🎓 Eğitimler 🗃️ Blog 📜 Komut Listesi 🎯 Test 🏷️ Etiketler 💖 Faydalı Kaynaklar 🐧 Hakkında 📮 Geri Bildirim
Mobil Uygulamalar


Linux Dersleri |
GNU/Linux için Türkçe içerik sağlamak üzere kurulmuş bir platformdur.
GNU/Linux için Türkçe içerik sağlamak üzere kurulmuş bir platformdur.
Artık sizin de çok iyi bildiğiniz gibi sistemimizi komut satırı arayüzünden yönetiyorken iletişim dili için yazıyı diğer bir deyişle metinsel verileri kullanıyoruz. Yani komutlarımızı yazılı şekilde girip, sonuçlarını da yine yazılı şekilde takip ediyoruz. Dolayısıyla sistemi etkili şekilde yönetebilmek için metinsel verileri rahatça görüntüleyip gerektiğinde ihtiyaçlarımıza göre düzenleyip kullanabilmemiz şart. Görüntüleme ve düzenleme işlemleri için komut satırı üzerinde kullanabileceğimiz çok çeşitli araçlar mevcut. Bu bölümde temel bazı araçlardan bahsediyor olacağız. Fakat bundan önce genel işleyişten haberdar olmak için bahsetmemiz gereken birkaç temel konu var.
Eğer daha önce az çok Linux ile haşır neşir olduysanız ve biraz da meraklıysanız “Linux üzerinde her şey bir dosyadır” sözünü mutlaka duymuşsunuzdur.
Her şey bir dosyadır tanımı, klavyenizin, dosyaların, dizinlerin, aygıtların ve benzeri tüm yapıların birer dosya olarak tanımlanıp, çekirdekteki sanal dosya sistemi katmanı üzerinde soyutlanmış olan dosya tanımlayıcılar ile temsil edildiğini belirtmek için kullanılıyor. Yani “Her şey bir dosyadır” ifadesi, işletim sisteminin genel mimari yaklaşımını özetliyor. Muhtemelen bu söylediklerim çok açık gelmedi, çünkü henüz bahsetmediğimiz kavramları kullanarak açıklamış oldum. Ancak merak etmeyin anlatımın devamında açıklamalarım sizin için de netleşmiş olacak.
Linux çekirdeğinin yapısı gereği, sistem üzerindeki tüm yapıların dosya gibi ele alındığından bahsettik. Bu yaklaşımın tercih edilme nedeni dosyalar üzerinde işlem yapmanın herkes için çok kolay olması. Siz standart bir kullanıcı olarak yetkiniz olan istediğiniz bir dosyayı okuyabilir veya dosyaya yeni veriler ekleyebilirsiniz. Yani dosya okumak veya dosyaya veri eklemek çok kolay. Tüm yapılar dosya gibi ele alındığında da hepsini dosya yönetir gibi esnek ve kolay şekilde yönetme imkanına sahip oluyoruz. Aslında bu yaklaşım sayesinde tüm sistemdeki yapıları ve araçları yönetebileceğimiz ortak bir iletişim yolu da ortaya çıkmış oluyor.
Yani özünde tüm mesele bayt akışını kontrol etmekten ibaret. Araçların ürettiği çıktıları ve alacakları girdileri ihtiyaçlarımıza göre yönettiğimizde işlerimizi komut satırı üzerinden yerine getirebiliyoruz. Örneğin ben X isimli bir aracın ürettiği çıktıları Y isimli bir araca girdi olarak kolaylıkla bağlayıp birden fazla aracı işimi yerine getirmek için kullanabilirim. Ya da bir aracın talep ettiği girdileri bir dosyadan yönlendirip, aracın bu dosyadaki verileri işlemesini sağlayabilirim. Hatta daha deneyimli bir kullanıcıysam, sistem üzerindeki çeşitli dosyaları inceleyerek sistemin mevcut durumu hakkında bilgi almam da mümkün çünkü sistem üzerinde her şey bir dosya gibi temsil ediliyor. Özetle Linux çekirdeğimiz donanımlar ile gereken alt seviyeli iletişimi kendisi sağlayıp bize sade ve okunaklı şekilde sanal dosyalar sunduğu için pek çok aracı ve yapıyı rahatlıkla denetleyip yönetebiliyoruz.
Söz konusu dosya içeriklerini yönetmek olduğunda da her şey en temelde bayt akışını nasıl kontrol ettiğimize kalıyor. Bir aracın çıktılarını başka bir araca girdi olarak iletebilmek için bu bayt akışını ilgili araca yönlendirebiliyor olmamız gerekiyor.
Linux üzerinde baytları bir kaynaktan diğerine iletmek için yönlendirme mekanizmasından faydalanabiliyoruz.
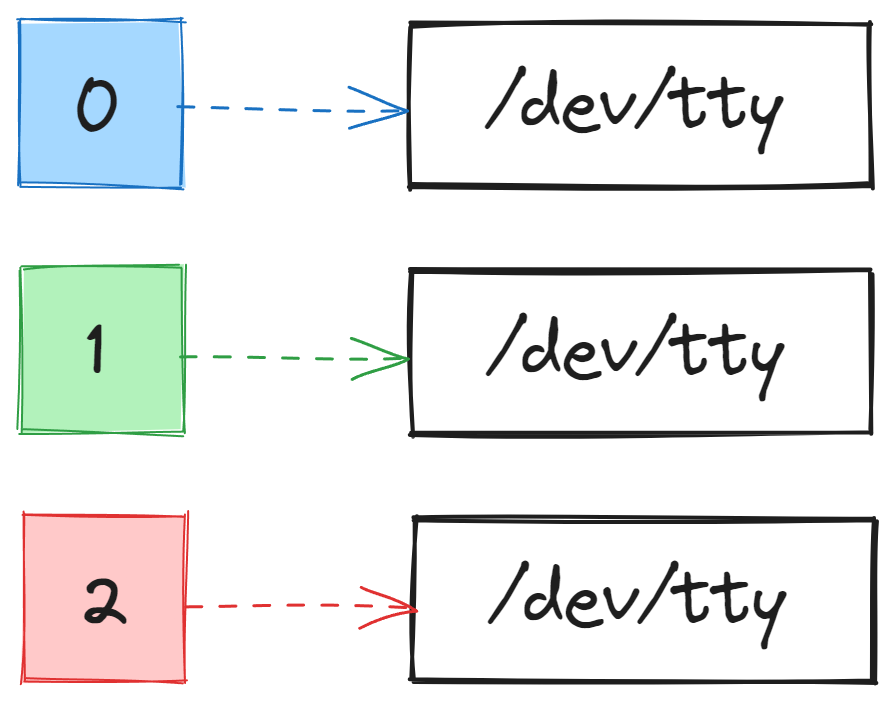
Yönlendirme işlemi için Linux üzerinde standart şekilde her bir dosyanın, girdileri okuduğu ve çıktılarını ilettiği uç noktaları mevcuttur. Bu uç noktalara da “dosya tanımlayıcıları” deniyor. Ve temelde 3 tür dosya tanımlayıcı bulunuyor. Normalde biz aksini belirtmediğimiz sürece bu uçlar konsol aracına bağlı oluyor. Bu sebeple veri girişini konsoldan yapıp, hatalı ve hatasız olan çıktıları yine konsol üzerinde görüyoruz. Söylediklerim hala size anlamlı gelmiyorsa lütfen biraz daha sabırlı olun çünkü aslında son derece basit bir yapı.
Bir dosyaya veri girişi yapmak istiyorsak o dosyanın standart girdisi olarak temsil edilen 0 numaralı dosya tanımlayıcısına verileri yönlendirmemiz gerekiyor.
Eğer bir dosyanın hatasız standart çıktılarını başka bir yere yönlendirmek istiyorsak bu çıktıları 1 numaralı dosya tanımlayıcısı üzerinden okumamız gerekiyor.
Eğer bir dosyanın yani örneğin bir aracın ürettiği hatalı çıktılarını başka bir yere yönlendirmek istiyorsak da bunun için 2 numaralı dosya tanımlayıcısını kullanmamız gerekiyor.
Linux üzerinde her şey dosya gibi ele alındığı için konsol aracı da /dev/tty isimli dosya ile temsil ediliyor. Yani veri girişi yaparken ve hatalı-hatasız çıktıları alırken aşağıdaki gibi işleyiş mevcut.
Hemen somut bir örnek üzerinden görelim. Ben test edebilmek için aynı anda hem hatalı hem de hatasız çıktılar üreten basit bir betik dosyası oluşturmak istiyorum.
Bunun için cat > test.sh komutunu girip, sırasıyla hatasız ve hatalı çıktıları üretecek olan komutları girip Ctrl + d kısayolu ile verilen dosyaya yazılmasını sağlayalım.
┌──(taylan@linuxdersleri)-[~]
└─$ cat > test.sh
echo "Bu hatasız bir çıktı"
asdf
┌──(taylan@linuxdersleri)-[~]
└─$
Şimdi bu dosyanın çalıştırabilmesi için chmod +x test.sh komutu ile yetki verip, hemen ./test.sh komutu ile betik dosyamızı çalıştırıp test edelim.
┌──(taylan@linuxdersleri)-[~]
└─$ chmod +x test.sh
┌──(taylan@linuxdersleri)-[~]
└─$ ./test.sh
Bu hatasız bir çıktı
./test.sh: line 2: asdf: command not found
┌──(taylan@linuxdersleri)-[~]
└─$
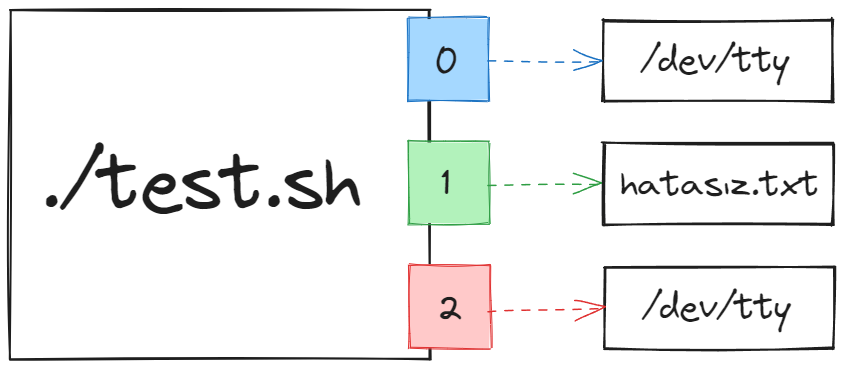
Bakın hem hatasız hem de hatalı çıktılar almış olduk. Betik dosyasındaki echo "Bu hatasız bir çıktı" komutu hatasız çıktı üretirken, asdf isimli bir komut olmadığı için bu komut da hatalı çıktı üretmiş oldu. Biz bu çıktıları özellikle herhangi bir adrese yönlendirmediğimiz için bu çıktılar konsolumuza bastırıldı. Konsola bastırmak yerine istediğimiz isimde bir dosyaya yönlendirebiliriz. Öncelikle hatasız çıktıları yönlendirmeyi deneyelim.
Hatasız çıktılar “standart çıktı” olarak ifade ediliyor ve 1 numaralı dosya tanımlayıcısı ile temsil ediliyor. Ben denemek için ./test.sh 1> hatasız.txt komutu ile hatasız çıktıları “hatasız.txt” dosyasına yönlendiriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ ./test.sh 1> hatasız.txt
./test.sh: line 2: asdf: command not found
┌──(taylan@linuxdersleri)-[~]
└─$
Gördüğünüz gibi konsola yalnızca hatalı olan çıktılar bastırıldı çünkü ben hatasız olan çıktıları bu “hatasız.txt” dosyasına yönlendirdim. Dolayısıyla konsola bastırılacak hatasız bir çıktı kalmadı. Şimdi cat komutu ile hatasız dosyasını okuyup içeriğine bakalım.
┌──(taylan@linuxdersleri)-[~]
└─$ cat hatasız.txt
Bu hatasız bir çıktı
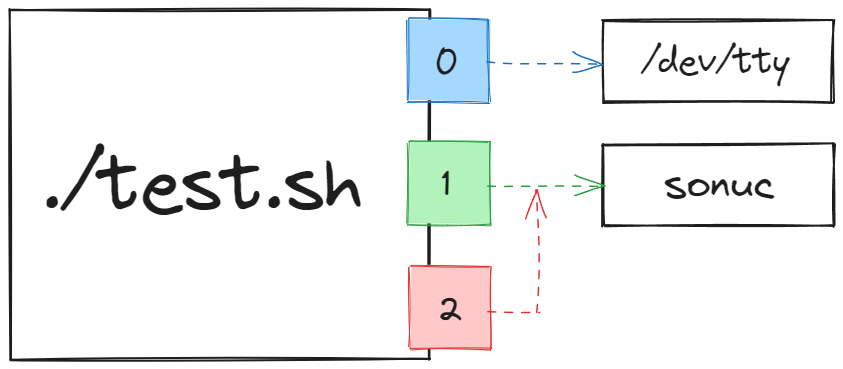
Bakın hatasız çıktı da bu dosyaya kaydolmuş. Şema üzerinden bakacak olursak, girdiğimiz komuttaki yönlendirme aşağıdaki gibi temsil edebilir.
Burada hatasız olan çıktıları yönlendirmek için 1> operatörünü kullandık ama aslında standart çıktılar varsayılan olarak yalnızca tek bir büyüktür > işareti ile de yönlendirilebiliyor. Hemen deneyelim.
┌──(taylan@linuxdersleri)-[~]
└─$ ./test.sh > hatasız2.txt
./test.sh: line 2: asdf: command not found
┌──(taylan@linuxdersleri)-[~]
└─$ cat hatasız2.txt
Bu hatasız bir çıktı
Bakın yine yalnızca hatalı olan çıktılar konsola bastırıldı. Yani standart çıktıları temsil eden 1 numaralı dosya tanımlayıcıyı özellikle belirtmeden yalnızca büyüktür operatörü ile de standart çıktıları istediğimiz yere yönlendirebiliyoruz.
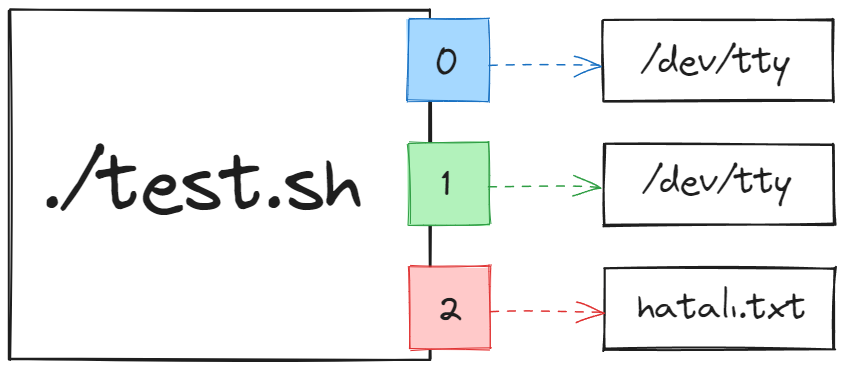
Nasıl ki üretilen “hatasız çıktılar” “standart çıktı” olarak isimlendiriliyorsa, üretilen “hatalı çıktılar” da “standart hata” çıktıları olarak ifade ediliyor ve 2 numaralı dosya tanımlayıcı ile temsil ediliyor.
Yani örneğin ben betik dosyasının ürettiği hatalı çıktıları bir dosyaya yönlendirmek istersem büyüktür yönlendirme operatörü ile 2> şeklinde özellikle belirtmem gerekiyor. Hemen denemek için ./test.sh 2> hatalı.txt şeklinde komutumuzu girelim.
┌──(taylan@linuxdersleri)-[~]
└─$ ./test.sh 2> hatalı.txt
Bu hatasız bir çıktı
┌──(taylan@linuxdersleri)-[~]
└─$ cat hatalı.txt
./test.sh: line 2: asdf: command not found
Bakın hatalı çıktıları bu dosyaya yönlendirdiğimiz için bu kez da konsola yalnızca hatasız olan çıktılar bastırıldı. Yönlendirme yaptığımız dosyanın içeriğini ise yalnızca hatalı çıktı bulunuyor çünkü ben betik dosyasının ürettiği hatalı çıktıları 2 numaralı dosya tanımlayıcı ve buradaki büyüktür yönlendirme operatörü ile bu dosyaya yönlendirdim. Şema üzerinden bakacak olursak, girdiğimiz komuttaki yönlendirme aşağıdaki gibi temsil edebilir.
İşte bu örneklerde ele aldığımız gibi ihtiyacımıza göre hatasız ve hatalı olan çıktıları istediğimiz bir dosyaya yönlendirebiliyoruz.
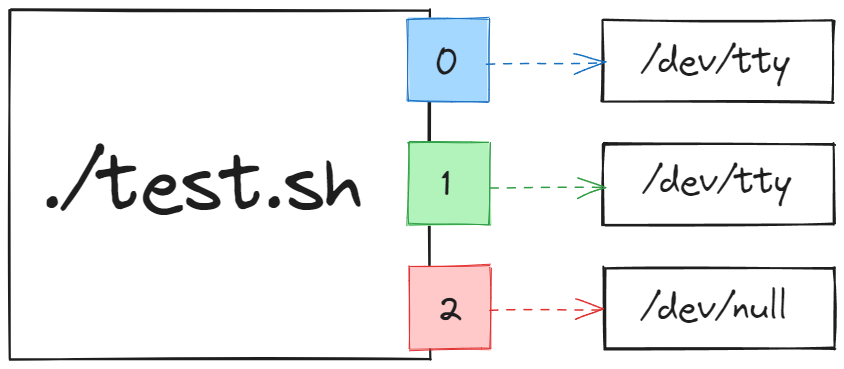
Örneğin bir aracın ürettiği hatalı çıktıları görmek istemezseniz , yalnızca hatalı çıktıları yok etmek için bunları /dev/null dosyasına yönlendirebilirsiniz. /dev/ dizini altındaki null dosyası, kendisine gönderilen tüm verileri yutmak için çekirdek tarafından sağlanan sanal bir dosya. Biz buraya çıktı yönlendirdiğimizde ilgili çıktı hiç bir yere kaydolmuyor, yani aslında çıktıları boşluğa yönlendirmiş oluyoruz. Bu sayede araçların ürettiği hatalı çıktılardan kolayca kurtulmamız da mümkün oluyor.
Denemek için ./test.sh 2> /dev/null şeklinde komutumuzu girebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ ./test.sh 2> /dev/null
Bu hatasız bir çıktı
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın konsola yalnızca hatasız olan çıktı bastırıldı çünkü hatalı olanları /dev/ dizini altındaki null dosyasına yönlendirdik. Şimdi hatalı çıktılara ne olduğunu görmek için çıktıları yönlendirdiğimiz /dev/null dosyasının içeriğini okumayı deneyebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ cat /dev/null
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın herhangi bir çıktı almadık çünkü aslında bu dosya verileri boşluğa göndermek için kullanılan sanal bir dosya. Biz yönlendirsek de içerisinde hiç bir veri tutmuyor çünkü bu dosya bizim bildiğimiz standart dosyalardan değil. Daha önce Linux üzerinde her şeyin bir dosya gibi ele alından bahsetmiştik. İşte bu dosya da bu yaklaşımın bir sonucu. Siz de istemediğiniz tüm verileri /dev/null dosyasına yönlendirip onlardan kurtulabilirsiniz. Üstelik bu dosya disk üzerinde yer alan gerçek bir dosya olmadığı için disk üzerinde okuma yazma yükü oluşturmuyor. Bu ve benzeri dosyalar çekirdek tarafından sanal olarak oluşturulan ve bellek yani geçici hafıza üzerinden çalıştırılan sözde dosyalardır. Bu yaklaşım sayesinde disk üzerinde yük oluşturma durumundan da endişe etmemize gerek kalmıyor.
Şema üzerinden bakacak olursak, girdiğimiz komuttaki yönlendirme aşağıdaki gibi temsil edebilir.
Tekrar asıl konumuza dönecek olursak, hatalı ve hatasız çıktıları ayrı ayrı nasıl yönlendirebileceğimizden açıkça bahsettim. Fakat kimi zaman ayrı ayrı yönlendirmek yerine tüm çıktıları tek bir adrese yönlendirmek de isteyebiliriz. Bu işlem için yönlendirme operatöründen önce “ve” “&” işaretini yani “ampersant” işaretini ekleyip &> operatörünü kullanabiliyoruz. Buradaki ampersant olarak da bilinen “&” işaretini hem hatalı ve hem de hatasız çıktıları temsil ediyor gibi düşünebilirsiniz. Denemek için ./test.sh &> sonuc şeklinde komutumuzu girelim.
┌──(taylan@linuxdersleri)-[~]
└─$ ./test.sh &> sonuc
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın konsolumuza herhangi bir çıktı bastırılmadı çünkü tüm çıktılar bu dosyaya yönlendirildi. Görmek için cat komutu ile okuyalım.
┌──(taylan@linuxdersleri)-[~]
└─$ cat sonuc
Bu hatasız bir çıktı
./test.sh: line 2: asdf: command not found
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın tüm çıktılar bu “sonuc” dosyasına eklenmiş. Yani hatalı ve hatasız çıktıların &> operatörü sayesinde tek bir adrese yönlendirilebildiğini bizzat teyit etmiş olduk.
Şema üzerinden bakacak olursak, girdiğimiz komuttaki yönlendirme aşağıdaki gibi temsil edebilir.
Esasen söz konusu yönlendirmeler olduğunda çok daha fazla detay ve alternatif yaklaşım söz konusu. Örneğin yukarıdaki şemaya bakacak olursanız aslında bu yönlendirmede, hatalı çıktıları hatasız olanlara yönlendirip, hatasız olanlara birlikte bunları ilgili dosyaya yönlendirmeyi sağlamış oluyoruz. Fakat temel düzey için hatalı ve hatasız çıktıları yönlendirmek için &> operatörünü kullanabileceğinizi bilmeniz yeterli. Zira bu eğitimde bu konunun detaylarına girmemiz kafa karıştırıcı olabilir. Ben yalnızca basit düzeyde temel yaklaşımları ele aldım. Daha fazlası için kısa bir araştırma yapmanız yeterli.
En nihayetinde hem ayrı ayrı hem de birleşik şekilde hatalı ve hatasız çıktıları nasıl yönlendirebileceğimizi örnekler üzerinden ele aldık. Anlatımın devamında girdileri nasıl yönlendirebileceğimizden de kısaca bahsedeceğim ama öncelikle çıktıların yönlendirilmesiyle ilgili konuşmak istediğim birkaç detay daha var.
>Biz örneklerimiz sırasında hep tek büyüktür “>” karakterini kullanarak yeni bir dosya oluşturulmasını ve içerisine ilgili verinin yönlendirilmesini sağladık. Yönlendirme yapmak için tek büyüktür işareti kullandığımızda aslında kabuğumuza, “eğer bu yönlendirme işaretinden sonra gelen bu dosya ile aynı isimde bir dosya yoksa yeni dosya oluştur, eğer bu isimde bir dosya varsa da yönlendirilen verileri bu dosyanın üzerine yaz” demiş oluyoruz. Yani biz tek büyüktür operatörünü kullandığımızda aynı isimli bir dosya varsa o dosyanın içeriği silinip en son yönlendirilen veriler kaydediliyor. Dolayısıyla eski dosyanın tüm içeriği yok edilmiş oluyor.
Denemek için içerisinde hatalı ve hatasız çıktılar olan sonuc isimli dosyamıza tekrar yalnızca hatasız çıktımızı yönlendirmek üzere ./test.sh > sonuc şeklinde komutumuzu girebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ ./test.sh > sonuc
./test.sh: line 2: asdf: command not found
┌──(taylan@linuxdersleri)-[~]
└─$ cat sonuc
Bu hatasız bir çıktı
Bakın önceki hatalı ve hatasız çıktılar silinmiş, bunlar yerine en son yönlendirmiş olduğum hatasız çıktılar eklenmiş. İşte tıpkı bu örnekte olduğu gibi biz tek büyüktür işaretini kullandığımızda hedefte aynı isimli bir dosya varsa bu dosya içeriğinin üzerine yönlendirilmiş olan veriler yazılıyor. Eğer amacınız tam olarak bu değilse, tek büyüktür yönlendirme operatörünü kullanarak önemli dosyaların içeriklerinin yok olmasına sebep olabilirsiniz.
>>Yönlendirilecek olan verileri, mevcut verilerin sonuna eklemek istediğimizi belirtmek için de çift büyüktür >> işaretini kullanabiliyoruz. Ben bir önceki komutumu çağırıp, bu kez çift büyüktür ile yine hatasız çıktıların bu dosyanın sonuna eklenmesini istiyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ ./test.sh >> sonuc
./test.sh: line 2: asdf: command not found
┌──(taylan@linuxdersleri)-[~]
└─$ cat sonuc
Bu hatasız bir çıktı
Bu hatasız bir çıktı
Bakın dosyanın sonuna yani aynı hatasız çıktıların eklendiğini görebiliyoruz çünkü çift büyüktür işareti sayesinde ekleme yapılması gerektiğini belirtmiş olduk. Testi devam ettirmek içinin ben ./test.sh 2>> sonuc komutu ile yalnızca hatalı olan çıktıların da dosyanın sonuna eklenmesini istiyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ ./test.sh 2>> sonuc
Bu hatasız bir çıktı
┌──(taylan@linuxdersleri)-[~]
└─$ cat sonuc
Bu hatasız bir çıktı
Bu hatasız bir çıktı
./test.sh: line 2: asdf: command not found
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın hatalı çıktılar da dosyanın sonuna eklendi. Son olarak tek seferde hem hatalı hem de hatasız çıktıları dosyanın sonuna eklemek istersek ./test.sh &>> sonuc şeklinde komut girmeyi deneyebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ ./test.sh &>> sonuc
┌──(taylan@linuxdersleri)-[~]
└─$ cat sonuc
Bu hatasız bir çıktı
Bu hatasız bir çıktı
./test.sh: line 2: asdf: command not found
Bu hatasız bir çıktı
./test.sh: line 2: asdf: command not found
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın bu çıktılar da dosyanın sonuna eklenmiş durumda.
Yani örneklerimizle birlikte tek büyüktür işaretinin verilerin üzerine yazdığını ve çift büyüktür işaretinin de var olanlara ekleme yaptığını bizzat teyit etmiş olduk.
Özelikle belirtmedim ancak istersek daha önce var olmayan bir dosyayı oluşturmak için de çift büyüktür işaretini kullanabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ ./test.sh &>> yepyenidosya
┌──(taylan@linuxdersleri)-[~]
└─$ cat yepyenidosya
Bu hatasız bir çıktı
./test.sh: line 2: asdf: command not found
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın çift büyüktür işareti sayesinde belirttiğimiz isimde dosya oluşturuldu ve bu çıktılar da bu dosyaya yönlendirildi. Tamamdır bence çıktıları yönlendirmeyle ilgili temelde bilmemiz gerekenlerden bahsettik.
Şimdi bir de girdileri yönlendirmek için kısaca standart girdiden bahsedelim.
Standart girdiden veri kabul eden tüm araçlara “küçüktür” < yönlendirme operatörü ile doğrudan veri girişinde bulunabiliyoruz. Örneğin ben “sonuc” isimli dosyayı okumak için cat < sonuc şeklinde komutumu girebilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ cat < sonuc
Bu hatasız bir çıktı
Bu hatasız bir çıktı
./test.sh: line 2: asdf: command not found
Bu hatasız bir çıktı
./test.sh: line 2: asdf: command not found
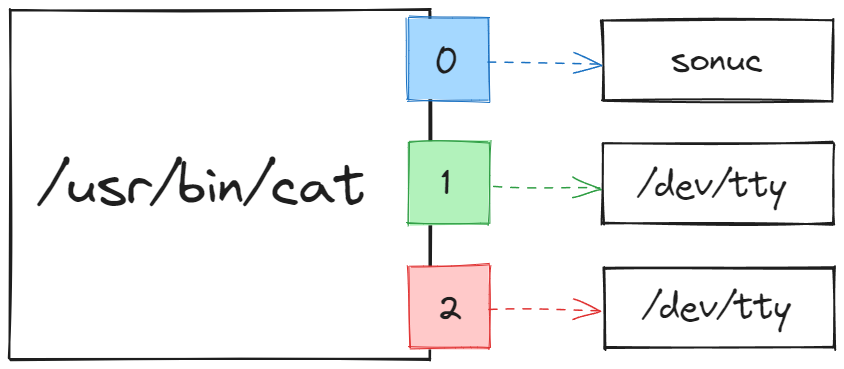
Buradaki “küçüktür” < yönlendirme operatörü cat aracına bu dosyanın içeriğini yönlendirip bunun konsola bastırılmasını sağlıyor. İşleyişe şema üzerinden bakacak olursak aşağıdaki gibi temsil edebilir.
ℹ️ Not: cat aracı sistem üzerinde /usr/bin/cat konumunda bulunduğu için temsil edilirken bu dosya ismini kullandım.
Normalde doğrudan cat sonuc komutu ile de okuyabileceğimiz için belki bu örneğimiz size çok mantıklı gelmemiş olabilir ancak merak etmeyin ileride farklı araçlar üzerinde kullanırken daha anlamlı hale gelecek. Fakat biraz önce de belirttiğim gibi bir araca bu şekilde yönlendirme operatörü ile veri iletmek için o aracın standart girdiden veri kabul ediyor olması gerekiyor. Eğer o araç standart girdiye bakmıyorsa yani buradan veri kabul etmiyorsa yönlendirmiş olduğunuz hiç bir veri bu araç tarafından işlenmez.
Bu duruma örnek olarak echo aracını ele alabiliriz mesela. echo aracının tek görevi kendisinde sonra yazılmış olan argümanları bastırmaktır. Yani echo aracı standart girdiden veri kabul etmiyor, yalnızca kendisinden sonra yazılmış olan argümanları alıp konsola bastırıyor. Dolayısıyla eğer biz echo aracının standart girdisine veri gönderirsek echo aracı hiç bir tepki vermeyecek. Bizzat denemek için “sonuc” isimli dosyanın içeriğini echo aracına yönlendirmek üzere komutumuzu echo < sonuc şeklinde girebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ echo < sonuc
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın herhangi bir çıktı almadık çünkü echo aracı standart girdiden veri okumuyor. Dolayısıyla bizim veri yönlendirmiş olmamız echo için hiç bir anlam ifade etmiyor. Yani aşağıdakine benzer bir işleyiş söz konusu.
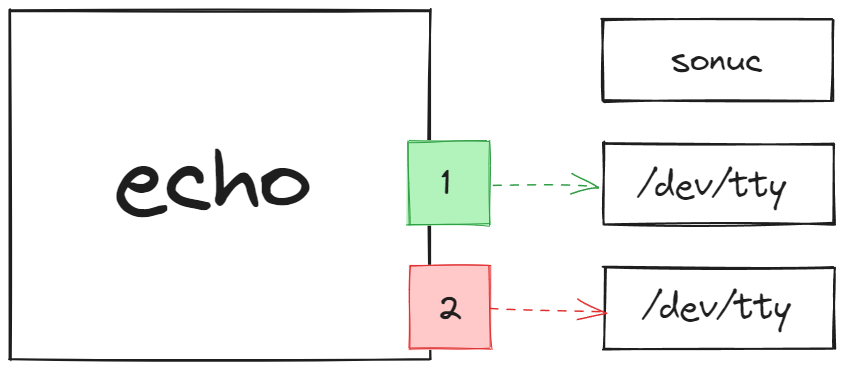
Ek bir örnek daha vermemiz gerekirse örneğin tıpkı echo aracı gibi, klasör oluşturmamızı sağlayan mkdir aracı da standart girdiden veri okuması yapmıyor. Bu sebeple eğer biz klasör oluşturmak istiyorsak, klasör ismini mkdir aracına argüman olarak vermemiz gerekiyor. Ben denemek için mkdir aracına mkdir < sonuc komutu ile yine “sonuc” dosyasının içeriğini girdi olarak yönlendirmeyi deniyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ mkdir < sonuc
mkdir: missing operand
Try 'mkdir --help' for more information.
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın komutumuz hata verdi çünkü mkdir aracı standart girdiye bakmıyor. Yani ben mkdir < sonuc şeklinde yazdım ama mkdir aracına oluşturması gereken klasör için hiç bir argüman iletilmedi.
İşte bizzat örnekler üzerinden de teyit ettiğimiz gibi standart girdiden veri okumayan araçların standart girdilerine veri yönlendirmesi yapmamız anlamsız çünkü standart girdilerini okumuyorlar. Örnekler sırasında ele aldığımız araçlar gibi yalnızca argümanlarla çalışabilen araçlara dosyalardan veri yönlendirmesi yapmak için alternatif çözüm var fakat bu çözümden daha sonra ayrıca bahsediyor olacağız.
Şimdi burada odaklanmanız gereken tek detay standart girdi yönlendirmesinin yalnızca standart girdiden veri kabul eden araçlar üzerinde etkili olduğu. Peki hangi aracın standart girdiden veri alıp hangisinin argümanlar üzerinden çalıştığını nerden bileceğiz diye soracak olursanız.
Hangi araçların standart girdiden veri kabul ettiğini manual sayfalarındaki açıklamalara göz atarak öğrenebileceğiniz gibi zaten zaman içinde hangi aracın ne şekilde çalıştığını da anımsıyor olacaksınız. Örneğin kullandığınız aracın yardım sayfasında bu duruma dair bir açıklama yoksa standart girdiden veri yönlendirmeyi deneyip bizzat kendiniz de test edebilirsiniz.
Benim yönlendirmelerle ilgili bahsetmek istediklerim şimdilik bu kadar. Bence temel eğitim için bu kadarlık detay seviyesi yeterli. Tabii ki eğer isterseniz daha fazlasını öğrenmek için araştırma yapmakta özgürsünüz.
Biz şimdi metinsel veriler üzerinde çalışmamıza yardımcı olan temel araçlardan bahsederek devam edelim.
cat Komutucat aracının ismi “bağlamak, birleştirmek veya sıralamak” anlamlarında olan İngilizce “concatenate” kelimesinden geliyor ve aracın görevini net biçimde ifade ediyor aslında.
cat komutunun en temel işlevi, kendisine argüman olarak verilen dosyaların içeriklerini konsola yönlendirerek bastırmaktır. Yani aslında temelde cat aracı dosyaların içeriklerini konsol üzerinden okuyabilmemize olanak tanıyan basit bir araçtır. Var olan bir dosyayı okumak için tek yapmamız gereken, cat komutunun ardından dosyanın ismini girmek. Ben örnekler sırasında kullanmak için mevcut bulunduğum dizindeki dosya ve klasör isimlerini bir dosyaya kaydetmek istiyorum. Bunun için ls > liste komutunu girebilirim. Buradaki büyüktür > yönlendirme operatörü sayesinde ls komutunun çıktıları “liste” dosyasına yönlendirilmiş olacak. Bir de ls /usr > liste2 komutu ile “usr” dizini altındakileri de “liste2” dosyasına kaydedelim.
┌──(taylan@linuxdersleri)-[~]
└─$ ls > liste
┌──(taylan@linuxdersleri)-[~]
└─$ ls /usr > liste2
Örneğin oluşturduğumuz ikinci dosyanın içeriğini konsola bastırmak istersek cat liste2 şeklinde komutumuzu girebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ cat liste2
bin
games
include
lib
lib32
lib64
libexec
libx32
local
sbin
share
src
Bakın dosyanın içeriği konsola bastırıldı. Dilersek, aynı anda birden fazla dosyayı da okuyabiliriz. Denemek için diğer dosyanın ismini de girelim.
┌──(taylan@linuxdersleri)-[~]
└─$ cat liste2 liste
bin
games
include
lib
lib32
lib64
libexec
libx32
local
sbin
share
src
ada
calısma
Desktop
Documents
dosya.txt
Downloads
hatalı.txt
hatasız2.txt
hatasız.txt
klasor
liste
metin1.txt
metin2.txt
Music
Pictures
Public
sonuc
Templates
test.sh
Videos
yeni
yeni klasor
yepyenidosya
Bakın komutta soldan sağa doğru verdiğim tüm dosyaların içerikleri, sırasıyla yukarıdan aşağıya doğru konsola bastırılmış oldu. Yani aslında isminde olduğu şekilde cat aracı birden fazla dosyanın içeriğini sırasıyla birleşik şekilde konsolumuza bastırmış oldu. Bu şekilde istediğimiz kadar dosyanın birleştirilmesini sağlayabiliyoruz.
Birden fazla dosya içeriğinin cat aracı sayesinde sıralı şekilde birleştirilebiliyor olması size bir fikir verdi mi ?
Eğer istersek birden fazla dosyanın içeriğini tek bir dosyaya yönlendirebiliriz. Yani birden fazla dosyayı tek bir dosyada birleştirebiliriz. Denemek için “liste” ve “liste2” dosyasını birleştirip “nihai-liste” isimli bir dosya oluşturmak üzere cat liste liste2 > nihai-liste şeklinde komutumuzu girelim.
┌──(taylan@linuxdersleri)-[~]
└─$ cat liste liste2 > nihai-liste
┌──(taylan@linuxdersleri)-[~]
└─$ cat nihai-liste
ada
calısma
Desktop
Documents
dosya.txt
Downloads
hatalı.txt
hatasız2.txt
hatasız.txt
klasor
liste
metin1.txt
metin2.txt
Music
Pictures
Public
sonuc
Templates
test.sh
Videos
yeni
yeni klasor
yepyenidosya
bin
games
include
lib
lib32
lib64
libexec
libx32
local
sbin
share
src
Bakın iki dosyanın içeriği, tam olarak komutta belirttiğim sıralama ile yani ilk olarak “liste” dosyası daha sonra “liste2” dosyası olacak şekilde birleştirilip tek bir dosya haline gelmiş oldu.
İşte cat komutunun en temel ve sık kullanılan özellikleri bunlar. Zaten daha önce yönlendirmeleri kullanarak yeni dosyalar oluşturup içerisine nasıl veri ekleyebileceğimizden defaatle uygulamalı olarak söz ettiğimiz için cat komutu ile söyleyeceğim ek bir detay bulunmuyor.
Bu bölüme gelene kadar gerçekleştirdiğimiz anlatımlar sırasında kullanma sıklığımızdan da tahmin edebileceğiniz gibi cat komutu en sık kullanacağımız komutların başında geliyor. cat aracı hatırlanması ve kullanımı basit ancak metinsel verileri okuma birleştirme ve yenilerini oluşturma gibi en temel konularda etkili bir araç. cat komutunu kullanarak ihtiyaçlarınıza uygun çözümler üretmek tamamen sizin yönlendirmeleri ve cat komutunun çalışma yapısını ne kadar iyi anladığınıza bağlı. Daha iyi anlamak adına birkaç örnek yapabiliriz.
Örneğin cat aracını bir dosyanın içeriğini kopyalamak için kullanabiliriz mesela. Bunun için cat kopyalanacak_dosya > dosyanın_kopyası şeklinde komut girmemiz yeterli oluyor. “liste” dosyasını kopyalamak istersem cat liste > liste3 komutuyla bu dosya içeriğinin “liste3” isimli dosyaya kopyalanmasını sağlayabilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ cat liste > liste3
┌──(taylan@linuxdersleri)-[~]
└─$ cat liste3
ada
calısma
Desktop
Documents
dosya.txt
Downloads
hatalı.txt
hatasız2.txt
hatasız.txt
klasor
liste
metin1.txt
metin2.txt
Music
Pictures
Public
sonuc
Templates
test.sh
Videos
yeni
yeni klasor
yepyenidosya
Bakın “liste” dosyasının içeriği kopyalanarak “liste3” isimli dosya oluşturulup bu dosyaya aktarılmış.
Burada gerçekleşen işlemi temel olarak açıklamamız gerekirse; Girmiş olduğumuz komut sayesinde cat aracı kopyalanacak dosyanın içeriğini okuyor ve buradaki büyüktür > işareti sayesinde bu içeriği standart çıktıya yönlendiriyor. Normalde biz özellikle belirtmediğimiz sürece standart çıktı bizim konsolumuza bağlı olduğu için biz cat aracının çıktılarını konsolda görüyoruz. Ama ben burada standart çıktıyı büyüktür operatörü ile “liste3” isimli dosyaya yönlendirdiğim için çıktılar bu dosyaya aktarılıyor. Bu sayede “liste” dosyasının içeriğiyle aynı içeriğe sahip “liste3” isimli dosya oluşturuluyor. Yani bir nevi “liste” dosyasını kopyalamış oluyoruz.
Elbette benim ele aldığım temel kullanımı dışında cat komutunun daha birçok seçeneği mevcut. Bu seçeneklere göz atmak için cat —help komutunu kullanabilirsiniz. Buradaki help çıktısındaki açıklamalar yeterince açık gelmezse, internet üzerindeki rehber anlatımlara da kolaylıkla ulaşabilirsiniz. Zaten tüm eğitim boyunca tekrar ettiğim ve edeceğim gibi, bu eğitimdeki amacım temel kavramlardan bahsedip daha fazlasını nasıl öğrenebileceğimiz üzerinde durmak. Dolayısıyla tüm konulardan, tüm araçlardan veya araçların tüm seçeneklerinden bahsetmemi bekliyorsanız, üzgünüm bu gerçekleşmeyecek. Nitekim anlatıcı tarafında olmama karşın benim de henüz bilmediğim, hiç kullanmadığım için unuttuğum veya hiç karşılaşmadığım pek çok konu, kavram, araç ve seçenek bulunuyor. Bildiğimi sandıklarım, bilmediklerimin yanında bir hiç sayılır. Ancak temel kavramların farkında olduğumuzda ve yeni bilgileri nasıl araştırıp bulabileceğimizi bildikten sonra zaten zaman içinde bilmemiz gereken kadarlık bilgi birikimini adım adım inşa edebiliyoruz. Yani özetle önemli olan iyi bir temel ve bu temele dayandırılan araştırma yetkinliği kazanabilmek. Zira öğrenmek sürecimiz hiç bir zaman bitmeyecek.
Anlatımlarımıza gelin cat komutunu tersi şekilde çıktılar sunabilen tac aracından bahsederek devam edelim.
tac KomutuHatırlıyorsanız, ls komutunu ele alırken tüm çıktıları tersine çevirebilen “reverse” yani “r” seçeneğinden bahsetmiştik. cat komutu ile okuduğumuz dosya içerikleri için de benzer bir ihtiyacımız olabilir. Örneğin cat komutu ile okuduğumuz bir dosya içindeki alfabetik olarak sıralanmış satırlara, ters alfabetik olarak ihtiyaç duyabiliriz. Bu durumda, cat aracının ismen de tersi olan tac aracını kullanabiliyoruz.
tac komutunu test edebilmek için öncelikle yeni bir dosya oluşturalım. Ben bulunduğum dizindeki tüm içerikleri ayrıntılarıyla birlikte büyükten küçüğe doğru okunaklı şekilde sıralayıp, çıktıları “liste.txt” isimli bir dosyaya aktarmak istiyorum. Bunun için ls -lhS > liste.txt şeklinde komutumu giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ ls -lhS > liste.txt
┌──(taylan@linuxdersleri)-[~]
└─$ cat liste.txt
total 104K
drwxr-xr-x 2 taylan taylan 4.0K Jun 7 07:41 ada
drwxr-xr-x 2 taylan taylan 4.0K Jun 7 08:45 calısma
drwxr-xr-x 4 taylan taylan 4.0K Jun 5 13:33 Desktop
drwxr-xr-x 5 taylan taylan 4.0K Jun 4 07:06 Documents
drwxr-xr-x 3 taylan taylan 4.0K May 26 05:36 Downloads
drwxr-xr-x 2 taylan taylan 4.0K Jun 7 06:22 klasor
drwxr-xr-x 2 taylan taylan 4.0K Feb 11 2022 Music
drwxr-xr-x 4 taylan taylan 4.0K May 30 13:21 Pictures
drwxr-xr-x 3 taylan taylan 4.0K Jun 25 2022 Public
drwxr-xr-x 2 taylan taylan 4.0K Feb 11 2022 Templates
drwxr-xr-x 2 taylan taylan 4.0K Feb 11 2022 Videos
drwxr-xr-x 2 taylan taylan 4.0K Jun 7 06:22 yeni
drwxr-xr-x 2 taylan taylan 4.0K Jun 7 06:23 yeni klasor
-rw-r--r-- 1 taylan taylan 278 Jun 11 05:26 nihai-liste
-rw-r--r-- 1 taylan taylan 208 Jun 11 05:22 liste
-rw-r--r-- 1 taylan taylan 208 Jun 11 05:32 liste3
-rw-r--r-- 1 taylan taylan 161 Jun 10 11:57 sonuc
-rw-r--r-- 1 taylan taylan 70 Jun 11 05:23 liste2
-rw-r--r-- 1 taylan taylan 68 Jun 10 11:59 yepyenidosya
-rw-r--r-- 1 taylan taylan 43 Jun 10 11:37 hatalı.txt
-rwxr-xr-x 1 taylan taylan 37 Jun 10 11:23 test.sh
-rw-r--r-- 1 taylan taylan 25 Jun 10 11:34 hatasız2.txt
-rw-r--r-- 1 taylan taylan 25 Jun 10 11:31 hatasız.txt
-rw-r--r-- 1 taylan taylan 24 Jun 7 07:45 metin2.txt
-rw-r--r-- 1 taylan taylan 22 Jun 7 08:01 dosya.txt
-rw-r--r-- 1 taylan taylan 16 Jun 7 07:42 metin1.txt
-rw-r--r-- 1 taylan taylan 0 Jun 11 06:46 liste.txt
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın dosya ve dizinlerin büyükten küçüğe doğru sıralanmış listesini görebiliyoruz. Eğer aynı dosyayı tac komutu ile okursak listenin tam tersi şekilde olması gerekiyor.
┌──(taylan@linuxdersleri)-[~]
└─$ tac liste.txt
-rw-r--r-- 1 taylan taylan 0 Jun 11 06:46 liste.txt
-rw-r--r-- 1 taylan taylan 16 Jun 7 07:42 metin1.txt
-rw-r--r-- 1 taylan taylan 22 Jun 7 08:01 dosya.txt
-rw-r--r-- 1 taylan taylan 24 Jun 7 07:45 metin2.txt
-rw-r--r-- 1 taylan taylan 25 Jun 10 11:31 hatasız.txt
-rw-r--r-- 1 taylan taylan 25 Jun 10 11:34 hatasız2.txt
-rwxr-xr-x 1 taylan taylan 37 Jun 10 11:23 test.sh
-rw-r--r-- 1 taylan taylan 43 Jun 10 11:37 hatalı.txt
-rw-r--r-- 1 taylan taylan 68 Jun 10 11:59 yepyenidosya
-rw-r--r-- 1 taylan taylan 70 Jun 11 05:23 liste2
-rw-r--r-- 1 taylan taylan 161 Jun 10 11:57 sonuc
-rw-r--r-- 1 taylan taylan 208 Jun 11 05:32 liste3
-rw-r--r-- 1 taylan taylan 208 Jun 11 05:22 liste
-rw-r--r-- 1 taylan taylan 278 Jun 11 05:26 nihai-liste
drwxr-xr-x 2 taylan taylan 4.0K Jun 7 06:23 yeni klasor
drwxr-xr-x 2 taylan taylan 4.0K Jun 7 06:22 yeni
drwxr-xr-x 2 taylan taylan 4.0K Feb 11 2022 Videos
drwxr-xr-x 2 taylan taylan 4.0K Feb 11 2022 Templates
drwxr-xr-x 3 taylan taylan 4.0K Jun 25 2022 Public
drwxr-xr-x 4 taylan taylan 4.0K May 30 13:21 Pictures
drwxr-xr-x 2 taylan taylan 4.0K Feb 11 2022 Music
drwxr-xr-x 2 taylan taylan 4.0K Jun 7 06:22 klasor
drwxr-xr-x 3 taylan taylan 4.0K May 26 05:36 Downloads
drwxr-xr-x 5 taylan taylan 4.0K Jun 4 07:06 Documents
drwxr-xr-x 4 taylan taylan 4.0K Jun 5 13:33 Desktop
drwxr-xr-x 2 taylan taylan 4.0K Jun 7 08:45 calısma
drwxr-xr-x 2 taylan taylan 4.0K Jun 7 07:41 ada
total 104K
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın tam olarak beklediğimiz gibi tüm çıktılar tam tersi şekilde oldu. Yani tüm satırları ters sıralama ile küçükten büyüye olacak şekilde görüntüleyebildik. İşte tac komutu tam olarak bu amaçla kullanılıyor. Satırları sondan başa doğru bastırmak istediğimizde tac aracını kullanabiliyoruz.
Belki bu örnekte kullandığımız ls komutunun zaten kendine ait terse çevirme işlevi yani -r seçeneği olduğu için, tac komutunun kullanımı size çok gerekli gibi gelmemiş olabilir ancak lütfen buradaki ls komutuna takılmayın. ls sadece kolay gözlemlenebilir dosya içeriği oluşturmak için kullandığımız basit bir örnek. Komut satırını kullanırken, sürekli metinsel veriler üzerinde çalıştığımız için, herhangi bir dosyadaki verilerin tersten sıralamasına ihtiyaç duyacağımız durumlar ile karşılaşmamız kaçınılmaz. Komut satırında çalışırken temelde her şeyi bayt akışından ibaret olduğunu unutmayın lütfen. Dosya içeriklerinden veya çeşitli araçlardan gelen verileri yani üzerinde çalıştığımız baytları istediğimiz doğrultuda manipüle edebildiğimiz sürece komut satırının gücünden faydalanabiliriz. Verileri manipüle etmenin önemini ileride daha iyi anlayacaksınız. Çünkü eğitimin devamında, pipe mekanizmasını kullanarak bir aracın ürettiği çıktıları başka bir araca yönlendirerek kompleks sorunlara basit çözümler sağlamış olacağız. Araçların bir arada çalışabilmesi için de gerektiğine akış halindeki verilerin bir sonraki araca uygun şekilde değiştirilerek aktarılması gerekecek. Özetle, verileri istediğimiz şekilde değiştirebiliyor olmanın önemini ileride daha net anlayacaksınız.
Ayrıca ben tek bir dosya ile örnek yaptım ama cat komutunda olduğu gibi tac komutuyla da birden fazla dosyayı aynı anda ters sıralama ile okuyabiliriz. Ben örnek olarak sırala harfler ve sayılar içeren iki dosya oluşturmak istiyorum. Kolayca oluşturmak için daha önce öğrendiğimiz süslü parantez genişletmesini kullanabiliriz. a’dan z’ye kadar olan karakterleri echo -e "\n"{a..z} > harf.txt komutu ile “harf.txt” dosyasına kaydedebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ echo -e "\n"{a..z} > harf.txt
Buradaki echo komutu ile kullandığımız -e seçeneği tırnak içinde yazdığımız “yeni satıra geçme” yani “\n” ifadesinin çalışmasını sağlıyor. Bu sayede a’dan z’ye kadar her satıra bir karakter basılıyor. Merak etmeyin echo komutunu kullanırken bu konudan tekrar bahsedeceğiz. Şimdilik ihtiyacımız olan dosyayı oluşturmak için kullanabiliriz. Benzer şekilde 1’den 30’a kadar olan sayıları satır satır sıralamak için de komutumuzu echo -e "\n"{1..30} > sayi.txt şeklinde düzenleyip girebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ echo -e "\n"{1..30} > sayi.txt
Evet neticede içinde istediğimiz türde veriler bulunan iki dosyamızı kolayca oluşturabildik. İçeriklerini görüntülemek için aynı anda iki dosyayı da cat komutu ile açabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ echo -e "\n"{1..30} > sayi.txt
┌──(taylan@linuxdersleri)-[~]
└─$ cat harf.txt sayi.txt
a
b
c
d
e
f
g
h
i
j
k
l
m
n
o
p
q
r
s
t
u
v
w
x
y
z
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
Bakın, verdiğim dosya sırlamasına uygun şekilde tek seferde dosya içerikleri sıralı şekilde bastırıldı. Aynı dosyaları tac komutu ile de bastırabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ tac harf.txt sayi.txt
z
y
x
w
v
u
t
s
r
q
p
o
n
m
l
k
j
i
h
g
f
e
d
c
b
a
30
29
28
27
26
25
24
23
22
21
20
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
Bakın yine verdiğim dosya sırlamasına uygun ancak bu kez dosya içerikleri tersten sıralanmış şekilde bastırıldı.
tac komutu cat komutu kadar kolay hatırlanabilir basit bir komut. cat komutunun tersten yazılmış hali olması zaten işlevi hakkında unutulmaz bir hatırlatıcı.
rev KomutuEğer mevcut satırların sırlanmasını değil de doğrudan satırdaki karakterleri tersine çevirmek istersek rev aracını kullanabiliyoruz. rev aracının ismi İngilizce “reverse” yani “ters” ifadesinin kısaltmasından geliyor. Kullanımı son derece kolay, rev komutunun ardından satırlarındaki karakterlerini tersine çevirmek istediğiniz dosyayı yazmanız yeterli oluyor.
Nasıl bir etkisi olduğunu test etmek için hemen basit bir metin dosyası oluşturmayı deneyebiliriz. Ben bunun için cat > metin.txt komutunu girip dosyamın içine birkaç satır veri ekliyorum.
cat > metin.txt
bu basit
bir metin
dosyasıdır
Veri girişini sonlandırıp dosyaya kaydetmek için Ctrl + d tuşlamasını yapmamız yeterli.
Aradaki farkı net gözlemleyebilmek için oluşturduğumuz dosyayı hem cat hem de rev araçları ile okumayı deneyebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ cat metin
bu basit
bir metin
dosyasıdır
┌──(taylan@linuxdersleri)-[~]
└─$ rev metin
tisab ub
nitem rib
rıdısaysod
Görebildiğiniz gibi rev aracı tüm satırlardaki karakterler tersine çeviriyor. Yani tek tek tüm satırlarda yer alan sondaki karakter başa, baştaki de sona gidecek şekilde bir terslik elde edebildik.
touch KomutuEğer hatırlıyorsanız, daha önce yeni boş dosyalar oluşturmak üzere touch aracını kullanmıştık. Bu işlevinin yanında aslında touch aracı var olan dosyaların tarih bilgilerini değiştirmek için kullanılan bir araç.
Daha önce ls komutunun ayrıntılı çıktılarında ve bu çıktıları tarihlere göre sıralarken zaten dosya ve klasörlerin tarih bilgisinin tutulduğunu söylemiştik.
Şimdi özellikle bu konu üstünde duracak olursak sistem üzerinde oluşturulan tüm dosyaların oluşturulma, değiştirilme ve güncellenme tarihleri olmak üzere temelde üç zaman etiketi bulunuyor. Biz istersek touch aracı sayesinde bu tarihleri değiştirebiliyoruz.
Fakat öncelikle bu bilgileri görmek için stat komutunu kullanalım. stat komutu sayesinde dosya ve dizinler hakkında çeşitli öznitelik bilgilerini görüntüleyebiliyoruz. Ben test edebilmek için daha önce oluşturduğum “liste” isimli dosyanın özelliklerine bakmak istiyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ stat liste
File: liste
Size: 208 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 2893400 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ taylan) Gid: ( 1000/ taylan)
Access: 2023-06-11 05:24:30.303662486 -0400
Modify: 2023-06-11 05:22:23.199246609 -0400
Change: 2023-06-11 05:22:23.199246609 -0400
Birth: 2023-06-11 05:22:23.195248608 -0400
Buradaki erişim(access) tarihi, bu dosyanın en son açıldığı, okunduğu yani erişildiği tarihi veriyor. Fakat bir dosya pek çok kullanıcı tarafından defaatle açılabileceği ve özellikle sunucularda dosya okunma sayısının yüksek olması dolayısıyla bu erişim tarihi her erişimde değişmiyor. Her erişimde değişecek şekilde konfigüre edebiliriz fakat disk üzerindeki okuma yazma yükünü yüksek oranda artıracağımız için pek de makul bir yaklaşım sayılmaz. Bu sebeple bir dosyayı açıp okuduğunuzda erişim tarihi muhtemelen hemen değişmeyecektir. Değişiyorsa, o sistem bunun için özellikle konfigüre edilmiştir.
Diğer tarih bilgisine bakacak olursak, düzenleme tarihi, dosya içeriğinin değiştirilmiş olduğu tarihi veriyor. Örneğin yeni bir veri eklediyseniz veya var olan verileri sildiyseniz dosyanızın düzenlenme tarihi değişiyor. Ben denemek için echo “yeni veri” >> liste komutu ile dosyama yeni bir veri ekleyip, stat liste komutu ile tarih bilgisine tekrar bakmak istiyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "yeni veri" >> liste
┌──(taylan@linuxdersleri)-[~]
└─$ stat liste
File: liste
Size: 218 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 2893400 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ taylan) Gid: ( 1000/ taylan)
Access: 2023-06-11 05:24:30.303662486 -0400
Modify: 2023-06-11 10:15:07.265088731 -0400
Change: 2023-06-11 10:15:07.265088731 -0400
Birth: 2023-06-11 05:22:23.195248608 -0400
Bakın düzenleme(modify) tarihi düzenlemeyi yaptığımız tam tarih olarak değişmiş. Ayrıca bakın burada değişim(change) tarihinin de aynı şekilde değiştiğini görebiliyoruz.
Değişim tarihi de değişti çünkü buradaki değişim tarihi bilgisi, dosyanın ismi, yetkisi, boyutu gibi çeşitli öznitelikleri değiştiğinde güncelleniyor. Biz dosyanın içine yeni veri ekleyip dosyanın boyutunu değiştirdiğimiz için bu “değişim” tarihi de güncellenmiş oldu.
Dolayısıyla bir dosyanın içeriğini değiştirirseniz hem düzenleme hem de değişme tarihi değişiyor. Fakat yalnızca dosyanın ismi, konumu veya yetkileri gibi özniteliklerini değiştirdiğinizde sadece değişme tarihi güncelleniyor. Bu durumu teyit etmek için dosyamızı mv komutu ile aynı dizinde yeni bir isimle kaydedebiliriz. Yani dosyamızın ismini değiştirmeyi deneyebiliriz. Bunun için mv liste yeni-liste şeklinde komutumuzu girebiliriz. Burada mv komutundan sonra girdiğim ilk argüman taşınacak dosyayı ikincisi ise hangi dizine taşınacağını belirtiyor. Ben harici olarak ekstra bir dizin adresi belirtmediğim için göreli yol gereği mevcut dizinde burada belirttiğim isimde kaydedilecek.
┌──(taylan@linuxdersleri)-[~]
└─$ mv liste yeni-liste
┌──(taylan@linuxdersleri)-[~]
└─$ stat yeni-liste
File: yeni-liste
Size: 228 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 2893400 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ taylan) Gid: ( 1000/ taylan)
Access: 2023-06-11 05:24:30.303662486 -0400
Modify: 2023-06-11 10:29:21.455971533 -0400
Change: 2023-06-11 10:36:40.927598070 -0400
Birth: 2023-06-11 05:22:23.195248608 -0400
Bakın dosyayı taşıyarak ismini değiştirdiğimiz için yalnızca değişme(change) tarihi güncellenmiş. Dosya içeriğinde düzenleme yapmadığımız için düzenleme tarihinde bir değişiklik yok.
Temel tarih bilgileri ve bunların değişme koşulları bizzat burada örnekler üzerinden teyit ettiğimiz şekilde çalışıyor. Ayrıca çıktılara dikkat edecek olursanız burada dosyanın oluşturulma tarihi de mevcut. Bu bilgi tüm dosya sistemlerinde desteklenmediği için tüm sistemlerde göremeyebilirsiniz. Yine de güncel mimariye sahip bir sistemde çalışıyorsanız yeni dosya sistemleri dolayısıyla dosyanın oluşturulma tarihi de tutuluyordur mutlaka.
Neticede bakın benim sürekli öznitelik olarak bahsetmiş olduğum bu meta veriler üzerinden dosya hakkında çeşitli tarih bilgilerini öğrenebiliyoruz. Sistem yönetimi sırasında özellikle sırlama ve denetleme gibi işlevleri yerine getirirken bu bilgilerden faydalanabiliyoruz.
touch komutu da erişim ve düzenleme tarihlerinin doğrudan değiştirilmesi konusunda bize yardımcı oluyor.
Örneğin ben dosyanın erişim tarihini güncellemek istersem “access” yani “erişim” ifadesinin kısaltmasından gelen a seçeneği ile touch -a dosya ismi şeklinde dosyanın erişim tarihini şimdiki tarih ile değiştirebilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ stat yeni-liste
File: yeni-liste
Size: 228 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 2893400 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ taylan) Gid: ( 1000/ taylan)
Access: 2023-06-11 05:24:30.303662486 -0400
Modify: 2023-06-11 10:29:21.455971533 -0400
Change: 2023-06-11 10:36:40.927598070 -0400
Birth: 2023-06-11 05:22:23.195248608 -0400
┌──(taylan@linuxdersleri)-[~]
└─$ touch -a yeni-liste
┌──(taylan@linuxdersleri)-[~]
└─$ stat yeni-liste
File: yeni-liste
Size: 228 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 2893400 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ taylan) Gid: ( 1000/ taylan)
Access: 2023-06-11 10:41:09.213674288 -0400
Modify: 2023-06-11 10:29:21.455971533 -0400
Change: 2023-06-11 10:41:09.213674288 -0400
Birth: 2023-06-11 05:22:23.195248608 -0400
Bakın erişim tarihi bu komutu girdiğim zaman olarak değişmiş.
Benzer şekilde yalnızca düzenlenme tarihini değiştirmek istiyorsam “modify” ifadesinin kısaltmasından gelen m seçeneğini de kullanabilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ stat yeni-liste
File: yeni-liste
Size: 228 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 2893400 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ taylan) Gid: ( 1000/ taylan)
Access: 2023-06-11 10:41:09.213674288 -0400
Modify: 2023-06-11 10:29:21.455971533 -0400
Change: 2023-06-11 10:41:09.213674288 -0400
Birth: 2023-06-11 05:22:23.195248608 -0400
┌──(taylan@linuxdersleri)-[~]
└─$ touch -m yeni-liste
┌──(taylan@linuxdersleri)-[~]
└─$ stat yeni-liste
File: yeni-liste
Size: 228 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 2893400 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ taylan) Gid: ( 1000/ taylan)
Access: 2023-06-11 10:41:09.213674288 -0400
Modify: 2023-06-11 10:56:52.024845155 -0400
Change: 2023-06-11 10:56:52.024845155 -0400
Birth: 2023-06-11 05:22:23.195248608 -0400
Bakın düzenlenme tarihi de tam olarak komutu girdiğim tarih ile değişmiş.
Eğer biz komutu girdiğimiz sıradaki mevcut tarih yerine spesifik bir tarih belirtmek istersek “date” ifadesinin kısaltmasından gelen -d seçeneğini kullanarak tam tarih bilgisini yazmamız gerekiyor.
Ben denemek için 2015 yılının 1 haziran gününde saat tam 12:33’te hem erişim hem de düzenleme tarihi olarak tanımlamak istediğim için komutumu touch -d "2015-06-01 12:33:00" yeni-liste şeklinde giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ touch -d "2015-06-01 12:33:00" yeni-liste
┌──(taylan@linuxdersleri)-[~]
└─$ stat yeni-liste
File: yeni-liste
Size: 228 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 2893400 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ taylan) Gid: ( 1000/ taylan)
Access: 2015-06-01 12:33:00.000000000 -0400
Modify: 2015-06-01 12:33:00.000000000 -0400
Change: 2023-06-11 11:02:12.749127535 -0400
Birth: 2023-06-11 05:22:23.195248608 -0400
Bakın hem erişim hem de düzenlenme tarihi değişmiş.
Eğer ikisini birden değiştirmek istemezsek bunu özellikle ilgili seçenek sayesinde belirtebiliriz. Ben yalnızca düzenlenme saatini değiştirmek istediğim için -d seçeneğinden önce “m” seçeneğini de ekliyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ touch -md "2016-06-01 12:33:00" yeni-liste
┌──(taylan@linuxdersleri)-[~]
└─$ stat yeni-liste
File: yeni-liste
Size: 228 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 2893400 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ taylan) Gid: ( 1000/ taylan)
Access: 2015-06-01 12:33:00.000000000 -0400
Modify: 2016-06-01 12:33:00.000000000 -0400
Change: 2023-06-11 11:05:39.816609760 -0400
Birth: 2023-06-11 05:22:23.195248608 -0400
Bakın bu kez de yalnızca düzenlenme tarihi tam olarak benim belirtmiş olduğum tarih olarak değişmiş oldu.
İşte touch aracının en temel kullanımı bu şekilde. Yani artık touch aracının yalnızca boş dosya oluşturmak için değil, aslında tarih bilgilerini düzenlemek için kullanıldığını biliyoruz. Tarih değişimine pek ihtiyaç duymasanız da ihtiyaç duyduğunuzda bu aracın kullanımını anımsıyor olacaksınız. Zaten kullanımı çok basit olduğu için seçenekleri unutmuş olsanız bile touch —help komutuyla kontrol edebilirsiniz.
echo KomutuDaha önce örneklerimizde echo komutunu sıklıkla kullandık. “echo” “eko” ifadesi sizin de bildiğiniz gibi Türkçe olarak “yankılanmak, yansıtmak” anlamına geliyor. Zaten komutun işlevi de tam olarak bu. Kendisine argüman olarak verilenleri konsola veya yönlendirildiği yere yansıtıyor. En basit haliyle echo komutundan sonra yazacağımız tüm ifadeler, echo tarafından konsola bastırılıyor. Ben örnek olarak echo merhabalar yazıyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ echo merhabalar
merhabalar
┌──(taylan@linuxdersleri)-[~]
└─$
Gördüğünüz gibi “merhabalar” çıktısı konsola basıldı. Dilersek konsola bastırmak yerine herhangi bir dosyaya da yönlendirebiliriz. Örneğin echo "hello" > hello.txt komutunu girersem, hello ifadesi hello.txt dosyasına yazılmış olacak. Zaten daha önce de echo komutunu bu şekilde yönlendirmelerle birlikte kullanmıştık.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "hello" > hello.txt
┌──(taylan@linuxdersleri)-[~]
└─$ cat hello.txt
hello
Bakın dosyamız oluşturulmuş ve içerisine “hello” verisi de eklenmiş.
Ayrıca echo komutunu yalnızca tek satırlık veriler için kullanmak zorunda da değiliz. Eğer yazacaklarımız birden fazla satır tutacaksa, tırnak işaretini kapatmadan satır satır, yazmak istediklerimizi yazabiliyoruz. Ben denemek için açtığım tırnağı kapatmadan birden fazla satırda veriler ekleyip, en son gireceklerim bittiğinde açtığım tırnağı kapatıp enter ile komutumu onaylıyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "bu ilk
> bu ikinci
> bu uc
> bu ise son satır"
bu ilk
bu ikinci
bu uc
bu ise son satır
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın tırnağı kapatana kadar girmiş olduğum tüm veriler, aynen girdiğim şekilde konsola bastırılmış oldu.
Eğer konsola bastırmak yerine bu yazdıklarımı bir dosyaya yönlendirmek istersem tırnağı kapattıktan sonra yönlendirme operatörü ile ilgili dosyayı belirtip enter ile işlemi onaylayabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "bu ilk
bu ikinci
bu uc
bu ise son satır" > satırlar
┌──(taylan@linuxdersleri)-[~]
└─$ cat satırlar
bu ilk
bu ikinci
bu uc
bu ise son satır
Gördüğünüz gibi > yönlendirme operatörü sayesinde echo komutuna birden fazla satırda girmiş olduğum verileri “satırlar” isimli dosyaya sorunuzca aktarmış oldum.
echo komutunun çıktılarını bir dosyaya sorunsuzca yönlendirebildik ancak daha önce de bizzat deneyimlediğimiz gibi echo komutunun standart girdiden veri okumadığına tekrar dikkatinizi çekmek istiyorum. Bu durumu tekrar teyit etmek istersek, örneğin biraz önce echo komutu ile içine satırlar eklediğimiz “satırlar” dosyasını echo komutu aracılığı ile konsola bastırmak üzere echo < sonuclar şeklinde komutumuzu girebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ echo < satırlar
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın, gördüğünüz gibi konsola herhangi bir çıktı basılmadı. Çünkü echo komutu standart girdiden veri okumuyor. Biz göndersek de echo komutu standart girdiden veri kabul etmediği için echo komutuna aslında yankılayabileceği hiç bir argüman vermiş olmuyoruz. Dolayısıyla konsola hiç bir veri bastırılamıyor. echo komutu çalışma yapısı gereği yalnızca kendisine argüman olarak verilmiş olan ifadeleri konsola yankılıyor yani bastırıyor.
Zaten help echo komutu ile yardım sayfasına göz atacak olursanız, yardım bilgisinin en üstünde echo komutunun argümanları standart çıktıya yazdırdığı açıkça yazıyor.
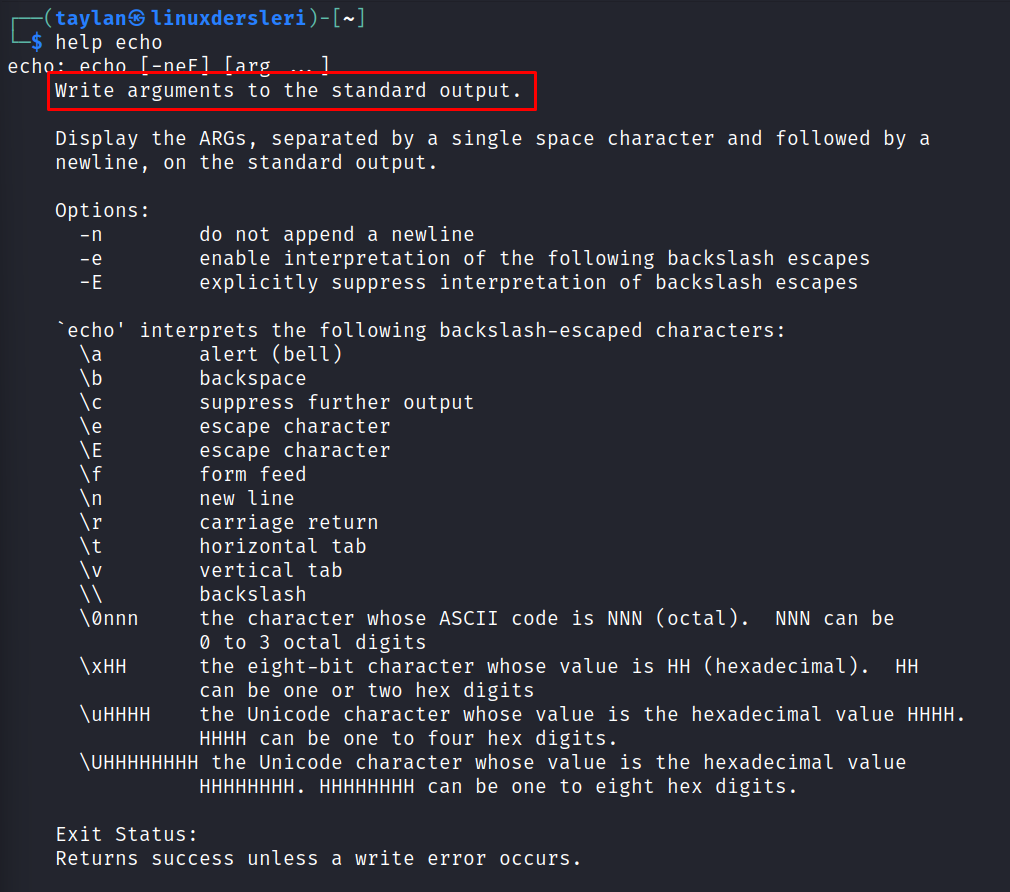
Ayrıca gördüğünüz gibi standart girdiden veri kabul ettiğine dair herhangi bir açıklama da bulunmuyor. Burada kast edilen argüman yapısının ne olduğunu zaten biliyorsunuz.
Özetle echo yalnızca kendisine argüman olarak aktarılanları standart çıktı aracılığı ile konsola veya özellikle belirtildiyse başka bir hedefe yönlendirmekle mükellef bir araç. Eğer hatırlıyorsanız, ben yönlendirmelerden bahsederken kimi araçların standart girdiden veri almayabileceğinden de bahsetmiştim. İşte echo aracı da bahsi geçen bu araçlardan biri. Kimi araçlar yalnızca argümanları işlemek için tasarlandıklarından, standart girdiden veri kabul etmiyorlar.
Hatta echo komutunun yalnızca argümanları yankıladığına dair basit bir örnek vermek gerekirse echo * komutunu kullanabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ echo *
ada calısma Desktop Documents dosya.txt Downloads harf.txt hatalı.txt hatasız2.txt hatasız.txt hello.txt klasor liste2 liste3 liste.txt metin metin1.txt metin2.txt Music nihai-liste Pictures Public satırlar sayi.txt sonuc Templates test.sh Videos yeni yeni klasor yeni-liste yepyenidosya
Biliyorsunuz buradaki yıldız * işareti kabuk için tüm dosya ve dizin isimleriyle eşleşen bir genişletme karakteri. Dolayısıyla bu karakterin olduğu yere kabuk tarafından mevcut dosya ve dizin isimlerinden uygun olan tüm karakterler getirilebiliyor. Kabuk echo komutunu gördüğünde bu aracı çalıştırması gerektiğini anlıyor, daha sonra yıldız simgesini görüyor. Yıldız işareti bash kabuğu için dosya ismi genişletmesi anlamına geldiği için kabuğumuz bu genişletmeyi uyguluyor. Yani yıldız işretinin yerini, mevcut dizindeki dosya ve klasörlerin isimleri alıyor. Dolayısıyla echo komutuna da argüman olarak dosya ve dizinlerin isimleri verilmiş oluyor. echo komutu da argümanlarını konsola çıktı olarak yansıtıyor yani standart çıktılarını konsola yönlendiriyor.
İşte sizlerin de görebildiği gibi, kabuğun çalışma yapısını ve temel özelliklerini bildiğimizde, bu örnekte olduğu gibi komut verme konusunda inanılmaz esnekliğe sahip olabiliyoruz. Ben sadece dikkat çekici bir örnek olması için tekrar bu örneği ele aldım.
Tıpkı bu örnekte olduğu gibi echo komutu da dahil tüm komutların pek çok esnek kullanım imkanları var. Yeter ki biz temelde nasıl çalıştıklarını bilelim.
Ayrıca şu ana kadar ele aldığımız kullanımlar dışında echo komutun pek çok ek seçeneği bulunuyor. Bunları görmek için tekrar help echo komutunu kullanabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ help echo
echo: echo [-neE] [arg ...]
Write arguments to the standard output.
Display the ARGs, separated by a single space character and followed by a
newline, on the standard output.
Options:
-n do not append a newline
-e enable interpretation of the following backslash escapes
-E explicitly suppress interpretation of backslash escapes
`echo' interprets the following backslash-escaped characters:
\a alert (bell)
\b backspace
\c suppress further output
\e escape character
\E escape character
\f form feed
\n new line
\r carriage return
\t horizontal tab
\v vertical tab
\\ backslash
\0nnn the character whose ASCII code is NNN (octal). NNN can be
0 to 3 octal digits
\xHH the eight-bit character whose value is HH (hexadecimal). HH
can be one or two hex digits
\uHHHH the Unicode character whose value is the hexadecimal value HHHH.
HHHH can be one to four hex digits.
\UHHHHHHHH the Unicode character whose value is the hexadecimal value
HHHHHHHH. HHHHHHHH can be one to eight hex digits.
Exit Status:
Returns success unless a write error occurs.
Bakın burada pek çok özel karakter bulunuyor. Hepsine tek tek değinmemize gerek yok. Ama kısaca bir göz atalım.
Normalde echo komutunun ardından yazdığımız ifade konsola doğrudan bastırılıyor.
┌──(taylan@linuxdersleri)-[~]
└─$ echo merhaba
merhaba
┌──(taylan@linuxdersleri)-[~]
└─$ echo merhaba
merhaba
┌──(taylan@linuxdersleri)-[~]
Burada dikkat etmemiz gereken detay, aslında bizim girdiğimiz ifadeden sonra echo komutunun otomatik olarak yeni satıra geçme karakteri gizlice kullanıyor olması. Bu durumu teyit etmek için otomatik olarak yeni satıra geçme özelliğini kapatmak üzere -n seçeneğini kullanabiliriz. n seçeneği “newline” yani “yeni satır” ifadesinin kısaltmasından geliyor. Bu şekilde aklınızda daha kolay kalabilir.
┌──(taylan@linuxdersleri)-[~]
└─$ echo -n merhaba
merhaba
┌──(taylan@linuxdersleri)-[~]
└─$
Önceki çıktı ile kıyaslayacak olursanız bir alt satıra geçilmediğini teyit edebilirsiniz. Böylelikle echo komutunun aslında, gizli “yeni satır” eklediğini öğrenmiş olduk. Elbette yardım sayfası üzerinde de görebildiğimiz gibi echo aracının pek çok biçimlendirme özelliği bulunuyor.
Kısaca bu biçimlendirme özelliklerinden de bahsedecek olursak. echo aracı, ters slash \ ile başlayan ifadeleri gördüğünde onların özel anlamlarına göre çıktıyı biçimlendiriyor. Fakat bu ifadeleri doğrudan kullanamıyoruz. Bu biçimlendirme ifadelerini kullanırken echo komutunun -e seçeneğini kullanarak, echo komutuna bu karakterlere özel anlamlarına göre dikkate alaması gerektiğini özellikle belirtmemiz şart. Aksi halde buradaki ifadeleri kullansak bile bunlar echo komutu için sıradan karakterlerden ibaret olacak. Hemen deneyelim. Ben yeni satıra geçmeyi sağlayan \n ifadesini kullanacağım. Komutumu echo "merhaba \n dünya" şeklinde giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ echo "merhaba \n dünya"
merhaba \n dünya
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın çıktılarda \n ifadesi de yazdığımız şekilde duruyor ve yeni bir satıra da geçilmemiş. Aynı örneğini bu kez -e seçeneği varken tekrar deneyelim.
┌──(taylan@linuxdersleri)-[~]
└─$ echo -e "merhaba \n dünya"
merhaba
dünya
┌──(taylan@linuxdersleri)-[~]
└─$
Bakın bu kez \n ifadesi echo komutu tarafından dikkate alındı ve ikinci kelimemiz bir alt satırda bastırıldı. Dikkat ettiyseniz tırnak içinde yazdım. Çünkü biçimlendirme özelliklerinin doğru şekilde çalışması için tırnak içinde yazmamız gerekiyor. Daha önce tek ve çift tırnak kullanımı arasındaki farklardan bahsetmiştik. Bu doğrultuda tek veya çift tırnak kullanma seçimi size ait.
Ayrıca hatırlıyorsanız daha önce echo komutunu ve süslü parantez genişletmelerini kullanarak sıralı karakterleri alt alta olacak şekilde biçimlendirmiştik. Şimdi tekrar aynı komutu kullanıp sonuçlarına bakabiliriz. Aynı örneği gerçekleştirmek için echo -e "\n"{a..z} komutunu girelim.
┌──(taylan@linuxdersleri)-[~]
└─$ echo -e "\n"{a..z}
a
b
c
d
e
f
g
h
i
j
k
l
m
n
o
p
q
r
s
t
u
v
w
x
y
z
Bakın echo komutunun -e seçeneğinden ve \n şeklinde yazılan yeni satır biçimlendirme özelliğinden faydalanmış olduk. Etkisini görmek için aynı örneği \n olmadan da test edebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ echo -e {a..z}
a b c d e f g h i j k l m n o p q r s t u v w x y z
Bakın yeni satıra geçme karakteri olmayınca tüm veriler aynı satırda bastırıldı. Bu örnek bu biçimlendirme karakterlerinin gerektiğinde oldukça kullanışlı olabildiğini gösteren çok basit bir örnek.
İşte sizler de benim bu örnek üzerinden ele aldığım gibi, yardım sayfasında yer alan diğer tüm biçimlendirme özelliklerini -e seçeneği ile birlikte echo komutu üzerinden kullanabilirsiniz.
Buradaki seçeneklerin hepsini ezberlemek zorunda değilsiniz. Hatta hiç birini ezberlemeyin. Çünkü ezberlemeniz gerekmiyor, kullandıkça bu ifadeleri zaten hatırlıyor olacaksınız. Hatırlayamadığınız zaman yardım sayfasından kısa sürede tekrar bakabilirsiniz. Zaten kısaltmaların, temsil ettiği biçimlendirme özellikleri ile uyumlu olduğunu da göz önünde bulundurduğumuzda, pratik yaptıkça sık kullandığınız seçeneklerin hemen aklınıza geldiğini sizler de fark edeceksiniz. Ayrıca buradaki biçimlendirme ifadeleri, çoğu araçta benzer şekilde olduğundan bir kez öğrendiğinizde sistem üzerindeki metin biçimlendirme araçların pek çoğunda aynı ifadeleri kullanabiliyor olacaksınız.
Yani özetle benim bahsetmediğim diğer seçeneklerin açıklamasına bakarak, tam olarak nasıl bir biçimlendirme uyguladığını bizzat test etmeniz yeterli. Hem bu sayede pratik yapmış olursunuz.
paste Komutuİleride dosya içeriklerini değiştirip dosyaların değişimlerini kıyaslamak için yan yana bastırmak istediğimiz örneklerle karşılaşacağımız için ilk olarak paste aracından bahsetmek istedim. Normalde cat komutu ile birden fazla dosyayı okurken dosyaların içerikleri peşi sıra alt alta bastırılıyorken, paste aracı ile bu çıktıların yan yana bastırılmasını sağlayabiliriz. Yani cat aracı satırların birleştirilmiş çıktılarını üretirken, paste aracı sütunların birleştirilmiş çıktılarını sunuyor.
Ben denemek için önceden oluşturduğum “şehir” “harf” ve “rakam” isimli dosyaları yan yana bastırmak istiyorum. Ama bundan önce cat komutu ile farkını daha rahat gözlemleyebilmek adına bu dosyaları okumak üzere cat harf sehir rakam komutunu girelim.
┌──(taylan@linuxdersleri)-[~]
└─$ cat harf sehir rakam
a
b
c
d
e
f
istanbul
Ankara
İzmir
bursa
antayla
Kocaeli
1
2
3
4
5
6
Bakın tam da beklediğimiz gibi tüm dosyalardaki satırlar alt alta birleşik halde bastırıldı. Şimdi bunları yan yana bastırmak için paste harf sehir rakam şeklinde komutumuz tekrar girelim.
┌──(taylan@linuxdersleri)-[~]
└─$ paste harf sehir rakam
a istanbul 1
b Ankara 2
c İzmir 3
d bursa 4
e antayla 5
f Kocaeli 6
Bakın bu kez dosyalardaki satırlar üç farklı sütunda yan yana bastırılmış oldu. paste aracının bize sunduğu kolaylık tam olarak bu.
Burada dosya içeriklerinin kolay ayırt edilebilmesi için sütunlar arasında boşluklar yer alıyor. Fakat dilersek, bastırılan sütunlar arasında boşluk yerine özel bir işaret yani özel bir sınırlayıcı karakter de ekleyebiliriz. Örneğin ben her bir sütun arasına kısa dikey çizgi eklemek istiyorum. paste aracına sütunları nasıl ayıracağını belirtmek için de İngilizce “delimiter” yani “sınırlayıcı” ifadesinin kısalmasından gelen -d seçeneğinin ardından sınırlayıcı karakteri yazabiliriz.
Ben sınırlayıcı olarak dikey çizgiyi kullanmak istediğim için komutumuz paste -d "|" harf sehir rakam şeklinde giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ paste -d "|" harf sehir rakam
a|istanbul|1
b|Ankara|2
c|İzmir|3
d|bursa|4
e|antayla|5
f|Kocaeli|6
Bakın, tüm sütunların arasında dikey çizgi yer alıyor, çünkü ben sınırlayıcı karakter olarak buradaki dik çizgi karakterini tanımlamıştım. Tabii ki sizler dilediğiniz bir karakteri sınırlayıcı olarak kullanabilirsiniz. Hatta birden fazla sınırlayıcı karakter de belirtebilirsiniz. Örneğin dikey çizgi ve kısa çizgi karakterlerini sınırlayıcı olarak kullanırsak, sırasıyla iki sınırlayıcı da dosya içeriklerini sınırlamak için kullanılıyor olacak. Bu durumu daha net gözlemeyebilmek adına daha fazla dosyayı yan yana bastırsak daha iyi olur. Ben aynı dosyaları tekrar tekrar yan yana bastırmak istiyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ paste -d "|-" harf sehir rakam sehir harf rakam
a|istanbul-1|istanbul-a|1
b|Ankara-2|Ankara-b|2
c|İzmir-3|İzmir-c|3
d|bursa-4|bursa-d|4
e|antayla-5|antayla-e|5
f|Kocaeli-6|Kocaeli-f|6
Bakın, gördüğünüz gibi sırasıyla hem dikey çizgi hem de kısa çizgi karakterleri sütunlar arasındaki sınırlayıcı olarak kullanılmış. İşte sizler de bu şekilde sütunları istediğiniz sınırlayıcı karakterle birbirinden ayırabilirsiniz. Birden fazla sınırlayıcı belirttiğimizde tıpkı burada aldığımız çıktıda da olduğu gibi bu karakterler sırasıyla soldan sağa doğru tekrar eden bir örüntü gibi kullanılıyor olacak. İhtiyacınız doğrultusunda tek ve birden fazla sınırlayıcı karakter belirtebilirsiniz. Hatta sınırlayıcı olarak tırnak içinde hiç bir karakter belirtmezseniz doğrudan boşluk olmadan dosyaların birbirine yapıştırılmasını da sağlayabilirsiniz.
┌──(taylan@linuxdersleri)-[~]
└─$ paste -d "" harf sehir rakam
aistanbul1
bAnkara2
cİzmir3
dbursa4
eantayla5
fKocaeli6
Bakın, dosyalardaki tüm satırlar aralarında boşluk olmadan sütunlarda birleştirilmiş. Tıpkı bu örnekte olduğu gibi ihtiyacınıza yönelik şekilde sınırlayıcı karakter belirtmekte özgürsünüz.
Ayrıca sınırlama işareti dışında eğer her bir satırı yan yana değil de alt alta eşleşecek şekilde sıralamak istersek -s seçeneğini de kullanabiliyoruz.
┌──(taylan@linuxdersleri)-[~]
└─$ paste -s harf sehir rakam
a b c d e f
istanbul Ankara İzmir bursa antayla Kocaeli
1 2 3 4 5 6
Görebildiğiniz gibi normalde satırlar yan yana basılırken şimdi dosyalardaki her bir satır alt alta gelmiş şekilde basılmış oldu.
Sizler ihtiyacınıza göre paste aracını kullanarak istediğiniz sayıda dosyanın satırlarını birebir yan yana ya da alt alta birleştirebilirsiniz. Eğer birden fazla dosya içeriğinin yan yana birleştirilmiş hali lazımsa komutunuzun sonuna yönlendirme işareti ekleyip çıktıları yeni bir dosya olarak kaydedebilirsiniz. Ben en son girdiğim komutun sonuna > paste-sonucları ekleyip çıktıları dosyaya kaydediyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ paste -s harf sehir rakam > paste-sonucları
┌──(taylan@linuxdersleri)-[~]
└─$ cat paste-sonucları
a b c d e f
istanbul Ankara İzmir bursa antayla Kocaeli
1 2 3 4 5 6
Bakın çıktılar dosyama kaydolmuş. Neticede paste aracını kullanarak mevcut dosyaları yan yana veya dikey olarak nasıl birleştirebileceğimizi de ele almış olduk. Ayrıca ben yönlendirmek için tek büyüktür yine yeni bir dosya oluşturmayı tercih ettim ama siz diğer yönlendirme alternatiflerini biliyorsunuz.
Zaten artık hatırlatmama gerek yok. Sizler yönlendirmeler ile ilgili bilmeniz gereken tüm temel altyapıya sahipsiniz. İhtiyaçlarınıza göre sistem üzerinde tüm araçlarda kullanabilirsiniz. Özellikle veri bilimi gibi alanlarda çalışırken, bu şekilde birden fazla kaynaktan alınan verilerin istenildiği şekilde derlenebilmesi çok kullanışlı olabiliyor. Tüm mesele elimizdeki verileri ihtiyaçlarımıza göre düzenleyip kullanabilmek.
sort KomutuÖzellikle düzensiz haldeki büyük veriler üzerinde çalışıyorken sort gibi araçlar yardımıyla bu verileri düzenlememiz gerekebiliyor. Tahmin edebileceğiniz gibi zaten buradaki sort aracının ismi de Türkçe olarak “sıralamak-sınıflandırmak” ifadelerine karşılık geliyor.
sort aracı sayesinde elimizdeki düzensiz verileri, belirli özelliklere göre kolayca sınıflandırabiliyoruz.
sort aracının kullanılabilecek pek çok özelliği olmasına karşın, eğer herhangi bir seçenek belirtmeden doğrudan karışık satırları sort aracına iletirsek;
Öncelikle tüm satırlardaki ilk karakterlere bakıp sırasıyla sayılar, daha sonra harfler ve son olarak eğer aynı harfler varsa küçük harfler öncelikli olacak şekilde sıralanıyorlar. Ve bu sıralama işlemi tüm satırlardaki tüm karakterler sıralanıncaya kadar tekrar tekrar devam ediyor.
Yani ilk olarak tüm satırlardaki karakterlere bakılıp tüm satırlar buradaki kural dahilinde sıralanıyor. Daha sonra ilk karakteri aynı olan satırlar ikinci karaktere göre kendi içlerinde bir daha sıralanıyor ve bu işlem satırlardaki tüm karakterler bitine kadar bu şekilde gerçekleştiriliyor. Bu şekilde tüm satırlarda yer alan tüm karakterleri baştan sonra kendi standart kuralı dahilinde sıralamış oluyor.
Uygulamalı olarak daha net anlaşılacağı için hemen bir dosya üzerinde test edelim. Ben örnek olarak içerisinde küçük büyük harfler ve rakamlar bulunan bir şablon kullanacağım. Bakın benim kullanacağım şablon bu. İçerisinde düzensiz veriler bulunan bu şablonu kullanıyorum çünkü biraz önce bahsetmiş olduğumuz tüm sıralama kurallarını net biçimde görmemiz mümkün olacak.
┌──(taylan@linuxdersleri)-[~]
└─$ cat > sablon
b3
ba
B3
3B
a2
A1
a1
2a
1b
3b
Görebildiğiniz gibi kullanacağımız bu şablon, içerisinde küçük büyük harfler ve rakamlar bulunan son derece düzensiz bir içeriğe sahip. Şimdi bu dosyanın ismini sort komutundan sonra argüman olarak yapıp düzenli bir listenin nasıl göründüğüne bakalım.
┌──(taylan@linuxdersleri)-[~]
└─$ sort sablon
1b
2a
3b
3B
a1
A1
a2
b3
B3
ba
Aldığımız çıktıyı inceleyecek olursak. Bakın öncelikle tüm satırlardaki ilk karakterlere bakılmış ve bunlar sayısal olarak sıralanmış. Daha sonra alfabetik olarak sıralanmış. a karakteri b den önce geldiği için küçük büyük harf fark etmeksizin ilk harfinde a olan tüm satırlar ilk karakterinde b olanlardan önce sıralanmış. Alfabetik sıralamadan sonra da aynı karaktere sahip olan satırlarda küçük karakterler büyüklerden önce sıralanmış. Bu sebeple küçük a karakterleri büyüklerden önce geliyor. Fakat burada A1 satırı, başında küçük a olasına rağmen a2 den önce gelmiş.
a1
A1
a2
Bu durumun nedeni ikinci karakterdeki 2 rakamı aslında. sort aracı sıralama işlemini tüm karakterleri tek tek sıralayıp tekrar tekrar sıralama yaptığı için bu şekilde çıktı aldık. Yani aslında sort aracı tıpkı bu örneğimizde olduğu gibi öncelikle sırasıyla tek tek karakterlere bakarak sıralama yapıyor olsa da tüm karakterlerin kendisine göre hesapladığı ağırlık değerlerine göre yeniden sıralanmasını sağlıyor.
Yani aslında sort aracı ilk turda yalnızca buradaki ilk karaktere bakarak listeyi şu şekilde sıralıyor.
1b
2a
3b
3B
a1
a2
A1
b3
ba
B3
Daha sonra sıra ikinci karaktere bakmaya geliyor. Bu durumda ilk karakteri aynı olanları ikinci karaktere bakarak sıralıyor. Buradaki A1 satırındaki 1 rakamı, a2 satırındaki 2 rakamından küçük olduğu için daha fazla öncelik kazanıyor. Dolayısıyla baştaki a karakterinin büyük küçük olması bu sıralamayı değiştirmiyor.
İlk örneğimizde tek bir dosyadaki satırları sıraladık ancak dilersek birden fazla dosyayı da tek seferde sort komutu ile sıralayabiliriz. Hem bu sayede birden fazla dosya içeriğini sıralı şekilde birleştirmiş oluruz. Tıpkı cat komutun olduğu gibi ancak bu veriler sıralanmış olacak.
Ben denemek için cat > sayi komutuyla yeni bir dosya açıp buna düzensiz veriler giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ cat > sayi
10
4
6
2
21
95
3
3
75
8
1
01
40
Şimdi bir de düzensiz harfler oluşturmak üzere cat > harf komutunun ardından rastgele karakterleri girelim.
┌──(taylan@linuxdersleri)-[~]
└─$ cat > harf
a
g
F
z
D
g
O
p
l
k
S
C
E
n
M
h
t
N
Şimdi her iki dosyamızın ismini de argüman olarak verip aynı anda sıralamasını sağlayalım.
┌──(taylan@linuxdersleri)-[~]
└─$ sort sayi harf
01
1
10
2
21
3
3
4
40
6
75
8
95
a
C
D
E
F
g
g
h
k
l
M
n
N
O
p
S
t
z
Gördüğünüz gibi dosyalar birleştirilip ortak şekilde sıralanmış oldu. Öncelikle rakamlar, daha sonra küçük karakter önce olacak şekilde alfabetik sıralama gerçekleştirilmiş. Ama sanki aldığımız çıktı biraz tuhaf gibi. Normalde sayıların sıralanması deyince çoğu kişinin aklına iki basamaklıklar da dahil tüm hepsinin küçükten büyüğe doğru sıralanması gerektiği geliyor. Ama önceki açıklamalarımıza dikkat ettiyseniz sort komutu her bir satırın yalnızca tek bir karakterini sıralıyor. Dolayısıyla sıralama yapılırken aslında sayılar değil 0 dan 9 a kadar olan rakamlar arasında sıralama yapılıyor. Buradaki ilk karakter olan yani ilk basamakta yer alan tüm rakamlar zaten matematiksel olarak küçükten büyüğe doğru sıralanmış. İlk karakterler sıralandıktan sonra da ilk karakteri yani ilk basamağı aynı olan rakamların da ikinci basamakları kendi içlerinde tekrar sıralanmış.
Yani aldığımız çıktıda herhangi bir problem yok. sort komutu buradaki sayıların bütüncül matematiksel büyüklüğüne bakmıyor, tek tek her bir satırdaki birer karakterlere bakıp ona göre sıralıyor.
Eğer dosya içeriğinin matematiksel büyüklüğü dikkate alınarak sıralansın istersek bunu “numerical” yani “sayısal” ifadesin kısaltması olan -n seçeneği ile özellikle belirtmemiz gerekiyor. Şimdi “sayi” dosyasını -n seçeneğini de kullanarak tekrar sıralayalım.
┌──(taylan@linuxdersleri)-[~]
└─$ sort -n sayi
01
1
2
3
3
4
6
8
10
21
40
75
95
Bakın bu kez dosya içeriğindeki veriler matematiksel büyüklüklerine göre sıralandı. Yani eğer sayısal sıralama yapacaksınız n seçeneğini kullanmanız gerektiğini unutmayın lütfen. Ya da unutun, tekrar yardım sayfasına bakıp hatırlayabilirsiniz zaten. Sadece yeri gelmişken bahsetmek istedim.
Eğer sort komutunun sıraladığı satırları tersine çevirmek istersek, “reverse” yani “ters” ifadesinin kısaltması olan “r” seçeneğini kullanabiliyoruz.
Rahatça kıyaslayabilmek için öncelikle seçenek olmadan sort komutunu kullanalım.
┌──(taylan@linuxdersleri)-[~]
└─$ sort sayi
01
1
10
2
21
3
3
4
40
6
75
8
95
Şimdi de -r seçeneğini ekleyip tersten sıralayalım.
┌──(taylan@linuxdersleri)-[~]
└─$ sort -r sayi
95
8
75
6
40
4
3
3
21
2
10
1
01
Bakın iki çıktıyı kıyasladığımızda, satırların tam tersi şekilde sıralandığını görebiliyoruz.
Elbette dilersek n seçeneğiyle de birlikte kullanabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ sort -n sayi
01
1
2
3
3
4
6
8
10
21
40
75
95
┌──(taylan@linuxdersleri)-[~]
└─$ sort -nr sayi
95
75
40
21
10
8
6
4
3
3
2
1
01
Sizde bu seçenek sayesinde elinizdeki verileri ters alfabetik ya da ters numerik şekilde sıralayabilirsiniz.
sort komutu en baştan başlayıp tüm satırlardaki karakterleri tek tek sıralıyor. Fakat biz her zaman satırların en başındaki karaktere bakılmasını istemeyebiliriz. Yalnızca her satırın en başındaki karaktere göre sıralama yapmak yerine eğer mevcutsa, diğer sütunlara göre sıralama yapılmasını da sağlayabiliriz.
Örnek olarak isimler ve yaşları içeren bir şablon kullanabiliriz.
ahmet 21
mehmet 44
Ayse 24
adnan 43
Nil 20
naz 29
Eğer seçenek kullanmadan yalnızca sort komutunu kullanırsak, en baştaki karakterlere göre sıralanacak.
┌──(taylan@linuxdersleri)-[~]
└─$ sort veri
adnan 43
ahmet 21
Ayse 24
mehmet 44
naz 29
Nil 20
Bakın çıktılar ilk sütundaki ilk karakterlere göre sıralandı.
Şimdi sort komutuna yalnızca 2. sütuna bakarak sıralama yapmasını söyleyelim. Bunun için “k” seçeneğini kullanabiliyoruz. Hangi sütuna göre sıralanacağını belirtmek için “k” seçeneğinden sonra sütun sayısını girmemiz gerekiyor. Ben 2. sütuna göre sıralanmasını ve matematiksel büyüklüğe göre sıralanmasını istediğim için komutumu sort -nk 2 dosya adı şeklinde giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ sort -nk 2 veri
Nil 20
ahmet 21
Ayse 24
naz 29
adnan 43
mehmet 44
Gördüğünüz gibi girmiş olduğum “k” seçeneği sayesinde bu kez 2. sütuna yani yaş sayılarına göre sıralama yapıldı. İşte sizler de içerisinde birden fazla sütun bulunan bu gibi dosyaların, hangi sütunlarına göre sıralanması gerektiğini “k” seçeneği ile özellikle belirtebilirsiniz.
Eğer sort komutuna verilen girdide birbirini tekrar eden satırlar varsa bunları teke indirebiliriz. sort komutunda bu filtrelemeyi uygulamak için İngilizce “unique” yani “benzersiz” ifadesinin kısaltması olan “u” seçeneğini kullanabiliyoruz.
Ben denemek için basit bir isim soyisim listesi kullanacağım.
Ahmet Yılmaz
Ayşe Demir
Cemal Özkan
Mustafa Öztürk
Fatma Kaya
Ali Can
Zeynep Aksoy
Hasan Şahin
Ahmet Şen
Emine Akgün
Mustafa Aydın
Hatice Türkmen
İbrahim Karaca
Esra Özdemir
Melek Akyüz
Murat Çelik
Seda Kaya
Cemal Özkan
Hatice Yıldız
Ahmet Şen
Leyla Koçak
Mustafa Yılmaz
Melek Akyüz
Bakın burada isim kısmı aynı olan satırlar ve isim soy isim aynı olan satırlar var. sort -u komutunu çalıştırıp nasıl bir çıktı elde edeceğimize bakalım.
┌──(taylan@linuxdersleri)-[~]
└─$ sort -u liste
Ahmet Şen
Ahmet Yılmaz
Ali Can
Ayşe Demir
Cemal Özkan
Emine Akgün
Esra Özdemir
Fatma Kaya
Hasan Şahin
Hatice Türkmen
Hatice Yıldız
İbrahim Karaca
Leyla Koçak
Melek Akyüz
Murat Çelik
Mustafa Aydın
Mustafa Öztürk
Mustafa Yılmaz
Seda Kaya
Zeynep Aksoy
Bakın isimler kısmı aynı olmasına rağmen satırlar basıldı. Fakat birebir aynı olan satırlar yani isim ve soy isimin aynı olduğu satırlardan yalnızca bir tanesi basıldı. Gördüğünüz gibi bu şekilde birebir tekrar eden satırları u seçeneği ile tek bir satır basılacak şekilde sıralayabiliyoruz.
sort komutunun tüm seçenekleri benim bahsettiklerimle sınırlı da değil. Burada ele aldıklarımız dışında sort komutunun birkaç özelliği daha bulunuyor. Ancak ben geri kalan özelliklerden, başka araçları kullanarak da faydalanabileceğimizi bildiğim için sort komutunu için bu kadarlık bilginin yeterli olduğunu düşünüyorum. Merak ediyorsanız sort —help komutunun çıktılarına göz atabilirsiniz.
shuf Komutushuf aracının ismi İngilizce “shuffle” yani “karıştırmak” ifadesinden geliyor.
shuf aracı sayesinde mevcut satırların rastgele olacak şekilde karıştırılmasını sağlayabiliyoruz. Ben örnek olması için echo -e “\n”{1..10} > liste1 komutu ile 1’den 10’a kadar alt alta sayıları dosyaya kaydediyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ echo -e "\n"{1..10} > liste1
┌──(taylan@linuxdersleri)-[~]
└─$ cat liste1
1
2
3
4
5
6
7
8
9
10
Eğer ben bu dosyamın satır sıralamalarını karıştırmak istersem shuf komutunu kullanabilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ shuf liste1
6
1
7
9
3
2
8
5
4
10
Bakın bu kez rastgele sıralanmış şekilde satırlar bastırıldı. Komutumuzu her kullandığımızda, gördüğünüz gibi satırların sıralaması rastgele olacak şekilde karıştırılıyor.
┌──(taylan@linuxdersleri)-[~]
└─$ shuf liste1
1
8
5
6
10
7
4
3
2
9
Tabii ki biz özellikle yönlendirme yapmadığımız sürece buradaki karıştırma işlemi kaynak dosyayı etkilemiyor. shuf komutu kaynak dosyadan okuyup karıştırdığı satırları konsolumuza bastırıyor. Yani orijinal dosyada bir değişiklik olmuyor. Teyit etmek için tekrar cat komutu ile “liste1” dosyamızı okuyabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ cat liste1
1
2
3
4
5
6
7
8
9
10
Bakın dosyanın içeriğinde herhangi bir değişiklik olmamış. Çünkü dediğim gibi shuf komutu yalnızca okuduğu satırları rastgele karıştırıp standart çıktıya yönlendiriyor. Eğer biz bu karışık listeyi bir dosyaya kaydetmek istersek, yönlendirme operatörü ile istediğimiz bir dosyaya yönlendirebiliriz. Ben bunun için komutun sonuna > karisik.txt şeklinde ekliyorum ve paste komutu ile de orijinal ile karışık olanları yan yana bastırıyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ shuf liste1 > karisik.txt
┌──(taylan@linuxdersleri)-[~]
└─$ paste liste1 karisik.txt
3
1 8
2 5
3 9
4 10
5 6
6 7
7 2
8
9 4
10 1
Bakın kaynak dosyada hiç bir değişiklik yok ve yönlendirme operatörü sayesinde standart çıktıyı yönlendirdiğimiz “karisik.txt” dosyasının içeriği de istediğimiz gibi karışık satırlardan oluşuyor.
Bu basit kullanım dışında eğer isterseniz tüm satırlar yerine belirli sayıda satırların bastırılmasını da sağlayabilirsiniz. Örneğin ben 10 satırdan oluşan bu listenin karıştırılıp, yalnızca 3 satırın bana çıktı olarak verilmesini istiyorum. Bunun için “n” seçeneğinin ardından istediğim satır sayısını yazmam yeterli. Yani komutumuzu shuf -n 3 liste1 şeklinde girebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ shuf -n 3 liste1
8
9
2
Bakın rastgele 3 satır bastırıldı. Komutumu tekrar tekrar girdiğimizde, yalnızca 3 satır olacak şekilde rastgele satırların bastırıldığını görebiliyoruz.
┌──(taylan@linuxdersleri)-[~]
└─$ shuf -n 3 liste1
5
1
10
Neticede artık elinizdeki verileri karıştırmak istediğinizde shuf aracını nasıl kullanabileceğinizi biliyorsunuz. shuf aracının diğer seçeneklerini merak ediyorsanız shuf —help komutu ile yardım bilgisine göz atıp, kendiniz keşfedebilirsiniz.
nl KomutuEğer satırların başına satır numaralarını eklemek istersek “numbering line” yani “satır numaralandırma” ifadesinin kısalmasından gelen nl komutunu kullanabiliyoruz. Özellikle çok fazla verinin tek bir satıra sığdırıldığı yoğun içerikli dosyalarda içeriği daha rahat okuyabilmek için numaralandırma bize kolaylık sunabiliyor.
Ben denemek için daha önce oluşturmuş olduğum içerisinde isimler bulunan “liste” isimli dosyasını kullanacağım. Satırları numaralamak için nl liste şeklinde dosyamızın ismini argüman olarak verebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ nl liste
1 Ahmet Yılmaz
2 Ayşe Demir
3 Cemal Özkan
4 Mustafa Öztürk
5 Fatma Kaya
6 Ali Can
7 Zeynep Aksoy
8 Hasan Şahin
9 Ahmet Şen
10 Emine Akgün
11 Mustafa Aydın
12 Hatice Türkmen
13 İbrahim Karaca
14 Esra Özdemir
15 Melek Akyüz
16 Murat Çelik
17 Seda Kaya
18 Cemal Özkan
19 Hatice Yıldız
20 Ahmet Şen
21 Leyla Koçak
22 Mustafa Yılmaz
23 Melek Akyüz
24 MELEK AKYÜZ
25 mustafa Yılmaz
Bakın sırasıyla tüm satırların başında numara bulunuyor.
Ayrıca mesela eğer birden fazla dosyayı argüman olarak girersek, girdiğimiz argüman sıralamasına göre bu dosya içerikleri birleştirilip o şekilde numaralandırılıyor. Ben denemek için nl liste harf şeklinde iki tane dosya ismini giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ nl liste harf
1 Ahmet Yılmaz
2 Ayşe Demir
3 Cemal Özkan
4 Mustafa Öztürk
5 Fatma Kaya
6 Ali Can
7 Zeynep Aksoy
8 Hasan Şahin
9 Ahmet Şen
10 Emine Akgün
11 Mustafa Aydın
12 Hatice Türkmen
13 İbrahim Karaca
14 Esra Özdemir
15 Melek Akyüz
16 Murat Çelik
17 Seda Kaya
18 Cemal Özkan
19 Hatice Yıldız
20 Ahmet Şen
21 Leyla Koçak
22 Mustafa Yılmaz
23 Melek Akyüz
24 MELEK AKYÜZ
25 mustafa Yılmaz
26 a
27 g
28 F
29 z
30 D
31 g
32 O
33 p
34 l
35 k
36 S
37 C
38 E
39 n
40 M
41 h
42 t
43 N
Bakın öncelikle “liste” dosyasının içeriği daha sonra “harf” dosyasının içeriği birleştirilmiş ve birleşik şekilde bu satırlar numaralandırılmış. İşte nl aracını kullanarak satırları numaralandırmak bu kadar kolay.
nl komutunun da tıpkı diğer pek çok araç gibi elbette birden fazla ek seçeneği bulunuyor. Eğer nl —help komutunu kullanırsak, seçenekleri görebiliriz. Ancak açıkçası ben bu kadar seçenekle şu an ilgilenmiyorum. İleride gerekirse tekrar dönüp bakabilirim, yardım sayfaları bunun için var.
Ayrıca ben nl aracından özellikle bahsettim fakat aslında benim ihtiyacımı cat komutunun “n” seçeneği de yeterince iyi görüyor. Örneğin aynı dosyayı cat -n seçeneği ile de numaralandırabilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ cat -n liste
1 Ahmet Yılmaz
2 Ayşe Demir
3 Cemal Özkan
4 Mustafa Öztürk
5 Fatma Kaya
6 Ali Can
7 Zeynep Aksoy
8 Hasan Şahin
9 Ahmet Şen
10 Emine Akgün
11 Mustafa Aydın
12 Hatice Türkmen
13 İbrahim Karaca
14 Esra Özdemir
15 Melek Akyüz
16 Murat Çelik
17 Seda Kaya
18 Cemal Özkan
19 Hatice Yıldız
20 Ahmet Şen
21 Leyla Koçak
22 Mustafa Yılmaz
23 Melek Akyüz
24 MELEK AKYÜZ
25 mustafa Yılmaz
┌──(taylan@linuxdersleri)-[~]
└─$ cat -n liste harf
1 Ahmet Yılmaz
2 Ayşe Demir
3 Cemal Özkan
4 Mustafa Öztürk
5 Fatma Kaya
6 Ali Can
7 Zeynep Aksoy
8 Hasan Şahin
9 Ahmet Şen
10 Emine Akgün
11 Mustafa Aydın
12 Hatice Türkmen
13 İbrahim Karaca
14 Esra Özdemir
15 Melek Akyüz
16 Murat Çelik
17 Seda Kaya
18 Cemal Özkan
19 Hatice Yıldız
20 Ahmet Şen
21 Leyla Koçak
22 Mustafa Yılmaz
23 Melek Akyüz
24 MELEK AKYÜZ
25 mustafa Yılmaz
26 a
27 g
28 F
29 z
30 D
31 g
32 O
33 p
34 l
35 k
36 S
37 C
38 E
39 n
40 M
41 h
42 t
43 N
Peki madem cat komutu ile aynı işi yapabiliyoruz neden ek olarak nl komutunu ele aldık?
nl komutunu ele aldım, çünkü kullanımı ile sık karşılaşabilirsiniz. nl komutunu sunduğu ek özellikler için özellikle kabuk programlamada sıklıkla tercih ediliyor. Ben sadece sık kullanıldığı için nl komutundan da haberdar olmanızı istedim. Hangi iş için hangi komutu kullanacağınız tamamen sizin alışkanlıklarınıza bağlı. Aklınıza ilk nl komutu geliyorsa, bu aracı kullanabilirsiniz. Pek çok farklı aracın benzer özellikler için farklı seçenek tanımları bulunduğu için aslında nl gibi spesifik olarak tek bir işi yapan aracı bilmek bir avantaj. Zaten nl aracının ismi ana işlevini çağrıştırdığı için hatırlaması çok kolay. Bu sayede aynı özellik için farklı araçların farklı seçeneklerini hatırlamak yerine tek bir aracı hatırlayıp o iş için bu aracı kullanabiliyoruz. Elinizdeki verileri numaralandırmak mı istiyorsunuz, nl aracını kullanabilirsiniz.
wc Komutuwc aracı en temel haliyle kelimeleri saymamızı sağlayan işlevsel bir araçtır. wc komutunun ismi de “word count” yani “kelime sayma” ifadesinin kısaltmasından geliyor. Ben kelime dedim ama yalnızca kelimeleri değil, karakterleri, satırları ve ayrıca baytları saymak için de kullanabiliyoruz. Eğer ek bir seçenek olmadan wc aracına okuması gereken dosyayı argüman olarak verirsek, sırasıyla kaç satır, kelime ve karakter olduğunu ve okunan dosyanın ismini bastırıyor. Ben denemek isimleri ve soyisimleri içeren dosyam üzerinde kullanıyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ wc liste
25 50 333 liste
Buradaki ilk sayı dosya içeriğinin kaç satır olduğunu, ortadaki sayı toplam kaç kelime olduğunu ve son sayı ise toplam kaç karakter olduğunu bildiriyor.
İstersek bu çıktıların hepsini almak yerine yalnızca ihtiyacımız olan çıktıları da bastırabiliriz. Örneğin ben yalnızca satırların basılmasını istersem İngilizce “lines” yani “satırlar” ifadesinin kısaltması olan “l” seçeneğini kullanabilirim.
┌──(taylan@linuxdersleri)-[~]
└─$ wc -l liste
25 liste
Bakın bu kez yalnızca kaç satır olduğunu öğrendik. Bu arada dosya içeriğinde boş satırlar olduğunda bu satırların da sayıldığını da farkında olun.
Satır sayısı yerine kelime sayısını öğrenmek için de yine İngilizce karşılığı “word” yani “kelime” olan “w” seçeneğini kullanabiliyoruz.
┌──(taylan@linuxdersleri)-[~]
└─$ wc -w liste
50 liste
Bakın bu sefer de yalnızca kelime sayısı bastırıldı.
Yalnızca karakter sayısını öğrenmek istersek, c seçeneğini kullanabiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ wc -c liste
333 liste
Bakın yalnızca bayt sayısı da bastırmayı başardık.
Ayrıca tüm seçenekleri tek tek kullanabileceğimiz gibi elbette aynı anda da kullanabiliriz. Ancak dikkat etmeniz gereken detay, alacağınız çıktıların komutun en başında bahsettiğimiz standart sıralamasında olacağıdır. Yani seçenekleri hangi sıralamada vermiş olursak olalım, aldığımız çıktılar, soldan sağa doğru; satır, kelime, karakter sayısı ve dosya adı şeklinde olacak. Denemek için ben wc -wl liste şeklinde yani kelimelerin ve satırların hesaplanacağı şekilde komutumu giriyorum.
┌──(taylan@linuxdersleri)-[~]
└─$ wc -wl liste
25 50 liste
Şimdi birde seçeneklerin sıralamasını değiştirip tekrar girmeyi deneyelim.
┌──(taylan@linuxdersleri)-[~]
└─$ wc -lw liste
25 50 liste
Bakın iki çıktıdaki sayıların sıralaması da aynı. Yani bizim verdiğimiz seçenek sıralamasının wc komutu için bir önemi yok. Her koşulda, çıktılar kendi standartlarında, varsa satır daha sonra kelime sayısı ve son olarak karakter sayısını verecek şekilde oluyor oluyor.
Bu çıktı sıralamasını aklınızda tutamıyorsanız sorun yok. Çünkü man wc komutunu kullanıp, komut açıklamasındaki sıralama tanımına bakabilirsiniz. Ayrıca ben şimdiye kadar hep karakter uzunluğu dedim ama aslında kast ettiğim karakterlerin bayt uzunluğuydu. Zaten manual sayfalarında da bu sebeple “byte” şeklinde yazıyor. İyi ki yardım sayfaları var, haksız mıyım ?
Ayrıca ben şimdiye kadar hep tekil dosyalar üzerinden örnek verim fakat istersek birden fazla dosya ismi de belirtebiliriz.
┌──(taylan@linuxdersleri)-[~]
└─$ wc -lw liste harf
25 50 liste
17 18 harf
42 68 total
Bakın ayrı ayrı ve toplam şekilde tüm sonuçlar konsola bastırıldı. Bu şekilde ister tek isterseniz de birden fazla dosyanın istatistiklerini kontrol edebilirsiniz.
Ben şimdi daha fazla araçtan bahsetmeden önce pipe yapısından bahsedip, araçlar arasında nasıl veri yönlendirmesi yapabileceğimizi ele almak istiyorum.

Mevcut bölümü uygulamalı şekilde takip edip bitirdikten sonra buradaki pratik testleri çözmek, öğrenme düzeyinizi ve eksiklerinizi fark etmenizi sağlayabilir. Bu sebeple lütfen bir sonraki bölüme geçmeden önce, buradaki soruları yanıtlayın.
İlişkili Video
Mevcut doküman ile ilişkili olan Youtube videosu.

