:0:0:root:/root:/usr/bin/zsh
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
Bakın dosyaların yalnızca ilk 5 satırı bastırıldı. Ayrıca bu kullanım dışında doğrudan head -5 dosya_adı komutu ile de aynı şekilde ilk 5 satırın bastırılmasını sağlayabiliriz.
└─$ head -5 /etc/passwd /etc/group
==> /etc/passwd <==
root:x:0:0:root:/root:/usr/bin/zsh
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
==> /etc/group <==
root:x:0:
daemon:x:1:
bin:x:2:
sys:x:3:
adm:x:4:taylan,root
Yani bakın, n seçeneği olmadan doğrudan tire işaretinden sonra kaç satır bastırılmasını gerektiğini de bu şekilde belirtebiliyoruz. Aynı çıktıyı aldık.
Tahmin ettiğiniz gibi tabii ki yalnızca dosyalar üzerinde çalışmak zorunda da değiliz. Örneğin ls -l /etc komutunu çıktılarını pipe ile head aracına yönlendirip ilk 10 satırın bastırılmasını sağlayabiliriz.
└─$ ls -l /etc/ | head
total 1320
-rw-r--r-- 1 root root 2981 Feb 11 2022 adduser.conf
-rw-r--r-- 1 root root 44 Feb 11 2022 adjtime
drwxr-xr-x 3 root root 4096 Feb 11 2022 alsa
drwxr-xr-x 2 root root 20480 Jun 28 2022 alternatives
drwxr-xr-x 8 root root 4096 Feb 11 2022 apache2
drwxr-xr-x 2 root root 4096 Feb 11 2022 apparmor
drwxr-xr-x 9 root root 4096 Feb 11 2022 apparmor.d
drwxr-xr-x 7 root root 4096 Jun 14 11:40 apt
drwxr-xr-x 3 root root 4096 Feb 11 2022 avahi
Bakın yalnızca 10 satırı bastırıldı. Mesela bastırılan satır sayısını teyit etmek için pipe ile nl aracını da kullanabiliriz.
└─$ ls -l /etc/ | head | nl
1 total 1320
2 -rw-r--r-- 1 root root 2981 Feb 11 2022 adduser.conf
3 -rw-r--r-- 1 root root 44 Feb 11 2022 adjtime
4 drwxr-xr-x 3 root root 4096 Feb 11 2022 alsa
5 drwxr-xr-x 2 root root 20480 Jun 28 2022 alternatives
6 drwxr-xr-x 8 root root 4096 Feb 11 2022 apache2
7 drwxr-xr-x 2 root root 4096 Feb 11 2022 apparmor
8 drwxr-xr-x 9 root root 4096 Feb 11 2022 apparmor.d
9 drwxr-xr-x 7 root root 4096 Jun 14 11:40 apt
10 drwxr-xr-x 3 root root 4096 Feb 11 2022 avahi
Bakın ls komutunun çıktıları head aracına iletildi ve 10 satırla sınırlandıktan sonra bu çıktılar nl aracı sayesine numaralandırılmış oldu.
Ayrıca head aracının başka seçenekleri de var fakat diğer seçeneklerine neredeyse hiç ihtiyaç duymayacağınızı düşündüğüm için bahsetmiyorum. Merak ediyorsanız, head —help komutunu kullanabilirsiniz.
tail Komututail ifadesi Türkçe “kuyruk” anlamına geliyor. İsminden de kolayca anlaşılabileceği gibi tail komutu dosyaların sondaki satırlarının bastırılmasını sağlıyor. Yani tail aracını head aracının tersten çalışan versiyonu olarak düşünebilirsiniz. tail, ekstra bir seçenek kullanılmadığında varsayılan olarak ilgili dosyanın sondan 10 satırını bastırıyor. Hemen denemek için /etc/passwd dosyasını okumayı deneyelim.
└─$ tail /etc/passwd
sslh:x:125:130::/nonexistent:/usr/sbin/nologin
postgres:x:126:131:PostgreSQL administrator,,,:/var/lib/postgresql:/bin/bash
pulse:x:127:132:PulseAudio daemon,,,:/run/pulse:/usr/sbin/nologin
saned:x:128:135::/var/lib/saned:/usr/sbin/nologin
inetsim:x:129:137::/var/lib/inetsim:/usr/sbin/nologin
lightdm:x:130:138:Light Display Manager:/var/lib/lightdm:/bin/false
colord:x:131:139:colord colour management daemon,,,:/var/lib/colord:/usr/sbin/nologin
geoclue:x:132:140::/var/lib/geoclue:/usr/sbin/nologin
king-phisher:x:133:141::/var/lib/king-phisher:/usr/sbin/nologin
taylan:x:1000:1000:taylan,,,:/home/taylan:/usr/bin/bash
Bakın dosya içeriğinin sondan 10 satırı bastırıldı. Dilersek kaç satır bastırılacağını -n seçeneğinin ardından belirtmemiz de mümkün. Ben son 6 satırı bastırmak için tail -n 6 /etc/passwd şeklinde komutumu giriyorum.
└─$ tail -n 6 /etc/passwd
inetsim:x:129:137::/var/lib/inetsim:/usr/sbin/nologin
lightdm:x:130:138:Light Display Manager:/var/lib/lightdm:/bin/false
colord:x:131:139:colord colour management daemon,,,:/var/lib/colord:/usr/sbin/nologin
geoclue:x:132:140::/var/lib/geoclue:/usr/sbin/nologin
king-phisher:x:133:141::/var/lib/king-phisher:/usr/sbin/nologin
taylan:x:1000:1000:taylan,,,:/home/taylan:/usr/bin/bash
Bakın yalnızca sondan 6 satır bastırılmış.
Ayrıca tıpkı head komutunda olduğu gibi elbette birden fazla dosyayı da aynı anda açabiliriz. Ben passwd ve group dosyalarının sondan 3 satırını bastırmak için tail -n 3 /etc/passwd /etc/group komutunu giriyorum.
└─$ tail -n3 /etc/passwd /etc/group
==> /etc/passwd <==
geoclue:x:132:140::/var/lib/geoclue:/usr/sbin/nologin
king-phisher:x:133:141::/var/lib/king-phisher:/usr/sbin/nologin
taylan:x:1000:1000:taylan,,,:/home/taylan:/usr/bin/bash
==> /etc/group <==
kaboxer:x:143:taylan,root
yeni-grup:x:1003:
ali:x:1001:
Bakın sırasıyla her iki dosyanın da sondan 3 er satırı bastırıldı.
Dosya içeriklerinin okunması yerine standart girdiden alınan verilerin kullanılması da mümkün. Ben ls /etc/ komutu ile dizin içeriğinin listelenip, pipe ile bu çıktıların tail aracına aktarılmasını istiyorum.
└─$ ls /etc/ | tail
wgetrc
wireshark
wpa_supplicant
X11
xattr.conf
xdg
xfce4
xl2tpd
zsh
zsh_command_not_found
Bakın bu sayede gördüğünüz gibi /etc dizin içeriğinin sondan 10 satırı konsola bastırılmış oldu.
-fBu basit kullanımlar dışında, tail aracının -f seçeneği sayesinde sürekli güncellenen verilerin takip etmemiz de mümkün oluyor. Bu -f seçeneği, özellikle log dosyalarındaki en son değişikliklerin takibi için sıklıkla kullanıyor. Seçeneğin kısaltması da “follow” yani “takip etme” ifadesinin kısaltmasından geldiği için işlevinin hatırlanması son derece kolay.
Ben test etmek için iki konsol üzerinden çalışacağım. İlk konsola cat > yeni.txt komutu ile yeni bir dosya açıp veri girişi yapmak üzere giriş yapıyorum. İkinci konsola da yeni.txt dosyasındaki değişikliklerin anlık olarak takip edilmesi için tail -f yeni.txt komutunu giriyorum. Bu sayede ben yeni.txt dosyasına veri ekledikçe bunları tail -f komutu sayesinde anlık olarak takip edebiliyor olacağız.
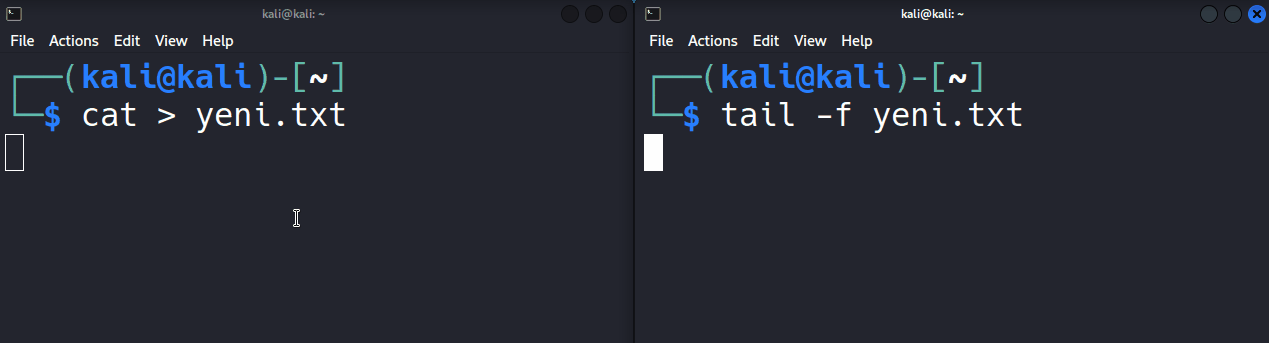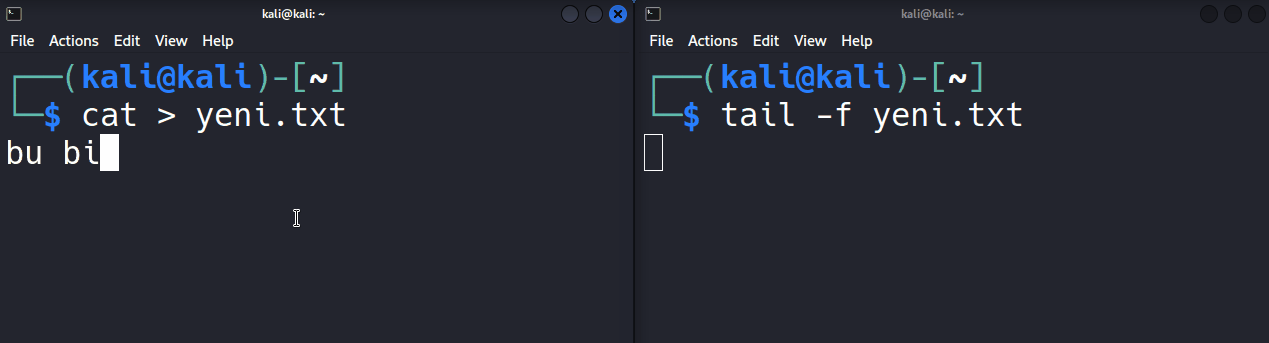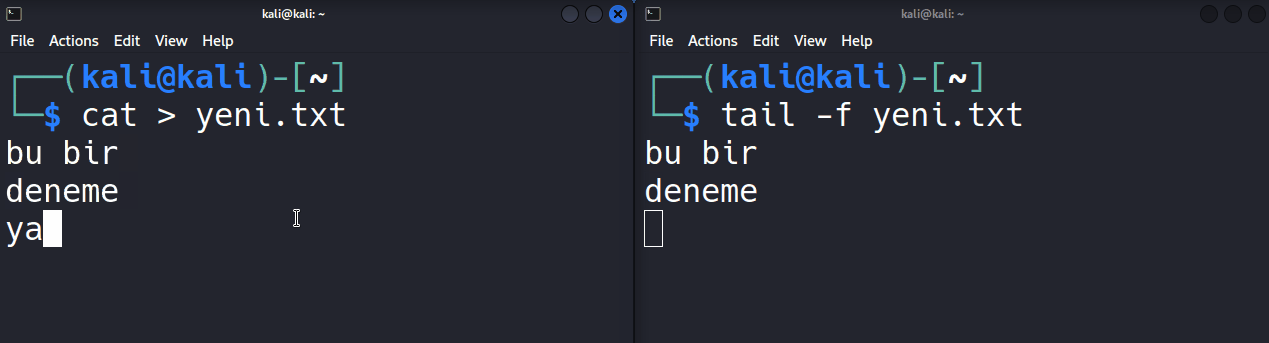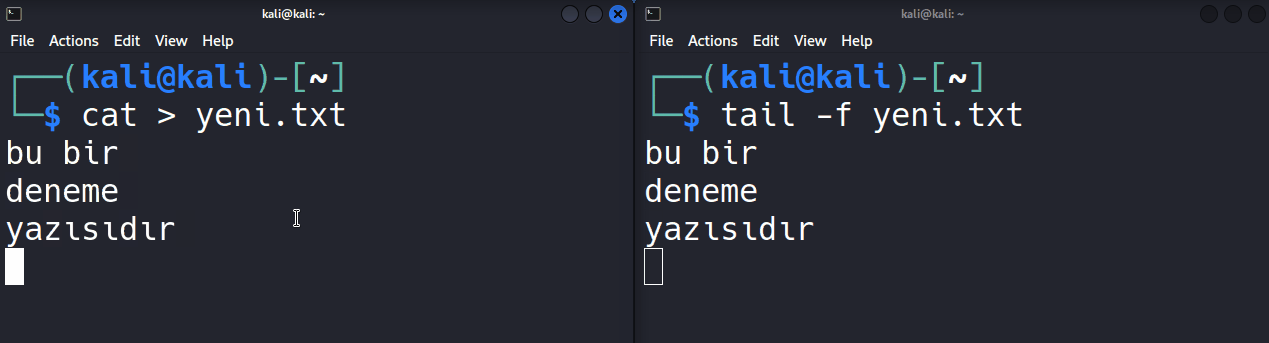
Bakın ne kadar yeni veri girersem, tail -f komutu o kadar veriyi bastırıyor. Bu komut özellikle anlık değişimlerin takibi için log dosyalarını okumak için sıklıkla kullanılıyor.
İleride log kayıtları ile uğraşırken tail -f komutunu sizler de sıklıkla kullanıyor olacaksınız. Eğer bu tail komutunun f seçeneğini kullanmazsak, dosyalardaki en son değişiklikler yerine yalnızca o dosyayı açtığımız andaki verilere ulaşabiliyoruz. tail -f komutu anlık olarak dosya içeriğindeki verileri takip etmemizi sağlıyor. Ayrıca bu şekilde sürekli yeni veri var mı diye beklendiği için aracı kapatmak için ctrl + c ile durdurmamız gerekiyor.
Böylelikle temel olarak tail aracının işlevinden ve kullanımından da haberdar olduk. Tabii diğer seçenekleri için yardım sayfalarına göz atabilirsiniz.
Ayrıca ben özellikle ele almadım ancak pipe mekanizmasının da yardımıyla ihtiyacınıza yönelik olarak bu bölümde öğrenmiş olduğunu uygun yapıdaki tüm araçları birbirine bağlayarak çalıştırabileceğinizi zaten biliyorsunuz. Ben yalnızca araçların temel kullanımlardan bahsettiğim için özellikle birden fazla aracın birlikte kullanıldığı farklı durumlara örnekler verme fırsatım olmadı ama siz kendiniz pratikler yaparak deneyimleyebilirsiniz.

Mevcut bölümü uygulamalı şekilde takip edip bitirdikten sonra buradaki pratik testleri çözmek, öğrenme düzeyinizi ve eksiklerinizi fark etmenizi sağlayabilir. Bu sebeple lütfen bir sonraki bölüme geçmeden önce, buradaki soruları yanıtlayın.
xargs Komututee Komutugrep Komutufind Komutulocate Komutucut Komututr Komutusedawk | gawkİlişkili Video
Mevcut doküman ile ilişkili olan Youtube videosu.

